mycat使用指南 支持跨库查询和数据均分
数据库分片
简单来说,就是指通过某种特定的条件,将我们存放在同一个数据库中的数据分散存放到多
个数据库(主机)上面,以达到分散单台设备负载的效果。
192.168.52.155的3306实例下的 pm1 pm2 pm3
3个库和
192.168.52.155 3307 pm1
192.168.52.155 3308 pm2
192.168.52.155 3309 pm3
3个实例下的的3库是互相独立的,
我们平时开发(由于在项目连接的是mycat jdbc:mysql://192.168.52.155:8066/TESTDB,
在mycat配置文件schema.xml,配置了标签内配置了3个端口,即分别属于3个实例下的3个库)
就不需要连接3306的 pm1 pm2 pm3,
如果需要查询分片表对应的总表的数据, 你直接navicat连接mycat的连接地址,
select逻辑表名就可以了 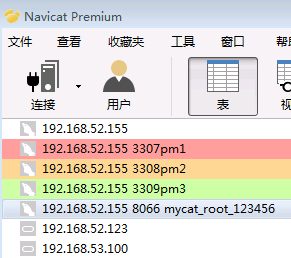
192.168.52.155的mycat 分片管理了 pm1 pm2 pm3库下的
pm1库 (非分片表使用mycat) 的表是在mycat中配置为 非分片的逻辑表
pm2库 pm3库 (分片表使用mycat) 都有pm_enb_开头的表, 在mycat中配置为分片的逻辑表, 且为了分片 是提前创建好的, 为了实现数据均分
pm_enb_r001
pm_enb_r001d
pm_enb_r001h
1、逻辑库(schema)
前面一节讲了数据库中间件,通常对实际应用来说,并不需要知道中间件的存在,业务开发
人员只需要知道数据库的概念,所以数据库中间件可以被看做是一个或多个数据库集群构成
的逻辑库。
2、逻辑表(table)
既然有逻辑库,那么就会有逻辑表,分布式数据库中,对应用来说,读写数据的表就是逻辑
表。逻辑表,可以是数据切分后,分布在一个或多个分片库中,也可以不做数据切分,不分
片,只有一个表构成。
分片表:是指那些原有的很大数据的表,需要切分到多个数据库的表,这样,每个分片都有
一部分数据,所有分片构成了完整的数据。 总而言之就是需要进行分片的表。
非分片表:一个数据库中并不是所有的表都很大,某些表是可以不用进行切分的,非分片是
相对分片表来说的,就是那些不需要进行数据切分的表。
3、分片节点(dataNode)
数据切分后,一个大表被分到不同的分片数据库上面,每个表分片所在的数据库就是分片节
点(dataNode)。
4、节点主机(dataHost)
数据切分后,每个分片节点(dataNode)不一定都会独占一台机器,同一机器上面可以有
多个分片数据库,这样一个或多个分片节点(dataNode)所在的机器就是节点主机
(dataHost),为了规避单节点主机并发数限制,尽量将读写压力高的分片节点
(dataNode)均衡的放在不同的节点主机(dataHost)。
5、分片规则(rule)
前面讲了数据切分,一个大表被分成若干个分片表,就需要一定的规则,这样按照某种业务
规则把数据分到某个分片的规则就是分片规则,数据切分选择合适的分片规则非常重要,将
极大的避免后续数据处理的难度。
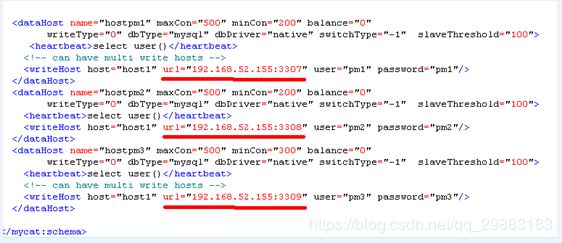
Mycat配置:
schema.xml文件位于conf目录下,Schema.xml作为MyCat中重要的配置文件之一,管理着MyCat的逻辑库、表、分片规则、DataNode以及DataSource。
数据库中间件 mycat, 对多个表分片(按一定的rule规则进行),供高可用性数据分片集群;
支持数据自动分片到多个节点,用于高效表关联查询,垮库join
在github下载Mycat-Server这个项目
设置user name,password及schemas, name和password要在Mycat连接MySQL数据库时使用,
schemas是逻辑库,要和schema.xml里的schema name对应
server.xml 里有 password (123456)和schemas (TESTDB 即在mycat当中显示的模拟库的名称) 等下使用 navicat连接
schema.xml 也要配置 TESTDB(即在mycat当中显示的模拟库的名称)
schema.xml配置详解释:
Schema
name:逻辑库名称,sqlMaxLimit:默认显示条数
Table
name:逻辑表名称,rule:分片规则
D:\mycat\bin修改rule.xml
此次选用默认的取模模式mod-long规则(即分片为10张表),只需修改count数,对应上subTables数
Mycat 实现MySQL单库分表及实现数据均分
在mysql库上创建10张表 user1-user10
在我们的项目中,对如下开头的表使用mycat分片管理了pm2 pm3库(即mycat的多库分片)
pm_enb_r001 pm2 和 pm3库 都有pm_enb_开头的表(这些都是分片表),且表的个数和结构一样,如pm_enb_r001表(nei=101的在pm3库有,在pm2库就没有,正好验证了数据均分的)
计数器组表 pm_counter_groups
网元计数器表 表名拼写规则 pm_网元类型_计数器组id(即pm_counter_groups表group_id字段)
pm1库和pm2库都有如下的表 pm_enb_r001 pm_enb_r001d pm_enb_r001h pm_enb_r001m
pm_enb_r001表是每隔15分钟网元上报解析入库的表,
pm_enb_r001m m结尾表示分钟粒度的网元计数器表(这个是网元每隔1分钟上报的二进制文件, 解析入库; 而15分钟的是网元每隔15分钟,解析入库
d, h结尾的表 是mysql定时事件 调用存储过程计算出的 天粒度 小时粒度 的数据
pm_gnb_r1024hy
pm_epc_c014d
pm_north_1000000
pm_dn_temp_10019
pm_data_r600_tmp
使用分片后,如何查询 分片表 对应的总表?
查询逻辑表名就可以了, 即 select * from pm_enb_r001 (你配置了好多个逻辑表(分片的逻辑表和非分片的逻辑表))
-- 需要分片的表 dataNode值是多个 rule是分片规则
-- 不需要分片的表 (只有name 和 dataNode的值只有一个)
使用mycat以后, 执行shell脚本(在多个库下执行sql文件)
(install_pc.sh parameter.ini文件定义了database=pm3 修改parameter.ini参数 database=pm2,pm3 )执行创建库的存储过程,
即执行shell文件即可在 pm2 pm3库下执行创建库的sql文件(生成的表结构完全一致,且都是1247个)