GPT-2 论文翻译
GPT-2 论文翻译
基本是机器翻译,也进行了基本的人工矫正,凑活看吧
原论文:《Language Models are Unsupervised Multitask Learners》
原论文地址:https://d4mucfpksywv.cloudfront.net/better-language-models/language_models_are_unsupervised_multitask_learners.pdf
OpenAI发布的一个小版本GPT-2:https://github.com/openai/gpt-2
官网:https://www.openai.com/blog/better-language-models/
原论文最后是一个十几页的附录,里面给出了GPT-2生成的一些例子,有兴趣的话可以阅读原论文。
其他资料:
- https://www.jiqizhixin.com/articles/OpenAI-GPT-2
- https://blog.csdn.net/u012526436/article/details/87882985
- https://www.jianshu.com/p/874fd64584f5
摘要
自然语言处理任务(例如问答,机器翻译,阅读理解和摘要)通常通过对特定任务数据集的监督学习来实现。我们证明,当对数百万个名为WebText的网页的新数据集进行训练时,语言模型开始学习这些任务而不需要任何明确的监督。当以文档和问题为条件时,语言模型生成的答案在CoQA数据集上达到55 F1 - 达到或超过4个基线系统中的3个的性能而未使用127,000+个训练样例。语言模型的容量对于zero-shot任务迁移的成功至关重要,并且增加它可以跨任务以对数线性方式提高性能。我们最大型号的GPT-2是一个1.5B参数的Transformer,它在zero-shot设置中的8个测试语言建模数据集中的7个中实现了最先进的结果,但仍然不适合WebText。模型中的样本反映了这些改进,并包含连贯的文本段落。这些发现为建立语言处理系统提供了一条很有希望的方向,该系统学会从自然发生的示范中完成任务。
1. 介绍
机器学习系统现在通过将大型数据集,高容量模型和监督学习(Krizhevsky et al., 2012) (Sutskever et al., 2014) (Amodei et al., 2016)结合在一起训练,而在他们的具体任务方面表现优异(期待)。然而,这些系统是脆弱的,并且对数据分布的微小变化(Recht et al., 2018)和具体的任务敏感(Kirkpatrick et al., 2017)。目前的系统被更好地描述为狭隘的专家而不是称职的通才。我们将转向更通用的系统,它可以执行许多任务 - 最终无需为每个任务手动创建和标记训练数据集。
创建ML系统的主要方法是收集训练的样本数据集,演示所需任务的正确行为,训练系统去模仿这些行为,然后在独立同分布(IID)的held-out示例上测试其性能。这有助于在狭隘的专家方面取得进展。但是,输入的多样性往往会加剧字幕模型(captioning models)(Lake et al., 2017),阅读理解系统 (Jia & Liang, 2017)和图像分类器 (Alcorn et al., 2018) 行为的不稳定性。
我们怀疑单一领域数据集的单一任务训练的普遍性(prevalence)是当前系统缺乏一般化的主要原因。在具有当前架构的鲁棒系统方面的进步(progress)可能需要在更广泛的领域及任务上进行训练和性能测试。最近,已经有几个基准,例如GLUE(Wang et al., 2018)和decaNLP (McCann et al., 2018)开始研究这个问题。
多任务学习(Caruana,1997)是一个提高通用性的有前途的框架。然而,NLP的多任务训练仍处于初期阶段。最近的工作显示了适度的性能改进(Yogatama et al., 2019) ,迄今为止最雄心勃勃的两项努力分别培训了10对和17对(数据集,目标)(McCann et al., 2018) (Bowman et al., 2018)。从元学习的角度来看,每个(数据集,目标)对是从数据集和目标的分布中抽样的单个训练样本。当前的ML系统需要数百到数千个样本来诱导函数的通用性。这表明多任务训练很多都需要与现有方法一样多的有效训练对(pairs)来实现其承诺(promise)。很难继续扩大数据集的创建和目标的设计,以达到使用现有技术(with current techniques)来强制我们的方式(brute force our way there)所需的程度(the degree that may be required)。这有助于探索执行多任务学习的其他设置。

当前表现最佳的语言任务系统结合了预训练和监督微调。这种方法历史悠久,趋向于更灵活的迁移形式。首先,学习单词向量并将其用作特定任务体系结构的输入 (Mikolov et al., 2013) (Collobert et al., 2011),然后转移循环(recurrent)网络的语境(contextual)表示 (Dai & Le, 2015) (Peters et al., 2018),并且最近的工作表明,不再需要特定任务的架构,只需迁移带有许多自我关注的块就够了 (Radford et al., 2018) (Devlin et al., 2018)。
这些方法仍然需要监督训练才能执行任务。当只有极少或没有监督数据时,另一项工作证明了语言模型执行特定任务的前景,例如常识推理 (Schwartz et al., 2017)和情感分析 (Radford et al., 2017)。
在本文中,我们将这两个工作线连接起来,并继续采用更一般的转移方法。我们演示语言模型可以在 zero-shot 设置中执行下游任务 - 无需任何参数或体系结构修改。我们通过强调语言模型在zero-shot设置中执行各种任务的能力来证明这种方法具有的潜力。我们根据任务获得有前途,有竞争力和最先进的结果。
2. 方法
