Hive简易教程
这里已经默认你的系统成功安装Hive。
下面介绍的例子用到的数据可以在我的网盘下载:
链接:https://pan.baidu.com/s/1GiP1ZWn5oVVTTfNiRSVVZg 密码:4n82
1. 使用Hive
在HDFS上创建Hive所需路径/tmp和/user/hive/warehouse
hadoop fs -mkdir /tmp
hadoop fs -mkdir /user/hive/warehouse修改上述路径的访问权限,使用户组具有写入权限
hadoop fs -chmod g+w /tmp
hadoop fs -chmod g+w /user/hive/warehouse启动Hive
[root@master ~]# hive
Logging initialized using configuration in jar:file:/home/cloudera/parcels/CDH-5.8.2-1.cdh5.8.2.p0.3/jars/hive-common-1.1.0-cdh5.8.2.jar!/hive-log4j.properties
WARNING: Hive CLI is deprecated and migration to Beeline is recommended.
hive>
退出Hive
hive> quit;2. 创建表
数据集:
这里用到的是一个公共数据集,它包含60000次UFO目击事件的数据。这些数据集由下面的字段组成:
(1) Sighting date : UFO目击事件发生的时间。
(2) Recorded date : 报告目击事件的日期,通常与目击事件时间不同。
(3) Location : 目击事件发生的地点。
(4) Shape : UFO形状的简要描述,例如,菱形、发光体、圆筒状。
(5) Duratition : 目击事件的持续时间。
(6) Description : 目击事件的大致描述。
创建表的hql脚本如下,我们保存在createTable.hql文件下:
CREATE TABLE ufodata(sighted STRING, reported STRING, sighting_location STRING,
shape STRING, duration STRING, description STRING COMMENT 'Free text description')
COMMENT 'The UFO data set.';执行hql脚本
hive -f createTable.hql列出所有表
hive> show tables;
OK
ufodata
Time taken: 0.577 seconds, Fetched: 1 row(s)显示与正则表达式 “.*data” 匹配的表
hive> show tables '.*data';
OK
ufodata
Time taken: 0.031 seconds, Fetched: 1 row(s)验证表中各字段的定义:
hive> desc ufodata;
OK
sighted string
reported string
sighting_location string
shape string
duration string
description string
Time taken: 0.157 seconds, Fetched: 6 row(s)更详细地显示对象的描述(可以使用desc formatted ufodata或desc extended ufodata,formatted参数显示的更为友好)
hive> desc formatted ufodata;
OK
# col_name data_type comment
sighted string
reported string
sighting_location string
shape string
duration string
description string
# Detailed Table Information
Database: default
Owner: root
CreateTime: Wed Jul 04 16:18:54 CST 2018
LastAccessTime: UNKNOWN
Protect Mode: None
Retention: 0
Location: hdfs://master.hxdi.com:8020/home/cloudera/etc/user/hive/warehouse/ufodata
Table Type: MANAGED_TABLE
Table Parameters:
COLUMN_STATS_ACCURATE true
numFiles 1
numRows 0
rawDataSize 0
totalSize 75342464
transient_lastDdlTime 1530692335
# Storage Information
SerDe Library: org.apache.hadoop.hive.serde2.lazy.LazySimpleSerDe
InputFormat: org.apache.hadoop.mapred.TextInputFormat
OutputFormat: org.apache.hadoop.hive.ql.io.HiveIgnoreKeyTextOutputFormat
Compressed: No
Num Buckets: -1
Bucket Columns: []
Sort Columns: []
Storage Desc Params:
field.delim \t
serialization.format \t
Time taken: 0.123 seconds, Fetched: 37 row(s)针对UFO数据,我们定义该表中所有字段的数据类型为STRING。和SQL一样,HiveQL也支持多种数据类型:
布尔类型 : BOOLEAN
整数类型 : TINYINT、INT、BIGINT
浮点类型 : FLOAT、DOUBLE
文本类型 : STRING
注意:
在上面例子中,输入格式被指定为TextInputFormat。默认情况下,Hive假设插入表中的所有HDFS文件都以文本文件(TEXTFILE)的形式存在。同时,我们还观察到,表数据存储在之前创建的HDFS目录/user/hive/warehouse下
关于字符大小写:
就像SQL一样,HiveQL对关键字、列名、表名中的字符不区分大小写。按照惯例,SQL语句中的关键字使用大写字母。
3. 在表中插入数据
将UFO数据文件拷贝到HDFS
hadoop fs -put ufo.tsv /tmp/ufo.tsv确认文件已经成功复制到HDFS
[root@master runjar]# hadoop fs -ls /tmp
Found 2 items
drwx-wx-wx - hive supergroup 0 2018-06-02 12:42 /tmp/hive
-rw-r--r-- 2 root supergroup 75342464 2018-07-06 11:15 /tmp/ufo.tsv将/tmp目录下的文件数据插入到ufodata表中
hive> LOAD DATA INPATH '/tmp/ufo.tsv' OVERWRITE INTO TABLE ufodata;
Loading data to table default.ufodata
chgrp: changing ownership of 'hdfs://master.hxdi.com:8020/home/cloudera/etc/user/hive/warehouse/ufodata/ufo.tsv': User does not belong to hive
Table default.ufodata stats: [numFiles=1, numRows=0, totalSize=75342464, rawDataSize=0]
OK
Time taken: 1.105 seconds因为我们使用的文件已经放到了HDFS上,所以单独使用INPATH关键字来指定源文件的位置。我们还可以通过LOCAL INPATH指定位于本地文件系统上的源文件,将它直接导入Hive表中。这样就不必明确地将本地文件系统上的源文件拷贝到HDFS。
