Caffe学习笔记(三)Caffe训练
笔记(三):用 Caffe 已有的网络模型训练自己的数据
文章目录
- 1. 准备数据
- 2. 生成LMDB文件
- 3. 生成均值文件
- 4. 用预训练模型进行训练
- 5. 绘制loss曲线
- 6. 训练问题记录
- 1) loss不下降
- 2) 测试报错
1. 准备数据
1)再划分训练数据
这里使用的是 kaggle 的二分类数据集:cat & dog,cat 和 dog 的 train 包内各有 12500 张图片,将图像分为两批:训练数据(train)和验证数据(val),一般比例大概是 5:1
这里我分别将 cat 和 dog 训练数据的前 13000 张作为训练数据(编号 0 ~ 12299),将后 200 张作为验证数据(编号 13000 ~ 12499)
在 caffe/data 中建立存放图像数据的文件夹 kaggle,在 kaggle 文件夹下再建立子文件夹 train 和 val,分别用于存放训练数据和验证数据。
在 train 文件夹下建立 cat_train 和 dog_train 子文件夹,在 val 文件夹下建立 cat_val 和 dog_val 子文件夹,将分好的训练数据和验证数据分别放在 train 和 val 对应类别的子文件夹下。
2)生成数据集的列表 txt 文件
在 kaggle 文件夹下创建 3 个 txt 文件:
word.txt:类别序号与类别的对应关系,从0开始标注。
0 cat
1 dog
train.txt:训练图像路径及其对应的分类,路径和分类序号直接用空格分割,最好随机打乱一下图片顺序(我没弄,太懒了)。
/cat_train/cat.0.jpg 0
...
/cat_train/cat.12299.jpg 0
/dog_train/dog.0.jpg 1
...
/dog_train/dog.12299.jpg 1
val.txt:测试图像路径及其分类。
/cat_val/cat.12300.jpg 0
...
/cat_val/cat.12499.jpg 0
/dog_val/dog.12300.jpg 1
...
/dog_val/dog.12499.jpg 1
注意数据路径问题,因为这里的组织方式是这样的:
-[ caffe
----[ data
-------[ kaggle
-----------[ train
--------------[ cat_train
--------------[ dog_train
-----------[ val
--------------[ cat_val
--------------[ dog_val
---------- label.txt
---------- train.txt
---------- val.txt
所以生成的 txt 文件需要额外包含一个子文件目录 *_train 和 *_val,如果直接将图片数据放在了 train 和 val 之下,txt 就只需要包含图片的名称。
否则在生成 LMDB 文件的时候就会报我这样的错误:
![]()
生成train.txt的代码清单
# windows + pycharm
# 创建txt文件
def create_text(name, msg):
desktop_path = 'E:\python\scripts\\'
full_path = desktop_path + name + '.txt'
file = open(full_path, 'w')
for line in msg:
file.write(line + '\n')
file.close()
print('Done!')
# 生成文本
def generate_msg(num1, num2): # num1/2分别是cat和dog的训练图片数量
list = [] # 存放所有训练数据的名称
for i in range(num1):
a = '/cat_train/cat.' + str(i) + '.jpg' + ' ' + str(0)
list.append(a)
for i in range(num2):
b = '/dog_train/dog.' + str(i) + '.jpg' + ' ' + str(1)
list.append(b)
return list
list = generate_msg(12300, 12300) # kaggle cat和dog分别有12300张训练图像
create_text('train',list)
生成val.txt的代码清单
# 创建txt文件
def create_text(name, msg):
desktop_path = 'E:\python\scripts\\'
full_path = desktop_path + name + '.txt'
file = open(full_path, 'w')
for line in msg:
file.write(line + '\n')
file.close()
print('Done!')
# 生成文本
def generate_msg(num1, num2): # num1/2分别是cat和dog的图片数量
list = [] # 存放所有训练数据的名称
for i in range(num1):
a = '/cat_val/cat.' + str(12300 + i) + '.jpg' + ' ' + str(0)
list.append(a)
for i in range(num2):
b = '/dog_val/dog.' + str(12300 + i) + '.jpg' + ' ' + str(1)
list.append(b)
print(list)
return list
list = generate_msg(200, 200) # kaggle cat和dog分别有200张测试图像
create_text('val', list)
也可以在 caffe/data/kaggle 目录下写一个脚本 create_list.sh,用来生成这两个 txt 清单文件:(参考笔记 用shell生成txt文件)
# Linux shell
vi create_list.sh
# 输入以下内容
#!/usr/bin/env sh
DATA=data/kaggle # 图片保存的根目录
LIST=data/kaggle # 生成文件的保存目录
echo "Create train.txt..."
rm -rf $LIST/train.txt
find $DATA/train/cat_train -name *.jpg | cut -d '/' -f4-5 | sed "/./{s/^/\//;s/$/ 0/}">>$LIST/train.txt
find $DATA/train/dog_train -name *.jpg | cut -d '/' -f4-5 | sed "/./{s/^/\//;s/$/ 1/}">>$LIST/train.txt
echo "Create val.txt..."
rm -rf $LIST/val.txt
find $DATA/val/cat_val -name *.jpg | cut -d '/' -f4-5 | sed "/./{s/^/\//;s/$/ 0/}">>$LIST/val.txt
find $DATA/val/dog_val -name *.jpg | cut -d '/' -f4-5 | sed "/./{s/^/\//;s/$/ 1/}">>$LIST/val.txt
echo "All done"
2. 生成LMDB文件
将图片数据转成 LMDB 格式的数据(caffe接受的格式),相当于把数据重新整合一下变成数据库送给caffe进行训练。
生成方法:caffe/examples/imagenet 下的 create_imagenet.sh 文件
进入 caffe/examples,将 imagenet 文件夹的 create_imagenet.sh 复制到 caffe/models/my_network 文件夹下进行修改,主要修改下面几个目录,然后运行该sh文件。