我们方法的核心是语言建模。 语言建模通常被构造为来自一组示例 ( x 1 , x 2 , . . . , x n ) (x_1,x_2,...,x_n) (x1,x2,...,xn)的无监督分布估计,每个示例由可变长度的符号序列 ( s 1 , s 2 , . . . , s n ) (s_1,s_2,...,s_n) (s1,s2,...,sn)组成。 由于语言具有自然的顺序排序,因此通常将符号上的联合概率分解为条件概率的乘积(Jelinek&Mercer,1980)(Bengio et al。,2003):
p ( x ) = ∏ i = 1 n ( s n ∣ s 1 , . . . , s n − 1 ) p(x) = \prod_{i=1}^n(s_n|s_1, ..., s_{n−1}) p(x)=i=1∏n(sn∣s1,...,sn−1)
该方法允许从 p ( x ) p(x) p(x)以及形式 p ( s n − k , . . . , s n ∣ s 1 , . . . , s n − k − 1 ) p(s_{n-k},...,s_n | s_1,...,s_{n-k-1}) p(sn−k,...,sn∣s1,...,sn−k−1)的任何条件中进行易处理的采样和估计。近年来,那些可以计算这种条件概率的模型的表现力取得了显着的成就,例如像Transformer这样的自关注架构(Vaswani et al., 2017)。
学习执行(perform)单个任务可以在概率框架中表示为估计条件分布 p ( o u t p u t ∣ i n p u t ) p(output|input) p(output∣input)。由于一般系统应该能够执行许多不同的任务,即使输入相同,它也不仅要考虑输入,还要考虑待执行(perform)的任务。也就是说,它应该对 p ( o u t p u t ∣ i n p u t , t a s k ) p(output|input, task) p(output∣input,task) 建模。在多任务和元学习设置中,它已经被各种形式化。任务调节通常在架构级别实施,例如(Kaiser et al., 2017)中任务特定(task specific)的编码器和解码器,或者其在算法级别,例如MAML的内部和外部循环优化框架 (Finn et al., 2017)。但正如McCann et al. (2018)所举例说明的那样,语言提供了一种灵活的方式来将任务,输入和输出全部指定为一系列符号。例如,翻译训练样本可以写为序列(翻译为法语,英语文本,法语文本)。同样,阅读理解训练的例子可以写成(回答问题,文档,问题,答案)。McCann et al. (2018) 证明了可以训练单个模型MQAN,用这种类型的格式推断和执行许多不同的任务。
原则上,语言建模也能够学习McCann et al. (2018)的任务,而无需确定哪些符号是待预测的输出的明确的监督。由于监督目标与无监督目标相同,但仅在序列的子集上进行评估,因此无监督目标的全局最小值也是监督目标的全局最小值。在这种轻微的玩具环境中,密度估计作为 (Sutskever et al., 2015) 中讨论的根据原则训练目标的担忧是侧面步骤。相反,问题在于我们是否能够在实践中优化无监督的目标以进行收敛。初步实验证实,足够大的语言模型能够在这种玩具设置中执行多任务学习,但学习速度比明确监督的方法慢得多。
虽然从上述适当的设置到“野外语言”的混乱是一大步,但Weston(2016)在对话的背景下认为需要开发能够直接从自然语言中学习的系统并展示了一个概念证明 - 通过使用教师输出的前向预测来学习没有奖励信号的QA任务。虽然对话是一种有吸引力的方法,但我们担心它过于严格。互联网包含大量可被动获取的信息,无需交互式通信。我们的推测是,具有足够能力的语言模型将开始学习推断和执行自然语言序列中演示的任务,以便更好地预测它们,无论其采购(procurement)方法如何。如果语言模型能够做到这一点,它实际上将执行无监督的多任务学习。我们通过在各种任务的zero-shot设置中分析语言模型的性能来测试是否是这种情况。
2.1. 训练数据集
大多数先前的工作在单个文本域上训练语言模型,例如新闻文章(Jozefowicz等,2016),维基百科(Merity等,2016),或小说书(Kiros等,2015)。我们的方法旨在尽可能地构建尽可能大且多样化的数据集,以便在尽可能多的域和上下文中收集属于任务的自然语言演示。
一个有前景的、多样化的和几乎具有无限文本的数据来源是网络搜索,例如Common Crawl。虽然这些档案比当前语言建模数据集大许多个数量级,但它们具有重要的数据质量问题(issues)。 Trinh & Le (2018) 在共同推理的工作中使用了Common Crawl,但也提示到其大量文档“大部分内容都是难以理解的”。我们在使用Common Crawl进行的初始实验中发现了类似的数据问题。 Trinh&Le(2018)的最佳结果是使用Common Crawl的一个小子样本实现的,该子样本仅包含与其目标数据集最相似的文档,即Winograd Schema Challenge。虽然这是一种提高特定任务性能的实用方法,但我们希望避免对提前执行的任务做出假设。

相反,我们创建了一个新的网页刮板(scrape),强调文档质量。为此,我们只抓取了由人类策划/过滤的网页。手动过滤完整的网络搜索将非常昂贵,作为一个起点,我们从社交媒体平台Reddit中删除了所有出站链接,该平台至少获得了3个karma。这可以被认为是一个启发式指标,用于判断其他用户是否发现链接有趣、有教育意义或有趣。
生成的数据集WebText包含这4500万个链接的文本子集。 要从HTML响应中提取文本,我们将Dragnet(Peters & Lecocq, 2013) 和 Newspaper 内容提取器组合起来使用。 本文中提供的所有结果都使用了WebText的初步版本,该版本不包括2017年12月之后创建的链接,并且在删除重复数据并做了一些启发式的清理之后,包含略多于800万个文档,总共40 GB的文本。 我们从WebText中删除了所有维基百科文档,因为它是其他数据集的通用数据源,并且训练数据与测试评估任务的重叠会使分析复杂化。
2.2. 输入表示