在把UFO数据导入ufodata表的Hive语句中,我们指定了OVERWRITE关键字,它会在导入新数据前删除表中原有数据。
如果传给LOAD语句的是HDFS上的数据路径,那么LOAD语句不光会将数据复制到/user/hive/warahouse中,同时也会删掉其原始目录。如果想分析HDFS上被其他程序使用的数据,要么备份一个副本,要么使用EXTERNAL方案。
检查HDFS上存放UFO数据副本的目录
[root@master runjar]# hadoop fs -ls /tmp
Found 1 items
drwxrwxr-x - hadoop supergroup 0 … 16:10 /tmp/hivehadoop插入完数据之后,接下来要验证数据了(这里 -e 表明不需要打开Hive命令行来执行这个查询语句)。
hive -e "select count(*) from ufodata;"执行结果如下:
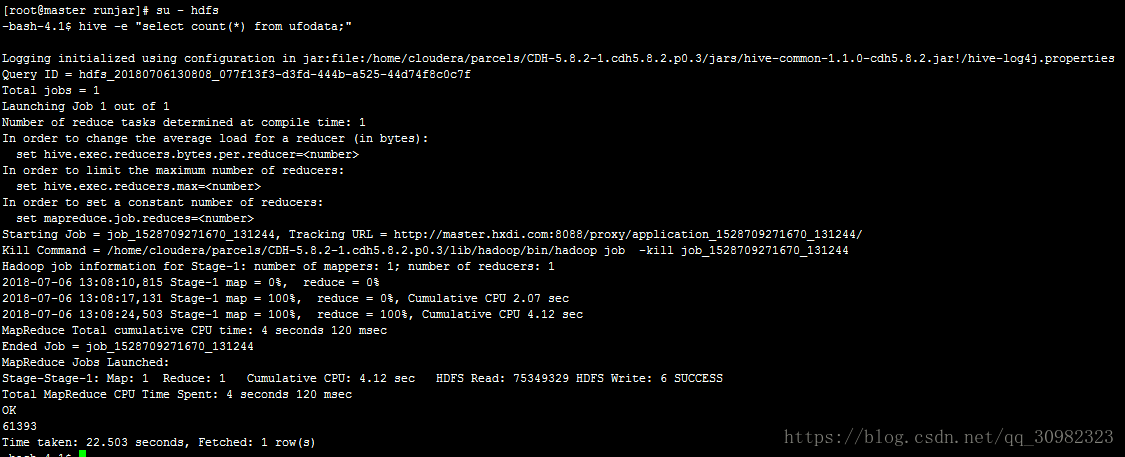
可以在hive命令加上”-S”,这就会过滤掉无关信息,只显示查询结果,如:
hive -S -e “select count(*) from ufodata;”
从sighted列选取出5个值
hive -e "select sighted from ufodata limit 5"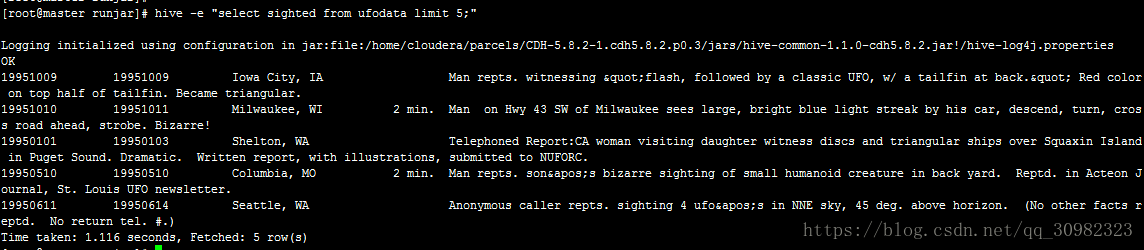
从返回结果看出,我们期望得到的是sighted列的5个值,但最后返回了5行,每行都包含了全部列数据。出现这种问题的原因在于,我们依靠Hive把数据文件以文本文件形式导入表中,却没有考虑各列之间的分隔符。我们的数据文件以tab作为分隔符,但在默认情况下,Hive认为其输入文件的分隔符是ASCII码00(Ctrl + A)。
下面,修正表规范,将下列HiveQL语句保存为commands.hql文件:
DROP TABLE ufodata;
CREATE TABLE ufodata(sighted STRING, reported STRING, sighting_location STRING,
shape STRING, duration STRING, description STRING)
ROW FORMAT DELIMITED
FIELDS TERMINATED BY '\t';
LOAD DATA INPATH '/tmp/ufo.tsv' OVERWRITE INTO TABLE ufodata;将数据拷贝到HDFS:
hadoop fs -put ufo.csv /tmp/ufo.csv执行HIveQL脚本
hive -f commands.hql 
验证表中的数据总行数
hive -e "select count(*) from ufodata"执行结果如下:
OK
61393
Time taken: 22.454 seconds, Fetched: 1 row(s)验证reported列的内容:
hive -e "select reported from ufodata limit 5"执行结果如下:
Logging initialized using configuration in jar:file:/home/cloudera/parcels/CDH-5.8.2-1.cdh5.8.2.p0.3/jars/hive-common-1.1.0-cdh5.8.2.jar!/hive-log4j.properties
OK
19951009
19951011
19950103
19950510
19950614
Time taken: 1.033 seconds, Fetched: 5 row(s)新定义的表规约与前一个的主要区别在于,后者用到了ROW FORMAT DELIMITED
和FIELDS TERMINATED BY 命令。第一条命令告诉Hive每行数据包含多个有界字段,而第二条命令制定了真正的分隔符。可以看出,我们可以用明确地ASCII码也可以用常用的\t符号表示tab(不要将\t错写为\T)。
Hive表是一个逻辑概念
从上面的执行可以看出,把数据导入表所用的时间和创建表规约所用的时间基本一样,但是,统计总行数这样的简单任务却用了较长时间。输出结果也表明,表的创建和数据导入并没有真正引起MapReduce作业的执行,这就解释了为什么执行这些任务所用的时间较短。
把数据导入Hive表的过程不同于我们依据传统数据库经验给出的判断。虽然Hive把数据文件拷入工作路劲,但事实上它没有在这个时候将输入数据插入表中各行。与之相反,它以源数据为基础创建一批元数据,后续HiveQL查询将用到这些元数据。
如此说来,CREATE TABLE和LOAD DATA语句都不会创建实际的表数据,只是生成一些元数据。当Hive使用HiveQL转换成的MapReduce作业访问概念上存储在表中的数据时,将会用到这些元数据。
4. 创建外部表
截至目前,我们学习了如何把Hive有效控制的文件数据直接导入到Hive表。然而,我们也可以为Hive外部文件数据创建表。在需要使用Hive处理外部程序写入和管理的数据或数据存储于Hive仓库之外的路径时,这种方法特别有用。用户不必把这些文件移到Hive仓库目录下,用户删除表时也不会影响到这些文件的可用性。
将以下内容存入states.hql脚本文件(注意关键字EXTERNAL)
CREATE EXTERNAL TABLE states(abbreviation STRING, full_name STRING)
ROW FORMAT DELIMITED
FIELDS TERMINATED BY '\t'
LOCATION '/tmp/states';
创建/tmp/states目录,并将states.txt拷贝到HDFS,然后确认该文件确实存在:
[root@master runjar]# hadoop fs -mkdir /tmp/states
[root@master runjar]# hadoop fs -put states.txt /tmp/states/states.txt
[root@master runjar]# hadoop fs -du -h /tmp/states
654 1.3 K /tmp/states/states.txt执行HiveQL脚本
[root@master runjar]# hive -f states.hql
Logging initialized using configuration in jar:file:/home/cloudera/parcels/CDH-5.8.2-1.cdh5.8.2.p0.3/jars/hive-common-1.1.0-cdh5.8.2.jar!/hive-log4j.properties
OK
Time taken: 0.794 seconds检查源数据文件(源数据仍然存在)
[root@master runjar]# hadoop fs -ls /tmp/states
Found 1 items
-rw-r--r-- 2 root supergroup 654 2018-07-07 15:49 /tmp/states/states.txt对刚创建的表执行一次示例查询:
[root@master runjar]# su - hdfs
-bash-4.1$ hive -e "select full_name from states where abbreviation like 'CA'"
Logging initialized using configuration in jar:file:/home/cloudera/parcels/CDH-5.8.2-1.cdh5.8.2.p0.3/jars/hive-common-1.1.0-cdh5.8.2.jar!/hive-log4j.properties
Query ID = hdfs_20180707155656_b1f4fc4d-dea3-45f7-9e44-5464a4eebd13
Total jobs = 1
Launching Job 1 out of 1
Number of reduce tasks is set to 0 since there's no reduce operator