修改为:


其中 EXAMPLE 路径是保存 LMDB 格式文件的路径,运行该 sh 文件,就可以将 data/ 下的数据生成相应的 LMDB 格式的数据。
另外,这里将 resize 设置为 True,将所有图片的尺寸统一起来。
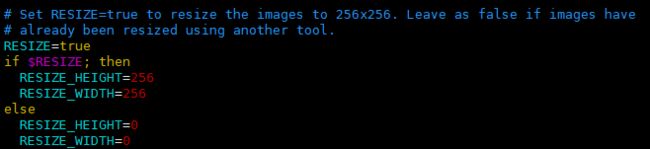
这里就是生成的 LMDB 文件保存路径,EXAMPLE 就是最前面我们定义的路径。
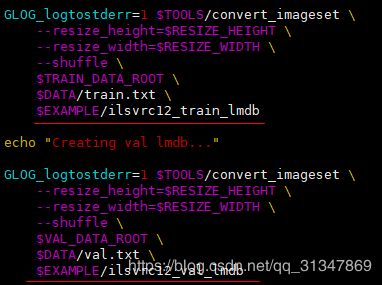
运行:./create_imagenet.sh --shuffle=1,这里要加 shuffle 将训练数据打乱,否则后面训练的时候会出现 accuracy 始终为 1 的情况(这是在训练时才发现的,具体情况参考 Caffe学习笔记(五))。
运行以后,在 caffe/models/my_network 文件夹下会得到 ilsvrc12_train_lmdb 和 ilsvrc12_val_lmdb 文件夹。


3. 生成均值文件
减去均值一般会让图像的亮度下降,但是亮度对图像分类任务来说没那么重要,而且减去均值能够增强图像的稳定性(降低波动),从而提高分类精度且加快训练速度。
PS:只对训练集生成均值文件,而对验证集不生成
生成方法:在 LMDB 文件的基础上,利用 caffe/examples/imagenet 下的 make_imagenet_mean.sh 文件
将 make_imagenet_mean.sh 文件复制到 caffe/models/my_network 文件夹下进行修改,主要修改下面几个目录,然后运行该sh文件。

EXAMPLE 后面为 lmdb 格式数据的所在位置路径,和下面$EXAMPLE结合,DATA 后面为最终要生成的均值文件存放路径,和下面 $DATA 结合,TOOLS 后面为 caffe 的安装位置中的 /build/tools 文件夹位置。