通用语言模型(LM)应该能够计算(并且还生成)任何字符串的概率。当前的大规模LM包含有像小写字母转化、标记化和词典外标记(out-of-vocabulary tokens)之类的预处理步骤,这限制了可模型化字符串的空间。将Unicode字符串作为一系列UTF-8字节处理的方式,优雅地满足了这一要求,如Gillick et al. (2015)的工作中所例证的那样。当前的字节级LM与大规模数据集上的字级LM不具竞争力,例如十亿字基准(One Billion Word Benchmark) (Al-Rfou et al., 2018)。我们在WebText上训练标准字节级LM的尝试中观察到了类似的性能差距。
字节对编码(BPE)(Sennrich et al., 2015)是字符和字级语言建模之间的可行的中间点(middle ground),其在 频繁符号序列的字级输入 和 不频繁符号序列的字符级输入 之间进行的插值很有效。与其名称相反,现在涉及的BPE通常在Unicode代码点而不是字节序列上实现和运行。这些实现需要包括Unicode符号的完整空间,以便为所有Unicode字符串建模。在添加任何多符号标记之前,这将使基本词汇量超过130,000,与通常一起使用的32,000到64,000个token词汇表相比,这是非常大的。相反,BPE的字节级版本仅需要大小为256的基本词汇表。然而,直接将BPE应用于字节序列会导致次优合并,这是因为BPE使用基于贪婪频率的启发方式来构建token词汇表。我们观察到BPE包括许多版本的常见词汇,如dog,因为它们出现在许多变种中,如 dog. dog! dog? . 这导致有限词汇时隙(slots)和模型容量的次优分配。为避免这种情况,我们会阻止BPE跨任何字节序列的字符类别的合并。空格是一个例外,它显着提高了压缩效率,在多个词汇标记中仅添加了最少的单词碎片。
这种输入表示允许我们将字级LM的经验益处(the empirical benefits)与字节级方法的通用性结合起来。由于我们的方法可以为任何Unicode字符串分配概率,因此我们可以在任何数据集上评估我们的LM,而不管预处理,标记化或词汇大小。
2.3. 模型
我们使用基于Transformer(Vaswani et al., 2017)的LM架构。 该模型的细节基本遵循OpenAI GPT模型 (Radford et al., 2018) ,仅进行了少量的修改。 层标准化(normalization) (Ba et al., 2016)被移动到每个子锁的输入,类似于预激活残差网络(He et al., 2016),并且在最终自注意块之后添加了额外的层标准化。 使用了修改的初始化方案,该方案考虑了具有模型深度的残差路径上的累积。 我们在初始化时将残差层的权重缩放 1 / N 1/\sqrt{N} 1/N倍,其中N是残差层的数量。 词汇量扩大到50,257。 我们还将上下文大小从512个token增加到1024,并使用更大的批量尺寸512。
3. 实验

我们对四个LM进行了训练和基准测试,其大小均为对数均匀(log-uniformly)。 结构总结在表2中。最小的模型等同于原始GPT,第二小的模型相当于BERT的最大模型(Devlin等,2018)。 我们最大的模型,我们称之为GPT-2,比GPT的参数多一个数量级。 每个模型的学习率都是手动调整的,以便在5%的WebText样本中保持最佳的困惑(perplexity)。 考虑到更多的训练时间,所有模型仍然对WebText欠拟合并且持续存在困惑(perplexity)(原句:All models still underfit WebText and held-out perplexity has as of yet improved given more training time.)。
3.1. 语言模型
作为实现zero-shot任务转移的第一步,我们有兴趣了解WebText LM如何在他们接受训练的主要任务上进行zero-shot域转移 - 语言建模。由于我们的模型在字节级别上运行,并且不需要有损的预处理或标记化,因此我们可以在任何语言模型基准测试中对其进行评估。语言建模数据集的结果通常以数量报告,该数量是每个规范预测单元的平均负对数概率的缩放或取幂版本 - 通常是字符,字节或单词。我们通过根据WebText LM计算数据集的对数概率并除以规范单位的数量来评估相同的数量。对于许多这些数据集,WebText的LM将被测试显著外的分布,具有预测积极标准化文本,标记化伪影,例如断开的标点符号和收缩,洗牌的句子,甚至字符串这在WebText极为罕见 - 在400亿字节中仅发生26次。我们使用可逆去标记器在表3中报告我们的主要结果,这些去标记器尽可能多地去除这些标记化/预处理工件。由于这些去标记符是可逆的,我们仍然可以计算数据集的对数概率,它们可以被认为是域自适应的简单形式。我们观察到使用这些去标记器对GPT-2的2.5到5倍的困惑。

WebText LMs跨域和数据集传输良好,改善了零镜头设置中8个数据集中的7个的最新技术水平。在小型数据集上注意到了很大的改进,例如Penn Treebank和WikiText-2,它们只有100万到200万个训练令牌。在为测量LAMBADA(Paperno等,2016)和儿童书籍测试(Hill等人,2015)等长期依赖性而创建的数据集中,也注意到了很大的改进。我们的模型仍然比之前在十亿字基准上的工作要糟糕得多(Chelba et al。,2013)。这可能是由于它既是最大的数据集又是一些最具破坏性的预处理 - 1BW的句子级别改组消除了所有的远程结构。
3.2. Children’s Book Test
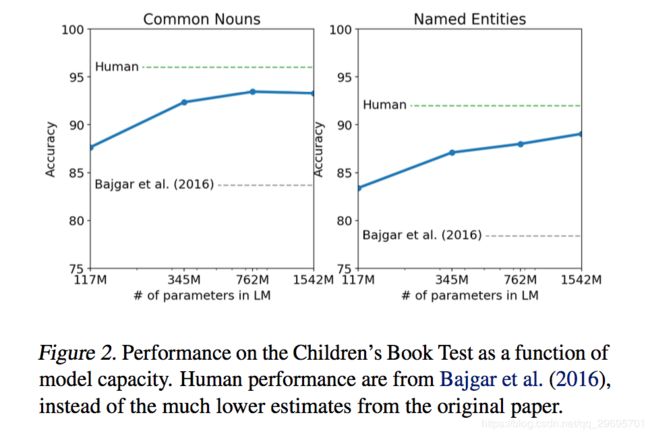
儿童书籍测试(CBT)(Hill等人,2015)的创建是为了检验LMs在不同类别的单词上的表现:命名实体,名词,动词和介词。 CBT不是将困惑报告为评估指标,而是报告自动构建的完形填空测试的准确性,其中任务是预测省略的单词的10种可能选择中的哪一种是正确的。按照原始论文中介绍的LM方法,我们根据LM计算每个选择的概率和句子的其余部分,并预测具有最高概率的那个。如图2所示,随着模型尺寸的增加,性能稳步提高,并且在此测试中缩小了与人体性能差距的大部分。数据重叠分析显示CBT测试集之一,Rudyard Kipling的Jungle Book,在WebText中,因此我们在验证集上报告没有显着重叠的结果。 GPT-2在普通名词上达到了93.3%的新技术水平,在命名实体上达到了89.1%。应用去标记器以从CBT中移除PTB样式标记化工件。