Starting Job = job_1528709271670_137004, Tracking URL = http://master.hxdi.com:8088/proxy/application_1528709271670_137004/
Kill Command = /home/cloudera/parcels/CDH-5.8.2-1.cdh5.8.2.p0.3/lib/hadoop/bin/hadoop job -kill job_1528709271670_137004
Hadoop job information for Stage-1: number of mappers: 1; number of reducers: 0
2018-07-07 15:56:30,240 Stage-1 map = 0%, reduce = 0%
2018-07-07 15:56:36,548 Stage-1 map = 100%, reduce = 0%, Cumulative CPU 2.18 sec
MapReduce Total cumulative CPU time: 2 seconds 180 msec
Ended Job = job_1528709271670_137004
MapReduce Jobs Launched:
Stage-Stage-1: Map: 1 Cumulative CPU: 2.18 sec HDFS Read: 3884 HDFS Write: 11 SUCCESS
Total MapReduce CPU Time Spent: 2 seconds 180 msec
OK
California
Time taken: 15.109 seconds, Fetched: 1 row(s)
从上面的执行结果可以看出外部表和非外部表的区别:在非外部表的情况下,创建表的语句不会吧数据插入到表中,而是由后续的LOAD DATA或INSERT语句向表中插入数据。在定义表时用LOCATION指定源文件位置,可以在创建表的同时把数据插入到表中。
5. 执行表连接(JOIN)
我们想从一系列的记录中提取sighted和location字段,但不想使用location字段的原始数据,而是想把该字段映射为州名全称。我们创建的HiveQL文件执行的就是这个查询任务。HiveQL使用标准的JOIN关键字指定联结语句,并用ON子句指定匹配条件。
SELECT t1.sighted, t2.full_name
FROM ufodata t1 JOIN states t2
ON (LOWER(t2.abbreviation) = LOWER(SUBSTR(t1.sighting_location, (LENGTH(t1.sighting_location) - 1))))
LIMIT 5;执行结果如下:
MapReduce Total cumulative CPU time: 2 seconds 220 msec
Ended Job = job_1528709271670_137362
MapReduce Jobs Launched:
Stage-Stage-3: Map: 1 Cumulative CPU: 2.22 sec HDFS Read: 72553 HDFS Write: 91 SUCCESS
Total MapReduce CPU Time Spent: 2 seconds 220 msec
OK
19951009 Iowa
19951010 Wisconsin
19950101 Washington
19950510 Missouri
19950611 Washington
Time taken: 19.718 seconds, Fetched: 5 row(s)注意:
Hive还提供了类似RLIKE和REGEXP_EXTRACT的函数,这些函数支持在Hive中使用类似Java中的正则表达式,可以使用正则表达式改写上面的联结语句。
6. Hive和SQL视图
Hive还支持另一个功能强大的SQL特性—–视图。在用户通过SELECT语句指定逻辑表(不是静态表)的内容时,视图特别有用,后续的查询语句就可针对这个包含基础数据的动态视图运行。
我们可以使用视图隐藏相关的查询复杂性,例如上例中的联结操作的复杂性。接下来,我们创建视图实现该功能。
将下列语句保存为view.hql脚本
CREATE VIEW IF NOT EXISTS usa_sightings(sighted, reported, shape, state)
AS SELECT t1.sighted, t1.reported, t1.shape, t2.full_name
FROM ufodata t1 JOIN states t2
ON (LOWER(t2.abbreviation) = LOWER(SUBSTR(t1.sighting_location, (LENGTH(t1.sighting_location) - 1)))) ;
上面的语句与CREATE TABLE有两个关键区别:
(1) 列定义中仅包括列名,不包括数据类型,相关查询会确定各列的数据类型。
(2) 通过AS子句中指定的SELECT语句生成视图。
此外,IF NOT EXISTS子句是可选的(该子句也可以用于CREATE TABLE语句),意味着,如果该视图已经存在,Hive会忽视CREATE VIEW语句。如果不使用这个子句,重复创建相同的视图会引发错误。
执行view.hql脚本
-bash-4.1$ vi view.hql
-bash-4.1$ hive -f view.hql
Logging initialized using configuration in jar:file:/home/cloudera/parcels/CDH-5.8.2-1.cdh5.8.2.p0.3/jars/hive-common-1.1.0-cdh5.8.2.jar!/hive-log4j.properties
OK
Time taken: 1.122 seconds再次执行view.hql脚本(两次执行该脚本创建视图,验证了使用IF NOT EXISTS子句可以防范某些错误)
-bash-4.1$ hive -f view.hql
Logging initialized using configuration in jar:file:/home/cloudera/parcels/CDH-5.8.2-1.cdh5.8.2.p0.3/jars/hive-common-1.1.0-cdh5.8.2.jar!/hive-log4j.properties
OK
Time taken: 1.239 seconds
针对该视图执行一个测试查询
hive -e "select count(state) from usa_sightings where state = 'California'"查询结果如下:
Hadoop job information for Stage-2: number of mappers: 1; number of reducers: 1
2018-07-07 17:34:52,196 Stage-2 map = 0%, reduce = 0%
2018-07-07 17:34:59,694 Stage-2 map = 100%, reduce = 0%, Cumulative CPU 3.83 sec
2018-07-07 17:35:07,017 Stage-2 map = 100%, reduce = 100%, Cumulative CPU 6.44 sec
MapReduce Total cumulative CPU time: 6 seconds 440 msec
Ended Job = job_1528709271670_137492
MapReduce Jobs Launched:
Stage-Stage-2: Map: 1 Reduce: 1 Cumulative CPU: 6.44 sec HDFS Read: 75355041 HDFS Write: 5 SUCCESS
Total MapReduce CPU Time Spent: 6 seconds 440 msec
OK
7599
Time taken: 29.324 seconds, Fetched: 1 row(s)7. 导出查询结果
刚才,我们把大量数据导入Hive并通过查询语句从中提取少量数据。我们也可以导出大数据集,下面来看个例子。
