Caffe总体架构
一、Caffe总体架构
Caffe是深度学习的一个框架,Caffe框架主要包括五个组件:Blob、Solver、Net、Layer、Proto;框架结构如下图所示。这五大组件可以分为两个部分:第一部分,Blob、Layer和Net,这三个组件使得Caffe构成基于自己的模块化的模型,caffe是逐层地定义一个net,而net是从数据输入层到损失曾自下而上定义整个模型,Blob在caffe中是处理和传递实际数据的数据封装包;第二部分:Solver和Proto,这两个模型分别用于协调模型的优化以及用于网络模型的结构定义、存储和读取。
总体来说,caffe是通过Layer的方式(Layer-By-Layer)定义Net,而贯穿所有Nets的结构就是caffe框架或模型;对于Layer而言,输入的是Blob数据封装包格式的实际数据,当采用该框架进行训练时,也就是Solver调优模型,则需要Proto这种网络模型的结构定义、存储和读取。

二、Caffe模型解析
2.1 Blob、Layer、Net
Blob、Layer、Net的关系可以总结为:Caffe使用Blob结构进行存储、交换和处理网络中正向和反向迭代是的数据(值)和导数信息(梯度),Blob是Caffe框架中的标准数组结构,他提供了一个统一的内存接口,Layer是Caffe模型和计算的基本单元,Net是有Layer逐层定义的集合(网络),Blob详细描述了信息是如何在Layer个Net中存储和交换的。下面分别介绍Blob、Layer、Net的详细内容。
1)Blob
Blob是Caffe中处理和传递数据的数据封装包,并且在CPU和GPU之间具有同步处理能力。为了便于优化,Blob提供统一的内存接口来存储某种类型的数据,例如批量图像数据、模型参数以及用来进行优化的导数。
Blob是一个不定维的数据结构,其将数据展开存储,而维度单独存在一个vector类型的shape_变量中,使得每个维度可以自由变化;不过一般为四维矩阵,四维即num(图像数量)、channel(通道数量)、width(图像宽度)、height(图像亮度)。
Blob使用SyncedMemory类进行数据存储,可同步CPU和GPU上的数值,以隐藏同步的细节和最小化传送数据,其数据成员及相应功能:data_(指向实际存储数据的内存
或显存块),shape_(存储当前Blob的维度信息),diff_保存反向
diff_保存反向传递时的梯度信息)。对于Blob中的数据,我们比较关心的是values(值)和gradients
(梯度),对应地,data数据是网络中传送的普通数据,diff是通过网络计算得到的梯度。而每次操作Blob时,都要调用相应的函数来获取它的指针,因为SyncedMem需要用这
种方式来确定何时需要复制数据。实际上,使用GPU时,Caffe中CPU代码先从磁盘中加载数据到blob,同时请求一个GPU设备核(device kernel)以使用GPU进行计算再将计
算好的Blob数据送入下一层,这样既实现了高效运算,又忽略了底层细节。只要所有的Layer均有GPU实现,这种情况下所有的数据和梯度都会保留在GPU上。
2)Layer
Layer是Caffe模型的本质内容和执行计算的基本单元。Layer可以进行很多运算,如:卷积(convolution)、池化(pool)、内积(inner product)、非线性运算
(rectified-linear和sigmoid等)、元素级的数据变换、归一化(normalize)、数据加载(load data)、损失计算(losses:softmax和hinge等)。在Caffe的层目录
(layer catalogue)中查看所有操作,其囊括了绝大部分目前前沿的深度学习任务所需要的层类型。
一个Layer即是构成Net网络的一层,layer通过bottom(底部)连接层接受数据,通过top(顶部)连接层输出数据。一个层的定义如下:
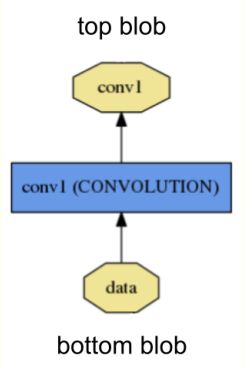
黄色多边形代表输入输出的数据,蓝色矩形表示层。
每一种Layer都定义了3种重要的运算:初始化设置(setup)、前向传播(forward pass)、反向传播(backward pass)。
Layer承担着网络的两个核心操作:前向传播(接收输入并计算输出),反向传播(接收关于输出的梯度,计算相对于参数和输入的梯度并反向传播到前面的层);由此,介绍了组成每个layer的前面通道和反向通道。
3)Net
Net是Layer以逐层地方式连接而成的网络,一个典型的Net开始于data layer(从磁盘中加载数据),终止于loss layer(计算如分类和重构这些任务的目标函数)。
Net的类中有几个关键函数:
1、ForwardBackward:按顺序调用Forward和Backward;
2、ForwardFromTo(int start,int end):执行从start层到end层的前向传递;
3、BackwardFromTo(int start,int end):执行从start层到end层的后向传递;
4、ToProto:完成网络的序列化,循环调用每个层到ToProto函数。
2.2 Solver和Proto
1)Solver
Solver算是caffe的核心的核心,它协调着整个模型的运作。caffe程序运行必带的一个参数就是solver配置文件。caffe的运行代码一般为:
caffe.exe train --solver=*_solver.prototxt
1、创建训练网络和测试网络;
2、进行前向传播和误差后向传播,更新参数,优化网络;
3、间歇性地用验证集测试网络;
4、在优化过程中,可以进行快照,进行保存中间状态。
实际上,solver就是一种迭代的优化算法。在迭代中,Solver主要做了以下工作:
1、调用forward算法来计算最终输出的值以及对应的loss;
2、调用backward算法来计算每层的梯度;
3、根据选用的solver方法,利用梯度进行参数更新;
4、记录并保存每次迭代的学习率、快照以及对应的状态。
2)Proto
proto文件是要我们编写的,其定义我们程序中需要处理的结构化数据。proto文件非常类似java或者C语言的数据定义。
补充:
(1)Protocol Buffer: 省去编写大量描述性C++代码,比如配置参数、属性变量等;方便序列化,用户可以直接阅读prototxt文件,来了解网络结构。
(2)prototxt: 描述网络,通过Google的Protobuffer编译器直接读取/序列化C++对象。
(3)caffemodel: 权重文件