3.3. LAMBADA
LAMBADA数据集(Paperno等,2016)测试了系统在文本中建模远程依赖关系的能力。任务是预测句子的最后一个单词,这个单词需要至少50个上下文令牌才能成功预测。 GPT-2将现有技术从99.8(Grave等,2016)提高到8.6困惑,并将该测试中LMs的准确度从19%(Dehghani等,2018)提高到52.66%。调查GPT-2的错误表明大多数预测是句子的有效延续,但不是有效的最终单词。这表明LM没有使用额外的有用约束,即该词必须是句子的最后一个。添加一个停用词过滤器作为近似值可进一步提高准确率达到63.24%,从而将此任务的整体技术水平提高4%。先前的技术水平(Hoang等,2018)使用不同的受限预测设置,其中模型的输出仅限于出现在上下文中的单词。对于GPT-2,这种限制是有害的而不是有用的,因为19%的答案不在上下文中。我们使用数据集的一个版本而不进行预处理。
3.4. Winograd Schema Challenge
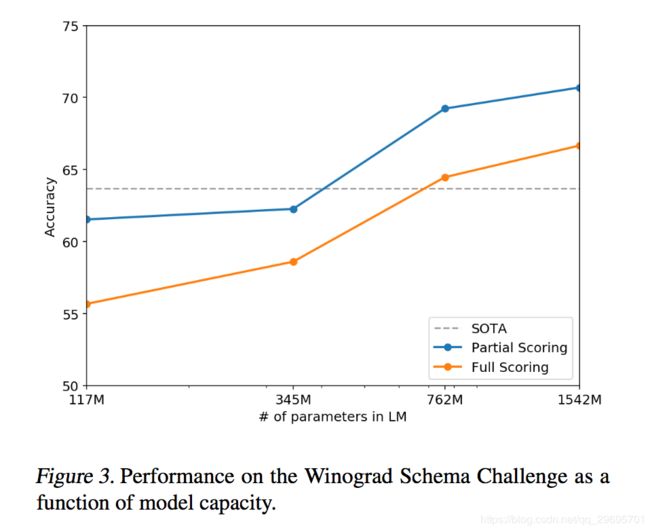
Winograd Schema挑战(Levesque等,2012)的构建旨在通过衡量系统解决文本中模糊性的能力来衡量系统执行常识推理的能力。 最近,Trinh&Le(2018)通过以更高的概率预测模糊度的分辨率,证明了使用LMs在这一挑战上的重大进展。 我们按照他们的问题表述,用图3中的全部和部分评分技术可视化模型的性能.GPT-2将现有技术精度提高了7%,达到70.70%。 数据集很小,只有273个例子,所以我们建议阅读Trichelair等人。 (2018)帮助将此结果置于语境中。
3.5. Reading Comprehension
会话问题回答数据集(CoQA)Reddy等。 (2018)由来自7个不同域的文档组成,其与问询者和关于该文档的问题回答者之间的自然语言对话配对。 CoQA测试阅读理解能力以及模型回答依赖于对话历史的问题的能力(例如“为什么?”)。
在文件条件下,GPT-2的贪婪解码,相关对话的历史以及最终的令牌A:在开发集上达到55 F1。这与4个基线系统中的3个系统的性能相匹配或超过这些系统的性能,而不使用127,000+手动收集的问题答案对。受监督的SOTA,基于BERT的系统(Devlin等,2018),接近人类的89 F1表现。虽然GPT-2的性能对于没有任何监督训练的系统来说是令人兴奋的,但是对其答案和错误的一些检查表明GPT-2经常使用基于简单检索的启发式方法,例如回答文档中的名称以回答谁的问题。
3.6. Summarization

我们测试了GPT-2在CNN和每日邮件数据集上执行摘要的能力(Nallapati等,2016)。为了引出摘要行为,我们添加文本TL; DR:在文章之后并用k = 2生成具有Top-k随机采样(Fan等,2018)的100个令牌,其减少重复并且鼓励比贪婪解码更抽象的摘要。我们使用这100个令牌中的前3个生成句子作为摘要。虽然在质量上几代人都像摘要一样,如表14所示,他们经常关注文章中的最新内容,或者混淆具体细节,例如碰撞中涉及多少辆汽车,或者帽子或衬衫上是否有徽标。在通常报告的ROUGE 1,2,L指标上,生成的摘要仅开始接近经典神经基线的表现,并且仅略微优于从文章中选择3个随机句子。当删除任务提示时,GPT-2的性能在聚合度量上下降6.4个点,这表明能够在使用自然语言的语言模型中调用任务特定的行为。
3.7. Translation
我们测试GPT-2是否已经开始学习如何从一种语言翻译成另一种语言。为了帮助它推断这是期望的任务,我们在语言英语句子=法语句子的示例对的上下文中调整语言模型,然后在英语句子的最终提示之后=我们从具有贪婪解码的模型中采样并使用第一个生成的句子作为翻译。在WMT-14英语 - 法语测试集上,GPT-2得到5个BLEU,这比先前关于无监督词翻译的工作中推断的双语词典的逐字替换稍差(Conneau et al。,2017b) 。在WMT-14法语 - 英语测试集上,GPT-2能够利用其非常强大的英语语言模型表现得更好,达到11.5 BLEU。这比(Artetxe et al。,2017)和(Lample et al。,2017)的几个无监督机器翻译基线的表现要优于目前最好的无监督机器翻译方法的33.5 BLEU(Artetxe et al。,2019)。 。这项任务的表现对我们来说是令人惊讶的,因为我们故意从WebText中删除非英语网页作为过滤步骤。为了证实这一点,我们在WebText上运行了一个字节级语言检测器2,该检测器仅检测到法语中的10MB数据,比先前无监督机器翻译研究中常见的单语法语语料库小约500倍。
3.8. Question Answering
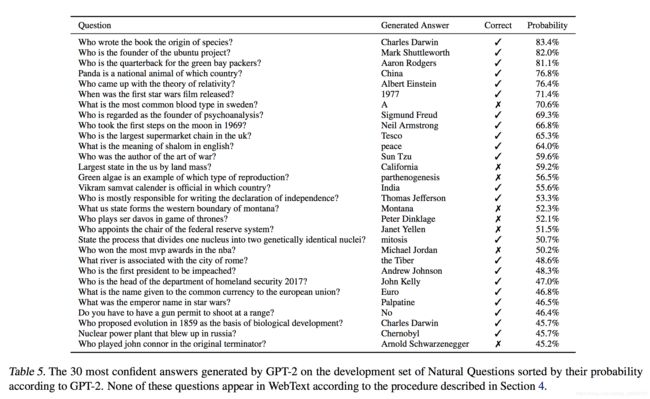
测试语言模型中包含哪些信息的潜在方法是评估它为事实式问题生成正确答案的频率。之前在神经系统中展示了这种行为,其中所有信息都存储在参数中,例如A Neural Conversational Model(Vinyals&Le,2015),由于缺乏高质量的评估数据集而报告了定性结果。最近推出的自然问题数据集(Kwiatkowski et al。,2019)是一种很有前途的资源,可以更加定量地进行测试。与翻译类似,语言模型的上下文以示例问题答案对为种子,这有助于模型推断数据集的简答案样式。当通过读取理解数据集(如SQUAD)时常用的精确匹配度量进行评估时,GPT-2可以正确回答4.1%的问题。作为比较点,最小模型不会超过返回最多的非常简单基线的1.0%准确度每种问题类型的常见答案(谁,什么,哪里等…)。 GPT-2正确回答了5.3倍的问题,这表明模型容量一直是神经系统在此类任务中表现不佳的主要因素。 GPT-2分配给其生成的答案的概率得到很好的校准,GPT-2在其最有信心的1%问题上的准确率为63.1%.GPT-2在开发集问题上产生的30个最有信心的答案是表5中显示了GPT-2的性能仍然远远大于开放域问答系统的30%到50%的范围,该系统将信息检索与提取文档问题回答混合(Alberti等,2019)。