重新创建刚才用到的视图:
hive -f view.hql 将下列语句保存为export.hql文件
INSERT OVERWRITE DIRECTORY '/tmp/out'
SELECT reported, shape, state
FROM usa_sightings
WHERE state = 'California' ;这个脚本注意两点:
(1) OVERWRITE修饰语是可选的,它指明是否要删除输出目录下的已有内容。
(2) 可以在DIRECTORY前添加一个修饰语“local”,这样数据数据就写入本地文件系统而不是HDFS
执行export.hql脚本
hive -f export.hql查看指定的输出
-bash-4.1$ hadoop fs -ls /tmp/out
Found 1 items
-rwxrwxrwt 2 hdfs supergroup 210901 2018-07-08 10:56 /tmp/out/000000_0
8. 表分区
我们之前提到,在一段很长的时间内,人们对糟糕的联结语句评价很差,因为它会导致关系数据库耗费大量时间去完成不必要的工作。此外,也会听到关于查询的类似非议,因为查询操作需要执行全表扫描,也就是说,需要逐一访问表中每行的数据,而无法使用索引直接访问感兴趣的行。
对于存储在HDFS并映射到Hive表中的数据,一般情况下基本上都依赖于全表扫描。由于无法将数据分割为更有规律的、可直接访问用户感兴趣的数据子集的结构,Hive只能处理整个数据集。对大约为70MB的UFO文件来讲,问题并不大,因为Hive只用十几秒就能完成整个文件的处理任务。但是,如果要处理的文件规模是UFO文件大小的1000倍,情况就会变得很糟糕。
就像传统关系型数据库一样,Hive可以基于虚拟列的值对表进行分区操作,这些虚拟列还会用于后续的查询语句。
特别是,当新建一个表时,用户可指定一列或多列作为分区列,然后在把数据导入表时,这些列的值还会用于后续的查询语句。
对每天都要接收大量数据的表而言,最常用的分区策略就是使用日期列作为分区列。之后我们就可以限制查询语句只处理某个特定分区内的数据。Hive在后台把每个分区的数据存储于自身路径和文件中,这样,它就可以使用MapReduce作业只处理用户感兴趣的数据。通过使用多个分区列,用户可以创建一个多层结构,对于需要频繁查询一小部分数据的大表而言,很有必要花一些时间选择一个最佳的分区策略。
对于UFO数据集而言,我们使用目击事件发生的年份作为分区值,接下来,我们将为UFO数据新建一个表,以说明表分区的实用性:
把下列查询语句保存到 createpartition.hql 脚本文件中:
CREATE TABLE partufo(sighted STRING, reported STRING, sighting_location STRING,
shape STRING, duration STRING, description STRING)
PARTITIONED BY (year STRING)
ROW FORMAT DELIMITED
FIELDS TERMINATED BY '\t'
把下列查询语句保存到 insertpartition.hql 脚本文件:
SET hive.exec.dynamic.partition=true;
SET hive.exec.dynamic.partition.mode=nonstrict;
INSERT OVERWRITE TABLE partufo partition (year)
SELECT sighted, reported, sighting_location, shape,
duration, description, SUBSTR(TRIM(sighted), 1, 4) FROM ufodata;
这个脚本用到了Hive的一个新功能—–动态分区。动态分区支持基于查询参数自动推断出需要创建的分区。partufo表中的分区字段为year,Hive会自动根据SUBSTR(TRIM(sighted), 1, 4) 不同值来创建分区,并且Hive会根据select语句最后一个字段作为动态分区的依据。
Hive默认没有开启自动分区,第一句设置true表示开启自动分区功能。Hive默认不允许所有的分区都是动态的,第二句设置nonstrict表示所有的分区都是动态的。
执行这两个脚本:
hive -f createpartition.hql
hive -f insertpartition.hql在执行完第一个脚本之后,通过检查表结构,多了一列(year),这样当在where子句中指定条件时,系统会同样对year列进行处理,即使该列并不存于硬盘数据文件中。
对某个分区数据执行count命令:
-bash-4.1$ hive -e "select count(*) from partufo where year = '1989'"
Logging initialized using configuration in jar:file:/home/cloudera/parcels/CDH-5.8.2-1.cdh5.8.2.p0.3/jars/hive-common-1.1.0-cdh5.8.2.jar!/hive-log4j.properties
Query ID = hdfs_20180708124545_5c4d197a-b3e6-4134-8803-ce6654dd30a0
Total jobs = 1
Launching Job 1 out of 1
Number of reduce tasks determined at compile time: 1
In order to change the average load for a reducer (in bytes):
set hive.exec.reducers.bytes.per.reducer=<number>
In order to limit the maximum number of reducers:
set hive.exec.reducers.max=<number>
In order to set a constant number of reducers:
set mapreduce.job.reduces=<number>
Starting Job = job_1528709271670_142301, Tracking URL = http://master.hxdi.com:8088/proxy/application_1528709271670_142301/
Kill Command = /home/cloudera/parcels/CDH-5.8.2-1.cdh5.8.2.p0.3/lib/hadoop/bin/hadoop job -kill job_1528709271670_142301
Hadoop job information for Stage-1: number of mappers: 1; number of reducers: 1
2018-07-08 12:45:44,518 Stage-1 map = 0%, reduce = 0%
2018-07-08 12:45:50,815 Stage-1 map = 100%, reduce = 0%, Cumulative CPU 1.59 sec
2018-07-08 12:45:57,103 Stage-1 map = 100%, reduce = 100%, Cumulative CPU 3.7 sec
MapReduce Total cumulative CPU time: 3 seconds 700 msec
Ended Job = job_1528709271670_142301
MapReduce Jobs Launched:
Stage-Stage-1: Map: 1 Reduce: 1 Cumulative CPU: 3.7 sec HDFS Read: 428657 HDFS Write: 4 SUCCESS
Total MapReduce CPU Time Spent: 3 seconds 700 msec
OK
249
Time taken: 21.104 seconds, Fetched: 1 row(s)在未分区表上执行类似查询:
-bash-4.1$ hive -e "select count(*) from ufodata where sighted like '1989%'"
Logging initialized using configuration in jar:file:/home/cloudera/parcels/CDH-5.8.2-1.cdh5.8.2.p0.3/jars/hive-common-1.1.0-cdh5.8.2.jar!/hive-log4j.properties
Query ID = hdfs_20180708124646_46bd223c-80cd-498d-b36e-71128d0798e1
Total jobs = 1
Launching Job 1 out of 1
Number of reduce tasks determined at compile time: 1
In order to change the average load for a reducer (in bytes):
set hive.exec.reducers.bytes.per.reducer=<number>
In order to limit the maximum number of reducers:
set hive.exec.reducers.max=<number>
In order to set a constant number of reducers:
set mapreduce.job.reduces=<number>
Starting Job = job_1528709271670_142302, Tracking URL = http://master.hxdi.com:8088/proxy/application_1528709271670_142302/
Kill Command = /home/cloudera/parcels/CDH-5.8.2-1.cdh5.8.2.p0.3/lib/hadoop/bin/hadoop job -kill job_1528709271670_142302
Hadoop job information for Stage-1: number of mappers: 1; number of reducers: 1
2018-07-08 12:47:02,598 Stage-1 map = 0%, reduce = 0%
2018-07-08 12:47:09,949 Stage-1 map = 100%, reduce = 0%, Cumulative CPU 2.88 sec
2018-07-08 12:47:16,235 Stage-1 map = 100%, reduce = 100%, Cumulative CPU 4.92 sec
MapReduce Total cumulative CPU time: 4 seconds 920 msec
Ended Job = job_1528709271670_142302
MapReduce Jobs Launched:
Stage-Stage-1: Map: 1 Reduce: 1 Cumulative CPU: 4.92 sec HDFS Read: 75350088 HDFS Write: 4 SUCCESS
Total MapReduce CPU Time Spent: 4 seconds 920 msec
OK
249
Time taken: 21.972 seconds, Fetched: 1 row(s)
可以看出,两次查询结果完全一致,这就证实了我们的分区策略按照预期工作。我们还注意到,对分区表的查询要稍快于对非分区表的查询,尽管两者速度差别并不明显。这可能原因在于处理这种小规模数据集的时候,MapRedece的启动时间在整个作业的运行时间中占据较大的比率。
列出保存分区表的Hive目录下的所有文件(我这里用的是CDH,如果用的是原生版Hive,下面语句改为hadoop fs -ls /user/hive/warehouse/partufo):
-bash-4.1$ hadoop fs -ls /home/cloudera/etc/user/hive/warehouse/partufo
Found 100 items
drwxrwxrwt - hdfs hive 0 2018-07-08 12:42 /home/cloudera/etc/user/hive/warehouse/partufo/year=0000
drwxrwxrwt - hdfs hive 0 2018-07-08 12:42 /home/cloudera/etc/user/hive/warehouse/partufo/year=1400
drwxrwxrwt - hdfs hive 0 2018-07-08 12:42 /home/cloudera/etc/user/hive/warehouse/partufo/year=1762
drwxrwxrwt - hdfs hive 0 2018-07-08 12:42 /home/cloudera/etc/user/hive/warehouse/partufo/year=1790
drwxrwxrwt - hdfs hive 0 2018-07-08 12:42 /home/cloudera/etc/user/hive/warehouse/partufo/year=1860
drwxrwxrwt - hdfs hive 0 2018-07-08 12:42 /home/cloudera/etc/user/hive/warehouse/partufo/year=1864
drwxrwxrwt - hdfs hive 0 2018-07-08 12:42 /home/cloudera/etc/user/hive/warehouse/partufo/year=1865
drwxrwxrwt - hdfs hive 0 2018-07-08 12:42 /home/cloudera/etc/user/hive/warehouse/partufo/year=1871
drwxrwxrwt - hdfs hive 0 2018-07-08 12:42 /home/cloudera/etc/user/hive/warehouse/partufo/year=1880
drwxrwxrwt - hdfs hive 0 2018-07-08 12:42 /home/cloudera/etc/user/hive/warehouse/partufo/year=1896
drwxrwxrwt - hdfs hive 0 2018-07-08 12:42 /home/cloudera/etc/user/hive/warehouse/partufo/year=1897
drwxrwxrwt - hdfs hive 0 2018-07-08 12:42 /home/cloudera/etc/user/hive/warehouse/partufo/year=1899
drwxrwxrwt - hdfs hive 0 2018-07-08 12:42 /home/cloudera/etc/user/hive/warehouse/partufo/year=1901
drwxrwxrwt - hdfs hive 0 2018-07-08 12:42 /home/cloudera/etc/user/hive/warehouse/partufo/year=1905
drwxrwxrwt - hdfs hive 0 2018-07-08 12:42 /home/cloudera/etc/user/hive/warehouse/partufo/year=1906
drwxrwxrwt - hdfs hive 0 2018-07-08 12:42 /home/cloudera/etc/user/hive/warehouse/partufo/year=1910
drwxrwxrwt - hdfs hive 0 2018-07-08 12:42 /home/cloudera/etc/user/hive/warehouse/partufo/year=1914
drwxrwxrwt - hdfs hive 0 2018-07-08 12:42 /home/cloudera/etc/user/hive/warehouse/partufo/year=1916
