Deep Residual Learning for Weakly-Supervised Relation Extraction翻译
摘要
深度残差学习(ResNet)是一种新的方法,该方法使用恒等映射进行快捷连接来训练非常深的神经网络。ResNet赢得了ImageNet ILSVRC 2015分类任务,并在许多计算机视觉任务中取得了最先进的性能。但是,残差学习对具有噪音的自然语言处理任务的影响仍未得到很好的理解。在本文中,我们设计了一种带有残差学习的新型卷积神经网络,并研究了其对远程监督噪声关系抽取任务的影响。与ResNet仅适用于非常深的网络的普遍观点相反,我们发现即使使用9层的CNN,使用恒等映射也可以显着提高远程监督关系抽取的性能。
1.介绍
关系抽取是预测句子中实体的属性和关系的任务。 例如,给定一句 “ B a r a c k O b a m a w a s b o r n i n H o n o l u l u , H a w a i i . ” “Barack~Obama~was~born~in~Honolulu, Hawaii.” “Barack Obama was born in Honolulu,Hawaii.”,关系分类器旨在预测 “ b o r n I n C i t y ” “bornInCity” “bornInCity”的关系。关系抽取是构建关系知识图的关键组件,对于自然语言处理应用(例如结构化搜索,情感分析,问题回答和摘要)具有至关重要的意义。
关系抽取的主要问题是缺少有标记的训练数据。近年来,远程监督成为最流行的关系提取方法-它使用知识库事实来选择一组来自未标记的数据的噪声实例。在所有用于远程监督的机器学习方法中,最近提出的卷积神经网络(CNN)模型取得了最先进的性能。继他们的成功之后,Zeng等人提出了分段最大池化策略来改善CNN。还提出了CNN的各种注意力策略,获得了令人印象深刻的结果。但是,大多数这些神经关系提取模型都是相对较浅的CNN,通常仅涉及一个卷积层和一个完全连接的层,并且尚不清楚更深层的模型在此任务中是否可以从噪声输入中提取信号而受益。
在本文中,我们研究了训练更深的CNN进行远程监督抽取提取的效果。更具体地说,我们设计了基于残差学习的卷积神经网络—我们展示了如何将单词嵌入和位置嵌入合并到一个深层残差网络中,同时将恒等反馈给卷积层以获得这种嘈杂的关系预测任务。根据经验,我们对NYT-Freebase数据集进行了评估,并使用具有恒等映射和快捷链接的深层CNN展示了最新的性能。与人们普遍认为深度残差网络仅适用于非常深的CNN的观点相反,我们表明,即使使用中等深度的CNN,也比原始CNN在关系抽取方面有了实质性的改进。我们的贡献是三方面的:
- 我们第一个考虑了将残差学习用于弱监督关系抽取的深层卷积神经网络;
- 我们证明,根据经验,我们的深度残差网络模型比CNN大得多,从而获得了最先进的性能;
- 我们的带有快速反馈方法的恒等映射可以轻松地应用于CNN的任何变体进行关系提取。
2.用于关系抽取的深度残差网络
在本节中,我们描述了一种用于远程监督关系抽取的新颖的深度残差学习体系结构。图1描述了我们模型的架构。
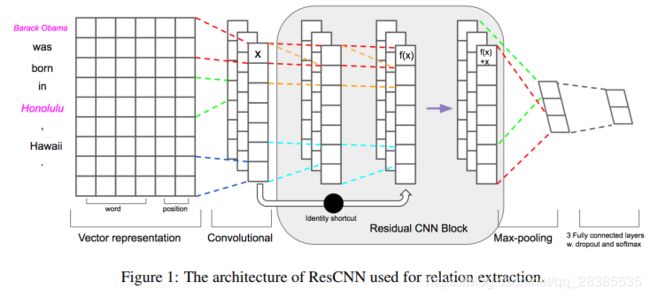
2.1 向量表示
令 x i x_i xi为句子中的第 i i i个单词,而 e 1 e1 e1, e 2 e2 e2为两个对应的实体。每个词将使用两个嵌入查询表,以获取词嵌入 W F i WF_i WFi和位置嵌入 P F i PF_i PFi。然后,我们将两个嵌入连接起来,并将每个单词表示为 v i = [ W F i , P F i ] v_i = [WF_i,PF_i] vi=[WFi,PFi]的向量。
2.1.1 词嵌入
对应于 x i x_i xi的每个表示 v i v_i vi是实值向量。所有矢量都编码在嵌入矩阵 V w ∈ R d w × ∣ V ∣ V_w∈R^{d_w×|V|} Vw∈Rdw×∣V∣中。 其中 V V V是固定大小的词汇数。
2.1.2 位置嵌入
在关系分类中,我们专注于找到实体对的关系。因此, P F PF PF是当前单词到第一实体 e 1 e1 e1和第二实体 e 2 e2 e2的相对距离的组合。例如,在句子 “ S t e v e J o b s i s t h e f o u n d e r o f A p p l e . ” “Steve~Jobs~is~the~founder~of~Apple.” “Steve Jobs is the founder of Apple.”中,从founder到 e 1 e_1 e1(Steve Job)和 e 2 e_2 e2(Apple)的相对距离分别为3和-2。然后,通过查找一个随机初始化的位置嵌入矩阵 V p ∈ R d p × ∣ ∣ P ∣ ∣ V_p∈R^{d_p×||P||} Vp∈Rdp×∣∣P∣∣(其中 P P P是固定大小的距离集),将相对距离转换为实值向量。应该注意的是,如果单词离实体太远,则可能与该关系无关。 因此,我们为相对距离选择最大值 e m a x e_{max} emax和最小值 e m i n e_{min} emin。