4. Generalization vs Memorization
最近在计算机视觉方面的工作表明,常见的图像数据集包含非平凡数量的近似重复图像。例如,CIFAR-10在列车和测试图像之间有3.3%的重叠(Barz&Denzler,2019)。这导致机器学习系统的泛化性能的过度报告。随着数据集的大小增加,这个问题变得越来越可能,这表明WebText可能会发生类似的现象。因此,分析测试数据在训练数据中的显示量也很重要。
为了研究这个,我们创建了包含8克WebText训练集标记的Bloom过滤器。为了提高回忆率,将字符串规范化为仅包含较低的字母数字单词,并以单个空格作为分隔符。构造布隆过滤器使得假阳性率上限为1。我们通过生成1M字符串进一步验证了低误报率108,其中过滤器找到了0。
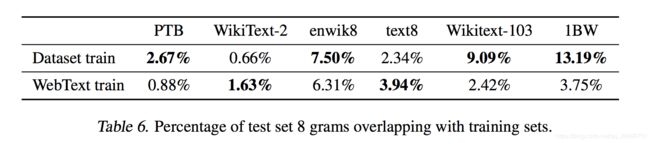
这些布隆过滤器允许我们在给定数据集的情况下计算来自该数据集的8克的百分比,该百分比也可以在WebText训练集中找到。表6显示了常见LM基准测试集的这种重叠分析。常见的LM数据集测试集与WebText序列的重叠率为1-6%,平均重叠率为3.2%。有些令人惊讶的是,许多数据集与自己的训练分裂有较大的重叠,平均重叠率为5.9%。
我们的方法优化了召回,虽然重叠的手动检查显示了许多常见短语,但由于重复数据,存在许多较长的匹配。这不是WebText独有的。例如,我们发现WikiText-103的测试集有一篇也在训练数据集中的文章。由于测试中只有60篇文章,其中几乎是1.6%.4可能更令人担忧的是,根据我们的程序,1BW与其自己的训练集重叠了近13.2%。
对于Winograd模式挑战,我们发现只有10个模式与WebText训练集有任何8克重叠。其中2个是虚假比赛。在剩余的8个中,只有1个模式出现在任何给出答案的上下文中。
对于CoQA,新闻领域中大约15%的文档已经在WebText中,并且该模型在这些文档上的表现更好。 CoQA的开发集指标报告了5个不同域的平均性能,并且由于各个域之间的重叠,我们测量了大约0.5-1.0 F1的增益。但是,自从CoTeA在WebText中链接的截止日期之后发布以来,WebText中没有实际的训练问题或答案。
在LAMBADA,平均重叠率为1.2%。 GPT-2在重叠率超过15%的示例中表现出更好的2个困惑。在排除任何重叠偏移的所有示例时重新计算指标会导致8.6到8.7的困惑,并将准确率从63.2%降低到62.9%。总体结果的这种非常小的变化可能是由于200个例子中只有1个具有显着的重叠。
总体而言,我们的分析表明,WebText训练数据与特定评估数据集之间的数据重叠为报告结果提供了一个小但一致的好处。但是,对于大多数数据集,我们没有注意到比标准训练和测试集之间已存在的重叠明显更大的重叠,如表6所示。
理解和量化高度相似的文本对性能的影响是一个重要的研究问题。更好的重复数据删除技术(如可扩展模糊匹配)也可以帮助更好地回答这些问题。目前,我们建议在创建新NLP数据集的训练和测试拆分期间,使用基于n-gram重叠的重复数据删除作为重要的验证步骤和健全性检查。
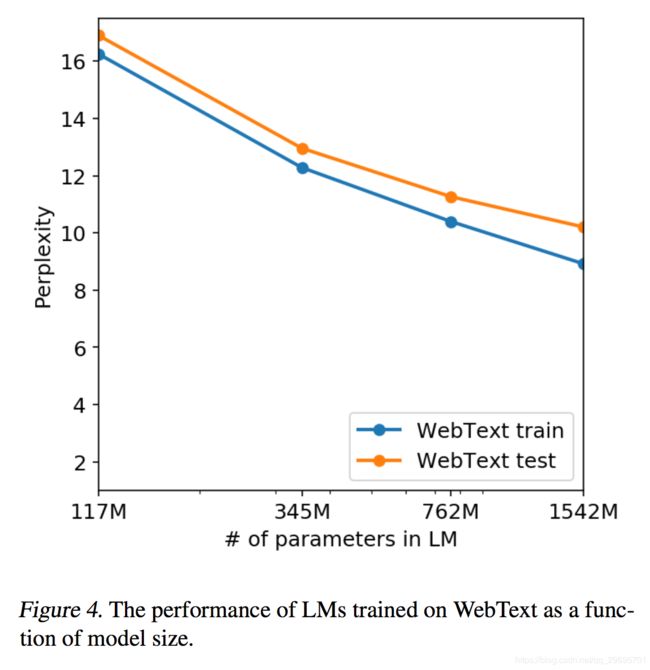
确定WebText LM的性能是否可归因于记忆的另一种可能的方法是检查它们在自己的保持集上的性能。如图4所示,WebText的训练集和测试集的性能相似,并且随着模型大小的增加而一起改进。这表明即使GPT-2在很多方面仍然不适合WebText。
GPT-2还能够撰写有关发现谈话独角兽的新闻文章。表13中提供了一个示例。
5. 相关工作
这项工作的很大一部分测量了在较大数据集上训练的较大语言模型的性能。这类似于Jozefowicz等人的工作。 (2016)在10亿字基准上扩展了基于RNN的语言模型。 Bajgar等人。 (2016)还通过在Project Gutenberg中创建一个更大的训练数据集来补充标准训练数据集,从而改进了儿童书籍测试的结果。 Hestness等。 (2017)对各种深度学习模型的性能如何随模型容量和数据集大小的变化进行了全面分析。我们的实验虽然在任务中噪音很大,但表明目标的子任务具有相似的趋势,并继续进入1B +参数体系。
之前已经记录了生成模型中有趣的学习功能,例如RNN语言模型中的细胞执行线宽跟踪和引用/评论检测Karpathy等。 (2015年)。对我们的工作更有启发性的是对刘等人的观察。 (2018)经过训练以生成维基百科文章的模型也学会了在语言之间翻译名称。
以前的工作已经探索了过滤和构建大型网页文本语料库的替代方法,例如iWeb Corpus(Davies,2018)。
关于语言任务的预训练方法已有大量工作。除了引言中提到的那些之外,GloVe(Pennington等,2014)将单词矢量表示学习扩展到所有Common Crawl。关于文本深度表征学习的早期有影响力的工作是Skip-thought Vectors(Kiros et al。,2015)。麦肯等人。 (2017)探索了使用机器翻译模型的表示,Howard&Ruder(2018)改进了基于RNN的微调方法(Dai&Le,2015)。 (Conneau et al。,2017a)研究了自然语言推理模型学习的表征的传递性能,(Subramanian et al。,2018)探索了大规模的多任务训练。
(Ramachandran等,2016)证明seq2seq模型受益于使用预先训练的语言模型作为编码器和解码器进行初始化。最近的研究表明,LM训练有助于对诸如聊天对话和基于对话的问答系统等困难的生成任务进行微调(Wolf et al。,2019)(Dinan et al。,2018)。
6. 讨论
许多研究致力于学习(Hill等,2016),理解(Levy&Goldberg,2014),并批判性地评估(Wieting&Kiela,2019)有监督和无监督预训练方法的表示。我们的研究结果表明,无监督任务学习是另一个有待探索的研究领域。这些发现可能有助于解释下游NLP任务的预训练技术的广泛成功,因为我们表明,在极限情况下,这些预训练技术之一开始学习直接执行任务而无需监督适应或修改。
在阅读理解上,GPT-2的性能与zero-shot设置中的监督基线相竞争。然而,在其他任务(如摘要)上,虽然它在质量上执行任务,但其性能仍然只是根据量化指标而言仍然不成熟。虽然作为研究结果提示,但就实际应用而言,GPT-2的zero-shot性能仍远未达到可用性。
