字符串匹配的三个算法(KMP+字典树+AC自动机)
字符串匹配的意思是给一个字符串集合,和另一个字符串集合,看这两个集合交集是多少。
若是都只有一个字符串,那么就看其中一个是否包含另外一个;
若是父串集合(比较长的,被当做模板)的有多个,子串(拿去匹配的)只有一个,就是问这个子串是否存在于父串之中;
若是子串父串集合都有多个,那么就是问交集了。
1.KMP算法
KMP算法是用来处理一对一的匹配的。
朴素的匹配算法,或者说暴力匹配法,就是将两个字符串从头比到尾,若是有一个不同,那么从下一位再开始比。这样太慢了。所以KMP算法的思想是,对匹配串本身先做一个处理,得到一个next数组。这个数组是做什么用的呢?next [j] = k,代表j之前的字符串中有最大长度为k 的相同前缀后缀。记录这个有什么用呢?对于ABCDABC这个串,如果我们匹配ABCDABTBCDABC这个长串,当匹配到第7个字符T的时候就不匹配了,我们就不用直接移到B开始再比一次,而是直接移到第5位来比较,岂不美哉?所以求出了next数组,KMP就完成了一大半。next数组也可以说是开始比较的位数。
计算next数组的方法是对于长度为n的匹配串,从0到n-1位依次求出前缀后缀最大匹配长度。
比如ABCDABD这个串:
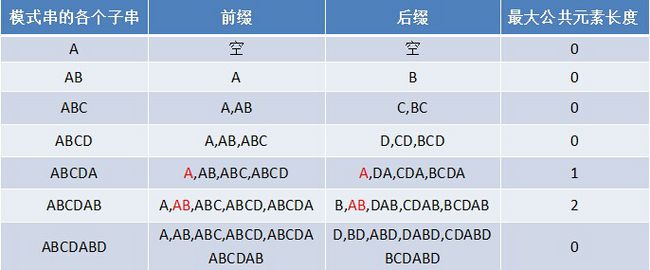
(图片来源https://www.cnblogs.com/zhangtianq/p/5839909.html)
如何去求next数组呢?k是匹配下标。这里没有从最后一位开始和第一位开始分别比较前缀后缀,而是利用了next[i-1]的结果。
void getnext()//获取next数组
{
int i,n,k;
n=strlen(ptr);
memset(next,0,sizeof(next));
k=0;
for(i=1;i0 && ptr[k]!=ptr[i])
k=next[k];
if(ptr[k]==ptr[i]) k++;
next[i+1]=k;
//next表示的是匹配长度
}
} int kmp(char *a,char *b)//匹配ab两串,a为父串
{
int i=0,j=0;
int len1=strlen(a);
int len2=strlen(b);
getnext();
while(i=len2)
return i-j;
else return -1;
} 一个完整的代码:
#include
#include
#include
using namespace std;
const int N=100;
char str[100],ptr[100];//父串str和子串ptr
int next[100];
string ans;
void getnext()//获取next数组
{
int i,n,k;
n=strlen(ptr);
memset(next,0,sizeof(next));
k=0;
for(i=1;i0 && ptr[k]!=ptr[i])
k=next[k];
if(ptr[k]==ptr[i]) k++;
next[i+1]=k;
//next表示的是匹配长度
}
}
int kmp(char *a,char *b)//匹配ab两串,a为父串
{
int i=0,j=0;
int len1=strlen(a);
int len2=strlen(b);
getnext();
while(i=len2)
return i-j;
else return -1;
}
int main(){
while( scanf( "%s%s", str, ptr ) )
{
int ans = kmp(str,ptr);
if(ans>=0)
printf( "%d\n", kmp( str,ptr ));
else
printf("Not find\n");
}
return 0;
}
2.字典树算法
上面的KMP是一对一匹配的时候常用的算法。而字典树则是一对多的时候匹配常用算法。其含义是,把一系列的模板串放到一个树里面,然后每个节点存的是它自己的字符,从根节点开始往下遍历就可以得到一个个单词了。
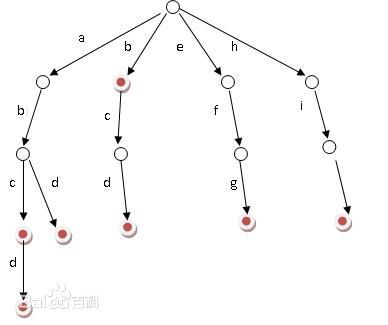
(图片来自百度)
我这里写的代码稍微和上面有一点区别,我的节点tnode里面没有存它本身的字符,而是存一个孩子数组。所以当数据量很大的时候还是需要做一些变通的,不可直接套用此代码。若是想以每个节点为一个node,那么要注意根节点是空的。
树的节点tnode,这里的next[i]存的是子节点指针。sum=0表示这个点不是重点。为n>0表示有n个单词以此为终点。
struct tnode{
int sum;//用来判断是否是终点的
tnode* next[26];
tnode(){
for(int i =0;i<26;i++)
next[i]=NULL;
sum=0;
}
};插入函数:
这个newnode是手写的构造函数.C++类有些坑,不像java那么...随便。
假设字典树已经有了aer,现在插入abc,首先看a,不为空,那么直接跳到a节点里,看b,为空,那么新建,跳到b里,新建c,跳出。
tnode* newnode(){
tnode *p = new tnode;
for(int i =0;i<26;i++)
p->next[i]=NULL;
p->sum=0;
