Spark SQL中RDDs转化为DataFrame(详细全面)
除了调用SparkSesion.read().json/csv/orc/parqutjdbc 方法从各种外部结构化数据源创建DataFrame对象外,Spark SQL还支持
将已有的RDD转化为DataFrame对象,但是需要注意的是,并不是由任意类型对象组成的RDD均可转化为DataFrame 对象,
只有当组成RDD[T]的每一个T对象内部具有公有且鲜明的字段结构时,才能隐式或显式地总结出创建DataFrame对象所必要的
结构信息(Schema) 进行转化,进而在DataFrame上调用RDD所不具备的强大丰富的API,或执行简洁的SQL查询。
Spark SQL支持将现有RDDS转换为DataFrame的两种不同方法,其实也就是隐式推断或者显式指定DataFrame对象的Schema。
1.使用反射机制( Reflection )推理出schema (结构信息)
第一种将RDDS转化为DataFrame的方法是使用Spark SQL内部反射机制来自动推断包含特定类型对象的RDD的schema
(RDD的结构信息)进行隐式转化。采用这种方式转化为DataFrame对象,往往是因为被转化的RDDIT]所包含的T对象本身就
是具有典型-一维表严格的字段结构的对象,因此Spark SQL很容易就可以自动推断出合理的Schema这种基于反射机制隐式
地创建DataFrame的方法往往仅需更简洁的代码即可完成转化,并且运行效果良好。
Spark SQL的Scala接口支持自动将包含样例类( case class对象的RDD转换为DataFrame对象。在样例类的声明中 已预先定义
了表的结构信息,内部通过反射机制即可读取样例类的参数的名称、类型,转化为DataFrame对象的Schema.样例类不仅可以
包含Int、Double、String这样的简单数据类型,也可以嵌套或包含复杂类型,例如Seq或Arrays.
注意SparkContext是RDD的编程的主入口,SparkSession是SparkSQL的主入口,SparkSession初始化时,Sparkcontext
和SparkConf也会实例化,可有SparkSession调用。

以下将含有Person的样例类对象的RDD隐式转化为DataFrame对象的实例:
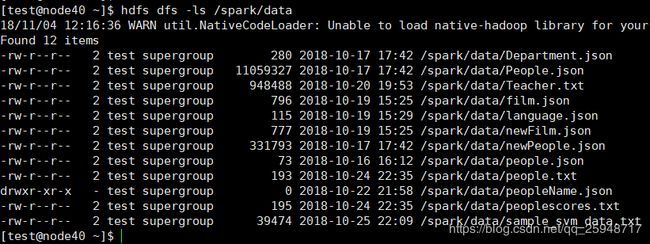
首先声明Person样例类,Person类对象用于装载name,age
case class Person(name:String,age:Long)
导入隐式类
import spark.implicits._
创建RDD
val personRDD = sparkSession.sparkContext.textFile("/spark/data/people.txt").map(_.split(" ")).map(attributes=>Person(attributes(0), attributes(1).trim.toInt))
转化为DataFrame
val peopleDF = personRDD .toDF()
2.由开发者指定Schema
RDD转化DataFrame的第二种方法是通过编程接口,允许先构建个schema,然后将其应用到现有的RDD(Row),较前一种方法
由样例类或基本数据类型 (Int、String) 对象组成的RDD加过toDF ()直接隐式转化为DataFrame不同,不仅需要根据需求、以及
数据结构构建Schema,而且需要将RDD[TI转化为Row对象组成的RDD (RDD[Row]),这种方法虽然代码量一些,但也提供了更高
的自由度,更加灵活。
当case类不能提前定义时(例如数据集的结构信息已包含在每一行中、一个文本数据集的事段对不同用户来说需要被解析成不同
的字段名),这时就可以通过以下三部完成Dataframe的转化
(1)根据需求从源RDD转化成RDD of rows.
(2)创建由符合在骤1中创建的RDD中的Rows结构的StructType表示的模式。
(3)通过SparkSession提供的createDataFrame方法将模式应用于行的RDD.
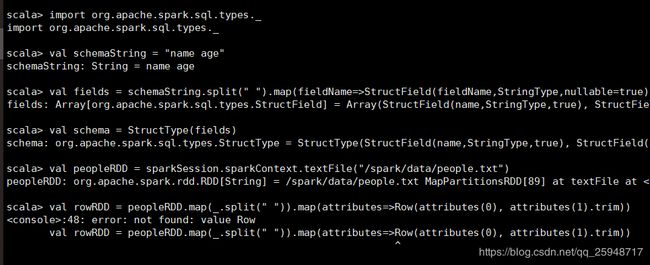
然后:val peopleDF = spark.createDataFrame(rowRDD,schema)