我们研究了WebText LMs在许多规范NLP任务上的零镜头性能,但还有许多其他任务可以评估。毫无疑问,许多实际任务中GPT-2的性能仍然不比随机性好。即使在我们评估的常见任务上,例如问答和翻译,语言模型只有在具有足够容量时才开始超越琐碎的基线。
虽然zero-shot性能确定了GPT-2在许多任务中潜在性能的基线,但目前还不清楚天花板在哪里进行微调。在某些任务中,GPT-2的完全抽象输出与基于提取指针网络(Vinyals等,2015)的输出有很大不同,这些输出目前是许多问题回答和阅读理解数据集的现有技术。鉴于之前微调GPT的成功,我们计划调查decaNLP和GLUE等基准测试的微调,特别是因为不清楚GPT-2的额外训练数据和容量是否足以克服统一的低效率BERT证明了定向表示(Devlin等,2018)。
7. 结论
当大型语言模型在足够大且多样化的数据集上进行训练时,它能够在许多域和数据集中表现良好。 GPT-2在8个测试语言建模数据集中的7个中实现了最先进的性能。 模型能够在零拍设置中执行的任务的多样性表明,训练的高容量模型最大化充分变化的文本语料库的可能性开始学习如何执行惊人数量的任务而无需显式监督。
参考文献
- Al-Rfou, R., Choe, D., Constant, N., Guo, M., and Jones, L. Character-level language modeling with deeper self-attention. arXiv preprint arXiv:1808.04444, 2018.
- Alberti, C., Lee, K., and Collins, M. A bert baseline for the natural questions. arXiv preprint arXiv:1901.08634, 2019.
- Alcorn, M. A., Li, Q., Gong, Z., Wang, C., Mai, L., Ku, W.-S., and Nguyen, A. Strike (with) a pose: Neural networks are easily fooled by strange poses of familiar objects. arXiv preprint arXiv:1811.11553, 2018.
- Amodei, D., Ananthanarayanan, S., Anubhai, R., Bai, J., Battenberg, E., Case, C., Casper, J., Catanzaro, B., Cheng, Q., Chen, G., et al. Deep speech 2: End-to-end speech recognition in english and mandarin. In International Conference on Machine Learning, pp. 173–182, 2016.
- Artetxe, M., Labaka, G., Agirre, E., and Cho, K. Unsupervised neural machine translation. arXiv preprint arXiv:1710.11041, 2017.
- Artetxe, M., Labaka, G., and Agirre, E. An effective approach to unsupervised machine translation. arXiv preprint arXiv:1902.01313, 2019.
- Ba, J. L., Kiros, J. R., and Hinton, G. E. Layer normalization. arXiv preprint arXiv:1607.06450, 2016.
- Bajgar, O., Kadlec, R., and Kleindienst, J. Embracing data abundance: Booktest dataset for reading comprehension. arXiv preprint arXiv:1610.00956, 2016.
- Barz, B. and Denzler, J. Do we train on test data? purging cifar of near-duplicates. arXiv preprint arXiv:1902.00423, 2019.
- Bengio, Y., Ducharme, R., Vincent, P., and Jauvin, C. A neural probabilistic language model. Journal of machine learning research, 3(Feb):1137–1155, 2003.
- Bowman, S. R., Pavlick, E., Grave, E., Van Durme, B., Wang, A., Hula, J., Xia, P., Pappagari, R., McCoy, R. T., Patel, R., et al. Looking for elmo’s friends: Sentence-level pretraining beyond language modeling. arXiv preprint arXiv:1812.10860, 2018.
- Caruana, R. Multitask learning. Machine learning, 28(1):41–75, 1997.
- Chelba, C., Mikolov, T., Schuster, M., Ge, Q., Brants, T., Koehn, P., and Robinson, T. One billion word benchmark for measuring progress in statistical language modeling. arXiv preprint arXiv:1312.3005, 2013.