return p;
}
//插入函数
void Insert(char *s)
{
tnode *p = root;
for(int i = 0 ; s[i] ; i++)
{
int x = s[i] - 'a';
if(p->next[x]==NULL)
{
tnode *nn=newnode();
for(int j=0;j<26;j++)
nn->next[j] = NULL;
nn->sum = 0;
p->next[x]=nn;
}
p = p->next[x];
}
p->sum++;//这个单词终止啦
}bool Compare(char *ch)
{
tnode *p = root;
int len = strlen(ch);
for(int i = 0; i < len; i++)
{
int x = ch[i] - 'a';
p = p->next[x];
if(p==NULL)
return false;
if(i==len-1 && p->sum>0 ){
return true;
}
}
return false;
}#include
#include
#include
#include
#include
#include
#include
using namespace std;
/*
trie字典树
*/
struct tnode{
int sum;//用来判断是否是终点的
tnode* next[26];
tnode(){
for(int i =0;i<26;i++)
next[i]=NULL;
sum=0;
}
};
tnode *root;
tnode* newnode(){
tnode *p = new tnode;
for(int i =0;i<26;i++)
p->next[i]=NULL;
p->sum=0;
return p;
}
//插入函数
void Insert(char *s)
{
tnode *p = root;
for(int i = 0 ; s[i] ; i++)
{
int x = s[i] - 'a';
if(p->next[x]==NULL)
{
tnode *nn=newnode();
for(int j=0;j<26;j++)
nn->next[j] = NULL;
nn->sum = 0;
p->next[x]=nn;
}
p = p->next[x];
}
p->sum++;//这个单词终止啦
}
//匹配函数
bool Compare(char *ch)
{
tnode *p = root;
int len = strlen(ch);
for(int i = 0; i < len; i++)
{
int x = ch[i] - 'a';
p = p->next[x];
if(p==NULL)
return false;
if(i==len-1 && p->sum>0 ){
return true;
}
}
return false;
}
void DELETE(tnode * &top){
if(top==NULL)
return;
for(int i =0;i<26;i++)
DELETE(top->next[i]);
delete top;
}
int main()
{
int n,m;
cin>>n;
char s[20];
root = newnode();
for(int i =0;i>m;
for(int i =0;i 3.AC自动机
字典树是一对多的匹配,那么AC自动机就是多对多的匹配了。意思是:给一个字典,再给一个m长的文本,问这个文本里出现了字典里的哪些字。
这个问题可以用n个单词的n次KMP算法来做(效率为O(n*m*单词平均长度)),也可以用1个字典树去匹配文本串的每个字母位置来做(效率为O(m*每次字典树遍历的平均深度))。上面两种解法效率都不高,如果用AC自动机来解决的话,效率将为线性O(m)时间复杂度。
AC自动机也运用了一点KMP算法的思想。简述为字典树+KMP也未为不可。
首先讲一下acnode的结构:
与字典树相比,就多了个*fail对吧,这个就相当于KMP算法里的next数组。只不过它存的是失配后跳转的位置,而不是跳转之后再向前跳了多少罢了。
struct acnode{
int sum;
acnode* next[26];
acnode* fail;
acnode(){
for(int i =0;i<26;i++)
next[i]=NULL;
fail= NULL;
sum=0;
}
};插入什么的我就不说了,记得把fail置为空即可。
这里说一下fail指针的获取。fail指针是通过BFS来求的。
看这么一张图
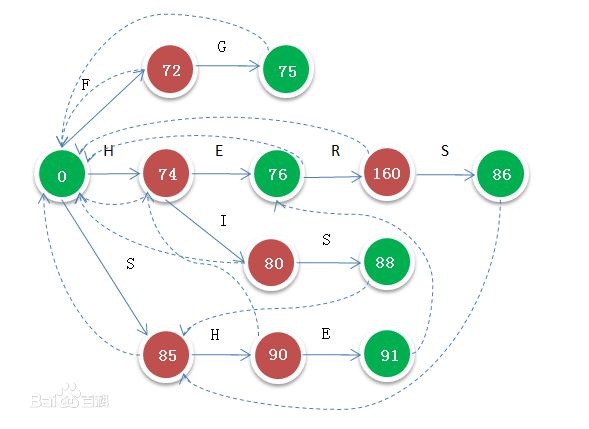
(图片来自百度)
图中数字我们不用管它,绿色代表是终点,虚线就是fail指针了。我们可以看到91 E节点的fail指针是指向76 E 的,也就是说执行到这里如果无法继续匹配就会跳到76 E那个节点继续往后匹配。我们可以看到它们前面都是H,也就是说fail指针指向的是父节点相同的同值节点(根节点视为与任何节点相同)。我们要算的是在一个长文本里面有多少个出现的单词,这个fail指针就是为了快速匹配而诞生的。若文本里出现了HISHERS,我们首先匹配了HIS,有通过fail指针跳到85 S从而匹配SHE,再匹配HERS。fail指针跳到哪里就代表这一点之前的内容已经被匹配了。这样就避免了再从头重复判断的过程。