drwxrwxrwt - hdfs hive 0 2018-07-08 12:42 /home/cloudera/etc/user/hive/warehouse/partufo/year=1920
drwxrwxrwt - hdfs hive 0 2018-07-08 12:42 /home/cloudera/etc/user/hive/warehouse/partufo/year=1922
drwxrwxrwt - hdfs hive 0 2018-07-08 12:42 /home/cloudera/etc/user/hive/warehouse/partufo/year=1925
drwxrwxrwt - hdfs hive 0 2018-07-08 12:42 /home/cloudera/etc/user/hive/warehouse/partufo/year=1929
drwxrwxrwt - hdfs hive 0 2018-07-08 12:42 /home/cloudera/etc/user/hive/warehouse/partufo/year=1930
drwxrwxrwt - hdfs hive 0 2018-07-08 12:42 /home/cloudera/etc/user/hive/warehouse/partufo/year=1931
drwxrwxrwt - hdfs hive 0 2018-07-08 12:42 /home/cloudera/etc/user/hive/warehouse/partufo/year=1933
drwxrwxrwt - hdfs hive 0 2018-07-08 12:42 /home/cloudera/etc/user/hive/warehouse/partufo/year=1934
drwxrwxrwt - hdfs hive 0 2018-07-08 12:42 /home/cloudera/etc/user/hive/warehouse/partufo/year=1935
drwxrwxrwt - hdfs hive 0 2018-07-08 12:42 /home/cloudera/etc/user/hive/warehouse/partufo/year=1936
drwxrwxrwt - hdfs hive 0 2018-07-08 12:42 /home/cloudera/etc/user/hive/warehouse/partufo/year=1937
drwxrwxrwt - hdfs hive 0 2018-07-08 12:42 /home/cloudera/etc/user/hive/warehouse/partufo/year=1939
drwxrwxrwt - hdfs hive 0 2018-07-08 12:42 /home/cloudera/etc/user/hive/warehouse/partufo/year=1941
drwxrwxrwt - hdfs hive 0 2018-07-08 12:42 /home/cloudera/etc/user/hive/warehouse/partufo/year=1942
drwxrwxrwt - hdfs hive 0 2018-07-08 12:42 /home/cloudera/etc/user/hive/warehouse/partufo/year=1943
drwxrwxrwt - hdfs hive 0 2018-07-08 12:42 /home/cloudera/etc/user/hive/warehouse/partufo/year=1944
drwxrwxrwt - hdfs hive 0 2018-07-08 12:42 /home/cloudera/etc/user/hive/warehouse/partufo/year=1945
drwxrwxrwt - hdfs hive 0 2018-07-08 12:42 /home/cloudera/etc/user/hive/warehouse/partufo/year=1946
drwxrwxrwt - hdfs hive 0 2018-07-08 12:42 /home/cloudera/etc/user/hive/warehouse/partufo/year=1947
drwxrwxrwt - hdfs hive 0 2018-07-08 12:42 /home/cloudera/etc/user/hive/warehouse/partufo/year=1948
drwxrwxrwt - hdfs hive 0 2018-07-08 12:42 /home/cloudera/etc/user/hive/warehouse/partufo/year=1949
drwxrwxrwt - hdfs hive 0 2018-07-08 12:42 /home/cloudera/etc/user/hive/warehouse/partufo/year=1950
drwxrwxrwt - hdfs hive 0 2018-07-08 12:42 /home/cloudera/etc/user/hive/warehouse/partufo/year=1951
drwxrwxrwt - hdfs hive 0 2018-07-08 12:42 /home/cloudera/etc/user/hive/warehouse/partufo/year=1952
drwxrwxrwt - hdfs hive 0 2018-07-08 12:42 /home/cloudera/etc/user/hive/warehouse/partufo/year=1953
drwxrwxrwt - hdfs hive 0 2018-07-08 12:42 /home/cloudera/etc/user/hive/warehouse/partufo/year=1954
drwxrwxrwt - hdfs hive 0 2018-07-08 12:42 /home/cloudera/etc/user/hive/warehouse/partufo/year=1955
drwxrwxrwt - hdfs hive 0 2018-07-08 12:42 /home/cloudera/etc/user/hive/warehouse/partufo/year=1956
drwxrwxrwt - hdfs hive 0 2018-07-08 12:42 /home/cloudera/etc/user/hive/warehouse/partufo/year=1957
drwxrwxrwt - hdfs hive 0 2018-07-08 12:42 /home/cloudera/etc/user/hive/warehouse/partufo/year=1958
drwxrwxrwt - hdfs hive 0 2018-07-08 12:42 /home/cloudera/etc/user/hive/warehouse/partufo/year=1959
drwxrwxrwt - hdfs hive 0 2018-07-08 12:42 /home/cloudera/etc/user/hive/warehouse/partufo/year=1960
drwxrwxrwt - hdfs hive 0 2018-07-08 12:42 /home/cloudera/etc/user/hive/warehouse/partufo/year=1961
drwxrwxrwt - hdfs hive 0 2018-07-08 12:42 /home/cloudera/etc/user/hive/warehouse/partufo/year=1962
drwxrwxrwt - hdfs hive 0 2018-07-08 12:42 /home/cloudera/etc/user/hive/warehouse/partufo/year=1963
drwxrwxrwt - hdfs hive 0 2018-07-08 12:42 /home/cloudera/etc/user/hive/warehouse/partufo/year=1964
drwxrwxrwt - hdfs hive 0 2018-07-08 12:42 /home/cloudera/etc/user/hive/warehouse/partufo/year=1965