在图1所示的例子中,假定 d w d_w dw是4和 d p d_p dp为1。有两个位置的嵌入:一个用于 e 1 e_1 e1,其他为 e 2 e_2 e2。 最后,我们将所有单词的单词嵌入和位置嵌入连接起来,并将长度为n(在必要时进行padded)的句子表示为向量:
v = v 1 ⊕ v 2 ⊕ . . . ⊕ v n v = v_1 ⊕ v_2 ⊕ ... ⊕ v_n v=v1⊕v2⊕...⊕vn
其中, ⊕ ⊕ ⊕是一个连接操作, v i ∈ R d ( d = d w + d p × 2 ) v_i\in R^d(d=d_w+d_p×2) vi∈Rd(d=dw+dp×2)。
2.2 卷积
令 v i : i + j vi:i+j vi:i+j指单词 v i , v i + 1 , . . . , v i + j v_i,v_{i+1},...,v_{i+j} vi,vi+1,...,vi+j的串联。卷积运算涉及一个滤波器 w ∈ R h d w∈R^{hd} w∈Rhd,该滤波器应用于 h h h个单词的窗口以产生新特征。从单词 v i : i + h − 1 v_{i:i + h-1} vi:i+h−1的窗口生成特征 c i c_i ci:
c i = f ( w ⋅ x i : i + h − 1 + b ) c_i = f(w · x_{i:i+h−1}+ b) ci=f(w⋅xi:i+h−1+b)
其中 b ∈ R b∈R b∈R是一个偏差项, f f f是一个非线性函数。将此滤波器应用于从 v 1 v_1 v1到 v n v_n vn的每个可能的单词窗口,以产生特征 c = [ c 1 , c 2 , . . . , c n − h + 1 ] c = [c_1,c_2,...,c_{n-h + 1}] c=[c1,c2,...,cn−h+1],且 c ∈ R s ( s = n − h + 1 ) c∈R^s(s = n-h + 1) c∈Rs(s=n−h+1)。
2.3 残差卷积块
残差学习将低级表示形式直接连接到高级表示形式,并解决了深度网络中梯度消失的问题。在我们的模型中,我们通过应用快捷连接来设计残差卷积块。每个残差的卷积块是两个卷积层的序列,每个卷积层之后是ReLU激活。所有卷积的内核大小为 h h h,并进行填充,以使新函数具有与原始卷积相同的大小。这是两个卷积滤波器 w 1 , w 2 ∈ R h × 1 w_1,w_2∈R^{h×1} w1,w2∈Rh×1。
对于第一卷积层:
c ~ i = f ( w 1 ⋅ c i : i + h − 1 + b 1 ) \tilde{c}_i = f(w_1 · c_{i:i+h−1}+ b_1) c~i=f(w1⋅ci:i+h−1+b1)
对于第二卷积层:
c ˊ i = f ( w 2 ⋅ c i : i + h − 1 + b 2 ) \acute{c}_i = f(w_2 · c_{i:i+h−1}+ b_2) cˊi=f(w2⋅ci:i+h−1+b2)
其中, b 1 b_1 b1和 b 2 b_2 b2都是偏差项。对于残差学习操作:
c = c + c ˊ c = c +\acute{c} c=c+cˊ
方便地,将左侧的符号 c c c更改为定义为该块的输出矢量。通过快捷连接和逐元素添加来执行此操作。此块将在我们的体系结构中被多重串联。
2.4 Max Pooling, Softmax
然后,我们对特征进行最大池化操作,并取最大值 c ^ = m a x { c } \hat{c} = max\{c\} c^=max{c}。
我们已经描述了从一个过滤器中提取一个特征的过程。将所有特征合并为一个高级提取的特征 z = [ c ^ 1 , c ^ 2 , . . . , c ^ m ] z = [\hat{c}_1,\hat{c}_2,...,\hat{c}_m] z=[c^1,c^2,...,c^m](请注意,这里有m个过滤器)。 然后,将这些特征传递到完全连接的softmax层,该层的输出是关系之间的概率分布。在向前传播输出单元 y y y时使用 y = w ⋅ z + b y = w · z + b y=w⋅z+b,dropout使用 y = w ⋅ ( z ◦ r ) + b y = w · (z ◦ r) + b y=w⋅(z◦r)+b,其中 ◦ ◦ ◦是逐元素乘法运算, r ∈ R m r∈R^m r∈Rm是屏蔽向量,其是一个以概率 p p p采样1的伯努利随机变量。在测试过程,所学习的权重矢量是由 p p p缩放,使得 w ^ = p w \hat{w}= pw w^=pw去评估未知实例。