在函数里,当前节点的fail指针也会去更新此节点的孩子的fail指针,因为父节点相同啊~而且因为它是此节点的fail指针,这两个节点的父节点也相同啊~所以一路相同过来,就保证fail指向的位置前缀是相同的。
void getfail(){
queue q;
for(int i = 0 ; i < 26 ; i ++ )
{
if(root->next[i]!=NULL){
root->next[i]->fail = root;
q.push(root->next[i]);
}
}
while(!q.empty()){
acnode* tem = q.front();
q.pop();
for(int i = 0;i<26;i++){
if(tem->next[i]!=NULL)
{
acnode *p;
p = tem->fail;
while(p!=NULL){
if(p->next[i]!=NULL){
tem->next[i]->fail = p->next[i];
break;
}
p=p->fail;
}
if(p==NULL)
tem->next[i]->fail = root;
q.push(tem->next[i]);
}
}
}
} 全部代码如下:
#include
#include
#include
#include
#include
#include
#include
using namespace std;
/*
ac自动机
*/
struct acnode{
int sum;
acnode* next[26];
acnode* fail;
acnode(){
for(int i =0;i<26;i++)
next[i]=NULL;
fail= NULL;
sum=0;
}
};
acnode *root;
int cnt;
acnode* newnode(){
acnode *p = new acnode;
for(int i =0;i<26;i++)
p->next[i]=NULL;
p->fail = NULL;
p->sum=0;
return p;
}
//插入函数
void Insert(char *s)
{
acnode *p = root;
for(int i = 0; s[i]; i++)
{
int x = s[i] - 'a';
if(p->next[x]==NULL)
{
acnode *nn=newnode();
for(int j=0;j<26;j++)
nn->next[j] = NULL;
nn->sum = 0;
nn->fail = NULL;
p->next[x]=nn;
}
p = p->next[x];
}
p->sum++;
}
//获取fail指针,在插入结束之后使用
void getfail(){
queue q;
for(int i = 0 ; i < 26 ; i ++ )
{
if(root->next[i]!=NULL){
root->next[i]->fail = root;
q.push(root->next[i]);
}
}
while(!q.empty()){
acnode* tem = q.front();
q.pop();
for(int i = 0;i<26;i++){
if(tem->next[i]!=NULL)
{
acnode *p;
if(tem == root){
tem->next[i]->fail = root;
}
else
{
p = tem->fail;
while(p!=NULL){
if(p->next[i]!=NULL){
tem->next[i]->fail = p->next[i];
break;
}
p=p->fail;
}
if(p==NULL)
tem->next[i]->fail = root;
}
q.push(tem->next[i]);
}
}
}
}
//匹配函数
void ac_automation(char *ch)
{
acnode *p = root;
int len = strlen(ch);
for(int i = 0; i < len; i++)
{
int x = ch[i] - 'a';
while(p->next[x]==NULL && p != root)//没匹配到,那么就找fail指针。
p = p->fail;
p = p->next[x];
if(!p)
p = root;
acnode *temp = p;
while(temp != root)
{
if(temp->sum >= 0)
/*
在这里已经匹配成功了,执行想执行的操作即可,怎么改看题目需求+
*/
{
cnt += temp->sum;
temp->sum = -1;
}
else break;
temp = temp->fail;
}
}
}
int main()
{
cnt = 0;
int n;
cin>>n;
char c[101];
root = newnode();
for(int i = 0 ;i < n;i++){
scanf("%s",c);
Insert(c);
}
getfail();
int m ;
cin>> m;
for(int i = 0;i ICPC惨败,还是得努力啊!!!!