drwxrwxrwt - hdfs hive 0 2018-07-08 12:42 /home/cloudera/etc/user/hive/warehouse/partufo/year=1966
drwxrwxrwt - hdfs hive 0 2018-07-08 12:42 /home/cloudera/etc/user/hive/warehouse/partufo/year=1967
drwxrwxrwt - hdfs hive 0 2018-07-08 12:42 /home/cloudera/etc/user/hive/warehouse/partufo/year=1968
drwxrwxrwt - hdfs hive 0 2018-07-08 12:42 /home/cloudera/etc/user/hive/warehouse/partufo/year=1969
drwxrwxrwt - hdfs hive 0 2018-07-08 12:42 /home/cloudera/etc/user/hive/warehouse/partufo/year=1970
drwxrwxrwt - hdfs hive 0 2018-07-08 12:42 /home/cloudera/etc/user/hive/warehouse/partufo/year=1971
drwxrwxrwt - hdfs hive 0 2018-07-08 12:42 /home/cloudera/etc/user/hive/warehouse/partufo/year=1972
drwxrwxrwt - hdfs hive 0 2018-07-08 12:42 /home/cloudera/etc/user/hive/warehouse/partufo/year=1973
drwxrwxrwt - hdfs hive 0 2018-07-08 12:42 /home/cloudera/etc/user/hive/warehouse/partufo/year=1974
drwxrwxrwt - hdfs hive 0 2018-07-08 12:42 /home/cloudera/etc/user/hive/warehouse/partufo/year=1975
drwxrwxrwt - hdfs hive 0 2018-07-08 12:42 /home/cloudera/etc/user/hive/warehouse/partufo/year=1976
drwxrwxrwt - hdfs hive 0 2018-07-08 12:42 /home/cloudera/etc/user/hive/warehouse/partufo/year=1977
drwxrwxrwt - hdfs hive 0 2018-07-08 12:42 /home/cloudera/etc/user/hive/warehouse/partufo/year=1978
drwxrwxrwt - hdfs hive 0 2018-07-08 12:42 /home/cloudera/etc/user/hive/warehouse/partufo/year=1979
drwxrwxrwt - hdfs hive 0 2018-07-08 12:42 /home/cloudera/etc/user/hive/warehouse/partufo/year=1980
drwxrwxrwt - hdfs hive 0 2018-07-08 12:42 /home/cloudera/etc/user/hive/warehouse/partufo/year=1981
drwxrwxrwt - hdfs hive 0 2018-07-08 12:42 /home/cloudera/etc/user/hive/warehouse/partufo/year=1982
drwxrwxrwt - hdfs hive 0 2018-07-08 12:42 /home/cloudera/etc/user/hive/warehouse/partufo/year=1983
drwxrwxrwt - hdfs hive 0 2018-07-08 12:42 /home/cloudera/etc/user/hive/warehouse/partufo/year=1984
drwxrwxrwt - hdfs hive 0 2018-07-08 12:42 /home/cloudera/etc/user/hive/warehouse/partufo/year=1985
drwxrwxrwt - hdfs hive 0 2018-07-08 12:42 /home/cloudera/etc/user/hive/warehouse/partufo/year=1986
drwxrwxrwt - hdfs hive 0 2018-07-08 12:42 /home/cloudera/etc/user/hive/warehouse/partufo/year=1987
drwxrwxrwt - hdfs hive 0 2018-07-08 12:42 /home/cloudera/etc/user/hive/warehouse/partufo/year=1988
drwxrwxrwt - hdfs hive 0 2018-07-08 12:42 /home/cloudera/etc/user/hive/warehouse/partufo/year=1989
drwxrwxrwt - hdfs hive 0 2018-07-08 12:42 /home/cloudera/etc/user/hive/warehouse/partufo/year=1990
drwxrwxrwt - hdfs hive 0 2018-07-08 12:42 /home/cloudera/etc/user/hive/warehouse/partufo/year=1991
drwxrwxrwt - hdfs hive 0 2018-07-08 12:42 /home/cloudera/etc/user/hive/warehouse/partufo/year=1992
drwxrwxrwt - hdfs hive 0 2018-07-08 12:42 /home/cloudera/etc/user/hive/warehouse/partufo/year=1993
drwxrwxrwt - hdfs hive 0 2018-07-08 12:42 /home/cloudera/etc/user/hive/warehouse/partufo/year=1994
drwxrwxrwt - hdfs hive 0 2018-07-08 12:42 /home/cloudera/etc/user/hive/warehouse/partufo/year=1995
drwxrwxrwt - hdfs hive 0 2018-07-08 12:42 /home/cloudera/etc/user/hive/warehouse/partufo/year=1996
drwxrwxrwt - hdfs hive 0 2018-07-08 12:42 /home/cloudera/etc/user/hive/warehouse/partufo/year=1997
drwxrwxrwt - hdfs hive 0 2018-07-08 12:42 /home/cloudera/etc/user/hive/warehouse/partufo/year=1998
drwxrwxrwt - hdfs hive 0 2018-07-08 12:42 /home/cloudera/etc/user/hive/warehouse/partufo/year=1999
drwxrwxrwt - hdfs hive 0 2018-07-08 12:42 /home/cloudera/etc/user/hive/warehouse/partufo/year=2000
drwxrwxrwt - hdfs hive 0 2018-07-08 12:42 /home/cloudera/etc/user/hive/warehouse/partufo/year=2001
