维特比viterbi算法
先举个例子来解释
从前有个村儿,村里的人的身体情况只有两种可能:健康或者发烧。
假设这个村儿的人没有体温计或者百度这种神奇东西,他唯一判断他身体情况的途径就是到村头我的偶像金正月的小诊所询问。
月儿通过询问村民的感觉,判断她的病情,再假设村民只会回答正常、头晕或冷。
有一天村里奥巴驴就去月儿那去询问了。
第一天她告诉月儿她感觉正常。
第二天她告诉月儿感觉有点冷。
第三天她告诉月儿感觉有点头晕。
那么问题来了,月儿如何根据阿驴的描述的情况,推断出这三天中阿驴的一个身体状态呢?
为此月儿上百度搜 google ,一番狂搜,发现维特比算法正好能解决这个问题。月儿乐了。
已知情况:(假如模型已经学出这些参数概率)
隐含的身体状态 = { 健康 , 发烧 }
可观察的感觉状态 = { 正常 , 冷 , 头晕 }
月儿预判的阿驴身体状态的概率分布 = { 健康:0.6 , 发烧: 0.4 }
月儿认为的阿驴身体健康状态的转换概率分布 = {
健康->健康: 0.7 ,
健康->发烧: 0.3 ,
发烧->健康:0.4 ,
发烧->发烧: 0.6
}
健康 发烧 健康 0.7 0.4 发烧 0.3 0.6
月儿认为的在相应健康状况条件下,阿驴的感觉的概率分布 = {
健康,正常:0.5 ,冷 :0.4 ,头晕: 0.1 ;
发烧,正常:0.1 ,冷 :0.3 ,头晕: 0.6
}
健康 发烧 正常 0.5 0.1 冷 0.4 0.3 头晕 0.1 0.6
阿驴连续三天的身体感觉依次是: 正常、冷、头晕 (即观测)。
根据Viterbi理论,后一天的状态会依赖与前一天的状态和当前的观测状态。那么只要根据第一天的正常状态一次推算,找出到达第三天头晕状态的最大的概率,就可以知道这三天的身体变化状态。
- 初始情况
P(健康)=0.6,P(发烧)=0.4
- 第一天的情况
计算第一天身体 “正常” 情况下最有可能的身体状态
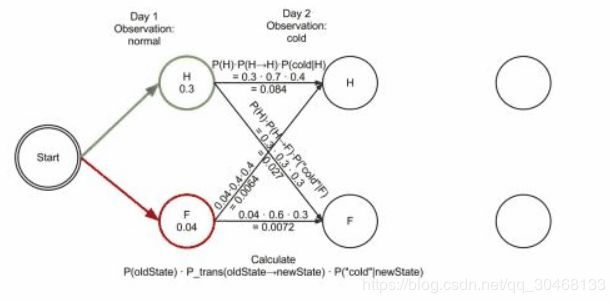
P(健康)=P(正常|健康) x P(健康|初始) =0.5x0.6=0.3
P(发烧)=P(正常|发烧) x P(发烧|初始) =0.1x0.4=0.04
那么第一天最有可能的身体状态是:健康
- 第二天的情况
计算第二天 “冷” 情况下最有可能的身体状态
P(健康)=P(冷|健康) x max{ 前一天健康 x (健康-->健康), 前一天发烧 x (发烧-->健康) } = 0.4 x max(0.3*0.7 , 0.04*0.4)=0.084
P(发烧)=P(冷|发烧) x max{ 前一天健康 x (健康-->发烧), 前一天发烧 x (发烧-->发烧) } = 0.3 x max(0.3*0.3 , 0.04*0.6)=0.024
所以第二天最有可能的身体状态是:健康
- 第三天的身体状态
计算第三天 “头晕” 情况下最有可能的身体状态
P(健康)=P(头晕|健康) x max{ 前一天健康 x (健康-->健康), 前一天发烧 x (发烧-->健康) } = 0.1 x max(0.084*0.7 , 0.027*0.4)=0.00588
P(发烧)=P(头晕|发烧) x max{ 前一天健康 x (健康-->发烧), 前一天发烧 x (发烧-->发烧) } = 0.6 x max(0.084*0.3 , 0.027*0.6)=0.01512
所以第二天最有可能的身体状态是:发烧
所以最终的身体状态变化序列为:健康---健康---发烧
回溯:
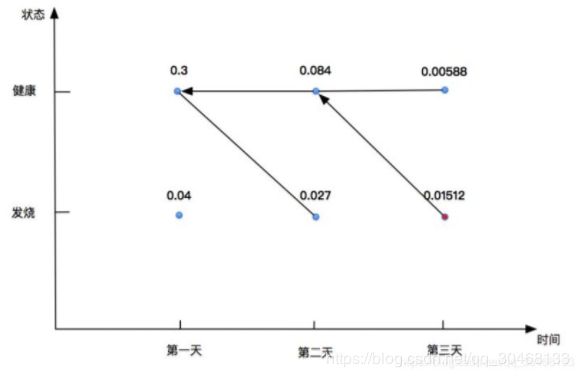
这儿的箭头指向就是一个回溯查询小本本的过程,我们在编写算法的时候,其实也得注意,每一个概率最大的单条路径上都要把前一个状态记录下来。
最终的动图如下:

分步:


最后讲一下beam search和viterbi的区别:
- beam search 的操作属于贪心算法思想,不一定reach到全局最优解。因为考虑到seq2seq的inference阶段的搜索空间过大而导致的搜索效率降低,所以即使是一个相对的局部优解在工程上也是可接受的。
- viterbi属于动态规划思想,保证有最优解。viterbi应用到宽度较小的graph最优寻径是非常favorable的,毕竟,能reach到全局最优为何不用!
# five elements for HMM
states = ('Healthy', 'Fever')
observations = ('normal', 'cold', 'dizzy')
start_probability = {'Healthy': 0.6, 'Fever': 0.4}
transition_probability = {
'Healthy' : {'Healthy': 0.7, 'Fever': 0.3},
'Fever' : {'Healthy': 0.4, 'Fever': 0.6},
}
emission_probability = {
'Healthy' : {'normal': 0.5, 'cold': 0.4, 'dizzy': 0.1},
'Fever' : {'normal': 0.1, 'cold': 0.3, 'dizzy': 0.6},
}
def Viterbit(obs, states, s_pro, t_pro, e_pro):
path = { s:[] for s in states} # init path: path[s] represents the path ends with s
curr_pro = {}
for s in states:
curr_pro[s] = s_pro[s]*e_pro[s][obs[0]]
for i in xrange(1, len(obs)):
last_pro = curr_pro
curr_pro = {}
for curr_state in states:
max_pro, last_sta = max(((last_pro[last_state]*t_pro[last_state][curr_state]*e_pro[curr_state][obs[i]], last_state)
for last_state in states))
curr_pro[curr_state] = max_pro
path[curr_state].append(last_sta)
# find the final largest probability
max_pro = -1
max_path = None
for s in states:
path[s].append(s)
if curr_pro[s] > max_pro:
max_path = path[s]
max_pro = curr_pro[s]
# print '%s: %s'%(curr_pro[s], path[s]) # different path and their probability
return max_path
if __name__ == '__main__':
obs = ['normal', 'cold', 'dizzy']
print Viterbit(obs, states, start_probability, transition_probability, emission_probability)