- Collobert, R., Weston, J., Bottou, L., Karlen, M., Kavukcuoglu, K., and Kuksa, P. Natural language processing (almost) from scratch. Journal of Machine Learning Research, 12(Aug):2493– 2537, 2011.
- Conneau, A., Kiela, D., Schwenk, H., Barrault, L., and Bordes, A. Supervised learning of universal sentence representations from natural language inference data. arXiv preprint arXiv:1705.02364, 2017a.
- Conneau, A., Lample, G., Ranzato, M., Denoyer, L., and Je ́gou, H. Word translation without parallel data. arXiv preprint arXiv:1710.04087, 2017b.
- Dai, A. M. and Le, Q. V. Semi-supervised sequence learning. In Advances in neural information processing systems, pp. 3079– 3087, 2015.
- Dai, Z., Yang, Z., Yang, Y., Cohen, W. W., Carbonell, J., Le, Q. V., and Salakhutdinov, R. Transformer-xl: Attentive language models beyond a fixed-length context. arXiv preprint arXiv:1901.02860, 2019.
- Davies, M. The 14 billion word iweb corpus. https://corpus.byu.edu/iWeb/, 2018.
- Dehghani, M., Gouws, S., Vinyals, O., Uszkoreit, J., and Kaiser, Ł. Universal transformers. arXiv preprint arXiv:1807.03819, 2018.
- Devlin, J., Chang, M.-W., Lee, K., and Toutanova, K. Bert: Pretraining of deep bidirectional transformers for language understanding. arXiv preprint arXiv:1810.04805, 2018.
- Dinan, E., Roller, S., Shuster, K., Fan, A., Auli, M., and Weston, J. Wizard of wikipedia: Knowledge-powered conversational agents. arXiv preprint arXiv:1811.01241, 2018.
- Fan, A., Lewis, M., and Dauphin, Y. Hierarchical neural story generation. arXiv preprint arXiv:1805.04833, 2018.
- Finn, C., Abbeel, P., and Levine, S. Model-agnostic meta-learning for fast adaptation of deep networks. arXiv preprint arXiv:1703.03400, 2017.
- Gehrmann, S., Deng, Y., and Rush, A. M. Bottom-up abstractive summarization. arXiv preprint arXiv:1808.10792, 2018.
- Gillick, D., Brunk, C., Vinyals, O., and Subramanya, A. Multilingual language processing from bytes. arXiv preprint arXiv:1512.00103, 2015.
- Gong, C., He, D., Tan, X., Qin, T., Wang, L., and Liu, T.-Y. Frage: frequency-agnostic word representation. In Advances in Neural Information Processing Systems, pp. 1341–1352, 2018.
- Grave, E., Joulin, A., and Usunier, N. Improving neural language models with a continuous cache. arXiv preprint arXiv:1612.04426, 2016.
- He, K., Zhang, X., Ren, S., and Sun, J. Identity mappings in deep residual networks. In European conference on computer vision, pp. 630–645. Springer, 2016.
- Hestness, J., Narang, S., Ardalani, N., Diamos, G., Jun, H., Kianinejad, H., Patwary, M., Ali, M., Yang, Y., and Zhou, Y. Deep learning scaling is predictable, empirically. arXiv preprint arXiv:1712.00409, 2017.
- Hill, F., Bordes, A., Chopra, S., and Weston, J. The goldilocks principle: Reading children’s books with explicit memory representations. arXiv preprint arXiv:1511.02301, 2015.
- Hill, F., Cho, K., and Korhonen, A. Learning distributed representations of sentences from unlabelled data. arXiv preprint arXiv:1602.03483, 2016.
- Hoang, L., Wiseman, S., and Rush, A. M. Entity tracking improves cloze-style reading comprehension. arXiv preprint arXiv:1810.02891, 2018.
- Howard, J. and Ruder, S. Universal language model fine-tuning for text classification. In Proceedings of the 56th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), volume 1, pp. 328–339, 2018.
- Jelinek, F. and Mercer, R. L. Interpolated estimation of markov source parameters from sparse data. In Proceedings of the Workshop on Pattern Recognition in Practice, Amsterdam, The Netherlands: North-Holland, May., 1980.
- Jia, R. and Liang, P. Adversarial examples for evaluating reading comprehension systems. arXiv preprint arXiv:1707.07328, 2017.
- Jozefowicz, R., Vinyals, O., Schuster, M., Shazeer, N., and Wu, Y. Exploring the limits of language modeling. arXiv preprint arXiv:1602.02410, 2016.
- Kaiser, L., Gomez, A. N., Shazeer, N., Vaswani, A., Parmar, N., Jones, L., and Uszkoreit, J. One model to learn them all. arXiv preprint arXiv:1706.05137, 2017.
- Karpathy, A., Johnson, J., and Fei-Fei, L. Visualizing and understanding recurrent networks. arXiv preprint arXiv:1506.02078, 2015.
- Kirkpatrick, J., Pascanu, R., Rabinowitz, N., Veness, J., Desjardins, G., Rusu, A. A., Milan, K., Quan, J., Ramalho, T., Grabska-Barwinska, A., et al. Overcoming catastrophic forgetting in neural networks. Proceedings of the national academy of sciences, pp. 201611835, 2017.
- Kiros, R., Zhu, Y., Salakhutdinov, R. R., Zemel, R., Urtasun, R., Torralba, A., and Fidler, S. Skip-thought vectors. In Advances in neural information processing systems, pp. 3294–3302, 2015.
- Krizhevsky, A., Sutskever, I., and Hinton, G. E. Imagenet classification with deep convolutional neural networks. In Advances in neural information processing systems, pp. 1097–1105, 2012.
- Kwiatkowski, T., Palomaki, J., Rhinehart, O., Collins, M., Parikh, A., Alberti, C., Epstein, D., Polosukhin, I., Kelcey, M., Devlin, J., et al. Natural questions: a benchmark for question answering research. 2019.
- Lake, B. M., Ullman, T. D., Tenenbaum, J. B., and Gershman, S. J. Building machines that learn and think like people. Behavioral and Brain Sciences, 40, 2017.
- Lample, G., Conneau, A., Denoyer, L., and Ranzato, M. Unsupervised machine translation using monolingual corpora only. arXiv preprint arXiv:1711.00043, 2017.