drwxrwxrwt - hdfs hive 0 2018-07-08 12:42 /home/cloudera/etc/user/hive/warehouse/partufo/year=2002
drwxrwxrwt - hdfs hive 0 2018-07-08 12:42 /home/cloudera/etc/user/hive/warehouse/partufo/year=2003
drwxrwxrwt - hdfs hive 0 2018-07-08 12:42 /home/cloudera/etc/user/hive/warehouse/partufo/year=2004
drwxrwxrwt - hdfs hive 0 2018-07-08 12:42 /home/cloudera/etc/user/hive/warehouse/partufo/year=2005
drwxrwxrwt - hdfs hive 0 2018-07-08 12:42 /home/cloudera/etc/user/hive/warehouse/partufo/year=2006
drwxrwxrwt - hdfs hive 0 2018-07-08 12:42 /home/cloudera/etc/user/hive/warehouse/partufo/year=2007
drwxrwxrwt - hdfs hive 0 2018-07-08 12:42 /home/cloudera/etc/user/hive/warehouse/partufo/year=2008
drwxrwxrwt - hdfs hive 0 2018-07-08 12:42 /home/cloudera/etc/user/hive/warehouse/partufo/year=2009
drwxrwxrwt - hdfs hive 0 2018-07-08 12:42 /home/cloudera/etc/user/hive/warehouse/partufo/year=2010
我们查看了Hive为分区表存储数据的目录,发现该目录下共有100个动态生成的分区表。今后使用HiveQL语句引用某个特定分区,Hive会执行一次优化—–即它只会处理在相应分区路径下的数据。
9. 用户自定义函数(UDF)
Hive允许用户在HiveQL执行过程的中直接挂接自定义代码。这个功能可以通过新增库函数实现,也可以通过指定类似于Hadoop Streaming的Hive transform实现。接下来,通过使用UDF创建并调用自定义Java代码。
将下面代码保存为City.java
package hivedemo;
import org.apache.hadoop.hive.ql.exec.UDF;
import org.apache.hadoop.io.Text;
import java.util.regex.Matcher;
import java.util.regex.Pattern;
public class City extends UDF {
private static Pattern pattern = Pattern.compile(
"[a-zA-z]+?[\\. ]*[a-zA-z]+?[\\, ][^a-zA-Z]");
public Text evaluate(final Text str) {
Text result;
String location = str.toString().trim();
Matcher matcher = pattern.matcher(location);
if (matcher.find()) {
result = new Text(location.substring(matcher.start(), matcher.end()-2));
}
else {
result = new Text("Unknown");
}
return result;
}
}编译City.java
这里我们用IntelliJ来编译,当编辑完代码,选择IDE左上角的Build -> Recompile ‘City.java’就可完成编译。
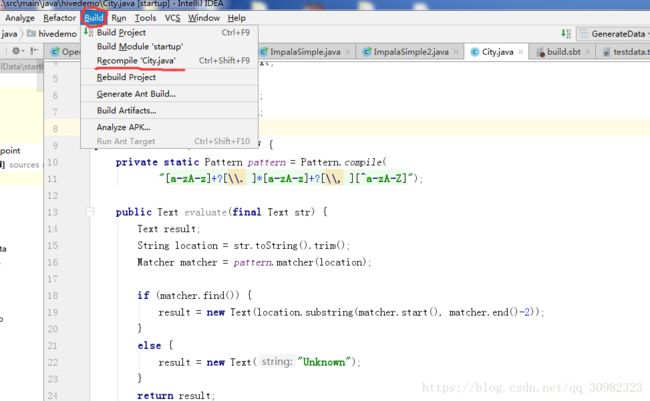
选择左上角的File–>Project Structure–>Modules–>Paths–>Use module compile output path就能查到刚才编译的City.java的class文件的输出路径,我这里是E:\LocalData\startUp\target\scala-2.10\classes

去到该路径下,你会发现有一个hivedemo的文件夹,里面就有City.class这个文件,然后将这个文件夹以及文件夹的内容打包到JAR文件中:
jar cvf city.jar hivedemo其中参数 -c 表示创建新的存档, -v 生成详细输出到标准输出上, -f 指定存档文件名。后面的hivedemo是City.java这个程序所在的包。
接着我们将city.jar这个文件上传到linux某个目录,并在该目录下启动Hive CLI,这样就可以将city.jar添加到Hive classpath中。
[root@master ~]# su - hdfs
-bash-4.1$ hive
Logging initialized using configuration in jar:file:/home/cloudera/parcels/CDH-5.8.2-1.cdh5.8.2.p0.3/jars/hive-common-1.1.0-cdh5.8.2.jar!/hive-log4j.properties
WARNING: Hive CLI is deprecated and migration to Beeline is recommended.
hive>
>
> add jar city.jar;
Added [city.jar] to class path
Added resources: [city.jar]
hive>
>
> list jars;
city.jar
为新加入的代码重新注册一个函数名:
hive> create temporary function city as 'hivedemo.City';
OK
Time taken: 0.322 seconds
使用新函数执行一次查询:
hive> select city(sighting_location), count(*) as total from partufo
> where year = '1999'
> group by city(sighting_location) having total > 15;
输出结果如下:
Hadoop job information for Stage-1: number of mappers: 1; number of reducers: 1
2018-07-15 12:54:07,968 Stage-1 map = 0%, reduce = 0%
2018-07-15 12:54:14,291 Stage-1 map = 100%, reduce = 0%, Cumulative CPU 2.49 sec
2018-07-15 12:54:20,598 Stage-1 map = 100%, reduce = 100%, Cumulative CPU 5.32 sec
MapReduce Total cumulative CPU time: 5 seconds 320 msec
Ended Job = job_1528709271670_180554
MapReduce Jobs Launched:
Stage-Stage-1: Map: 1 Reduce: 1 Cumulative CPU: 5.32 sec HDFS Read: 3659501 HDFS Write: 82 SUCCESS
Total MapReduce CPU Time Spent: 5 seconds 320 msec
OK
Chicago 19
Las Vegas 19
Phoenix 19
Portland 17
San Diego 18
Seattle 26
Unknown 34
Time taken: 21.802 seconds, Fetched: 7 row(s)