- Levesque, H., Davis, E., and Morgenstern, L. The winograd schema challenge. In Thirteenth International Conference on the Principles of Knowledge Representation and Reasoning, 2012.
- Levy, O. and Goldberg, Y. Neural word embedding as implicit matrix factorization. In Advances in neural information processing systems, pp. 2177–2185, 2014.
- Liu, P. J., Saleh, M., Pot, E., Goodrich, B., Sepassi, R., Kaiser, L., and Shazeer, N. Generating wikipedia by summarizing long sequences. arXiv preprint arXiv:1801.10198, 2018.
- McCann, B., Bradbury, J., Xiong, C., and Socher, R. Learned in translation: Contextualized word vectors. In Advances in Neural Information Processing Systems, pp. 6294–6305, 2017.
- McCann, B., Keskar, N. S., Xiong, C., and Socher, R. The natural language decathlon: Multitask learning as question answering. arXiv preprint arXiv:1806.08730, 2018.
- Merity, S., Xiong, C., Bradbury, J., and Socher, R. Pointer sentinel mixture models. arXiv preprint arXiv:1609.07843, 2016.
- Mikolov, T., Sutskever, I., Chen, K., Corrado, G. S., and Dean, J. Distributed representations of words and phrases and their compositionality. In Advances in neural information processing systems, pp. 3111–3119, 2013.
- Nallapati, R., Zhou, B., Gulcehre, C., Xiang, B., et al. Abstractive text summarization using sequence-to-sequence rnns and beyond. arXiv preprint arXiv:1602.06023, 2016.
- Paperno, D., Kruszewski, G., Lazaridou, A., Pham, Q. N., Bernardi, R., Pezzelle, S., Baroni, M., Boleda, G., and Ferna ́ndez, R. The lambada dataset: Word prediction requiring a broad discourse context. arXiv preprint arXiv:1606.06031, 2016.
- Pennington, J., Socher, R., and Manning, C. Glove: Global vectors for word representation. In Proceedings of the 2014 conference on empirical methods in natural language processing (EMNLP), pp. 1532–1543, 2014.
- Peters, M. E. and Lecocq, D. Content extraction using diverse feature sets. In Proceedings of the 22nd International Conference on World Wide Web, pp. 89–90. ACM, 2013.
- Peters, M. E., Neumann, M., Iyyer, M., Gardner, M., Clark, C., Lee, K., and Zettlemoyer, L. Deep contextualized word representations. arXiv preprint arXiv:1802.05365, 2018.
- Radford, A., Jozefowicz, R., and Sutskever, I. Learning to generate reviews and discovering sentiment. arXiv preprint arXiv:1704.01444, 2017.
- Radford, A., Narasimhan, K., Salimans, T., and Sutskever, I. Improving language understanding by generative pre-training. 2018.
- Ramachandran, P., Liu, P. J., and Le, Q. V. Unsupervised pre-training for sequence to sequence learning. arXiv preprint arXiv:1611.02683, 2016.
- Recht, B., Roelofs, R., Schmidt, L., and Shankar, V. Do cifar-10 classifiers generalize to cifar-10? arXiv preprint arXiv:1806.00451, 2018.
- Reddy, S., Chen, D., and Manning, C. D. Coqa: A conversational question answering challenge. arXiv preprint arXiv:1808.07042, 2018.
- Schwartz, R., Sap, M., Konstas, I., Zilles, L., Choi, Y., and Smith, N. A. Story cloze task: Uw nlp system. In Proceedings of the 2nd Workshop on Linking Models of Lexical, Sentential and Discourse-level Semantics, pp. 52–55, 2017.
- See, A., Liu, P. J., and Manning, C. D. Get to the point: Summarization with pointer-generator networks. arXiv preprint arXiv:1704.04368, 2017.
- Sennrich, R., Haddow, B., and Birch, A. Neural machine translation of rare words with subword units. arXiv preprint arXiv:1508.07909, 2015.
- Subramanian, S., Trischler, A., Bengio, Y., and Pal, C. J. Learning general purpose distributed sentence representations via large scale multi-task learning. arXiv preprint arXiv:1804.00079, 2018.
- Sutskever, I., Vinyals, O., and Le, Q. V. Sequence to sequence learning with neural networks. In Advances in neural information processing systems, pp. 3104–3112, 2014.
- Sutskever, I., Jozefowicz, R., Gregor, K., Rezende, D., Lillicrap, T., and Vinyals, O. Towards principled unsupervised learning. arXiv preprint arXiv:1511.06440, 2015.
- Trichelair, P., Emami, A., Cheung, J. C. K., Trischler, A., Suleman, K., and Diaz, F. On the evaluation of common-sense reasoning in natural language understanding. arXiv preprint arXiv:1811.01778, 2018.
- Trinh, T. H. and Le, Q. V. A simple method for commonsense reasoning. arXiv preprint arXiv:1806.02847, 2018.
- Vaswani, A., Shazeer, N., Parmar, N., Uszkoreit, J., Jones, L., Gomez, A. N., Kaiser, Ł., and Polosukhin, I. Attention is all you need. In Advances in Neural Information Processing Systems, pp. 5998–6008, 2017.
- Vinyals, O. and Le, Q. A neural conversational model. arXiv preprint arXiv:1506.05869, 2015.
- Vinyals, O., Fortunato, M., and Jaitly, N. Pointer networks. In Advances in Neural Information Processing Systems, pp. 2692– 2700, 2015.
- Wang, A., Singh, A., Michael, J., Hill, F., Levy, O., and Bowman, S. R. Glue: A multi-task benchmark and analysis platform for natural language understanding. arXiv preprint arXiv:1804.07461, 2018.
- Weston, J. E. Dialog-based language learning. In Advances in Neural Information Processing Systems, pp. 829–837, 2016.
- Wieting, J. and Kiela, D. No training required: Exploring random encoders for sentence classification. arXiv preprint arXiv:1901.10444, 2019.
- Wolf, T., Sanh, V., Chaumond, J., and Delangue, C. Transfertransfo: A transfer learning approach for neural network based conversational agents. arXiv preprint arXiv:1901.08149, 2019.
- Yogatama, D., d’Autume, C. d. M., Connor, J., Kocisky, T., Chrzanowski, M., Kong, L., Lazaridou, A., Ling, W., Yu, L., Dyer, C., et al. Learning and evaluating general linguistic intelligence. arXiv preprint arXiv:1901.11373, 2019.