然后就能看到 my_network 下多了一个 imagenet_mean.binaryproto 文件。
另一种生成均值文件的方法:直接运行 compute_image_mean.cpp:
sudo build/tools/compute_image_mean models/my_network/ilsvrc12_train_lmdb models/my_network/mean.binaryproto
- 第一个参数是 LMDB 数据的存储位置
- 第二个参数是均值文件的名字以及均值文件将要保存的路径
4. 用预训练模型进行训练
Caffe 目录下自带一个 CaffeNet 模型,位于 models/bvlc_reference_caffenet/ 里,将 solver.prototxt 和 train_val.prototxt 复制到 caffe/models/my_network 下。
cp solver.prototxt /data/zyy/usr/local/anaconda/envs/caffe27/caffe/models/my_network
cp train_val.prototxt /data/zyy/usr/local/anaconda/envs/caffe27/caffe/models/my_network
1)修改 solver.prototxt:
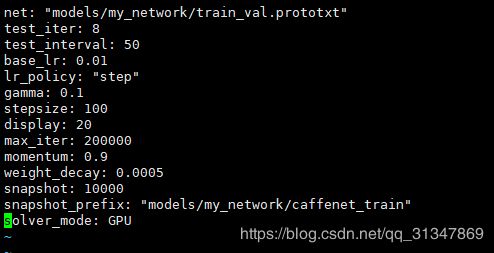
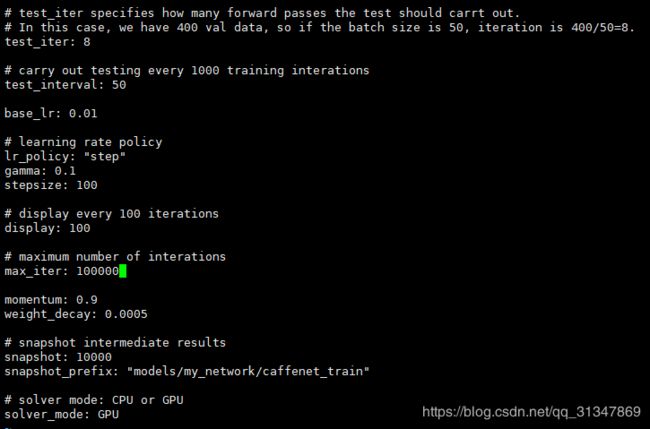
共有 400 个 val 数据,设置测试的迭代次数为 8,每次迭代送进去 50 张图像进行测试。
另外,迭代次数其实不需要设置很大,caffe 没有自动收敛的功能,它只有在迭代到最大次数后才会停止,但是只要我们观察到 loss 很小基本不再下降以后就可以停止训练了。
说明:参数概念
- net:网络模型的 prototxt 文件路径
- test_iter:在测试的时候需要迭代的次数,因为每次测试时是对所有测试图像的测试,而测试不是一次将所有测试图像全扔进去测试,它是分批(batch)进行测试,比如说每次测试 50 张图片,那么测试图像如果有 500 张的话,完成一次测试就需要扔 500 / 50 = 10 次数据进去,这就是 test_iter,即测试时的迭代次数
- test_interval:在训练时,每迭代 test_interval 次就执行一次测试
- display:训练时迭代几次就打印一下当前的训练信息
- max_iter:训练的最大迭代次数
- snapshot:迭代多少次就生成一个快照,快照时当前的训练信息
- snapshot_prefix:快照保存的路径
2)修改 train_val.prototxt:
需要修改前两个 数据层(data layer) 的相关路径以及最后的输出通道数,其他不用改。
# 修改 mean_file 和 source
name: "CaffeNet"
layer {
name: "data"
type: "Data"
top: "data"
top: "label"
include {
phase: TRAIN
}
transform_param {
mirror: true
crop_size: 227
mean_file: "models/my_network/imagenet_mean.binaryproto" # 修改
}
data_param {
source: "models/my_network/ilsvrc12_train_lmdb" # 修改
batch_size: 256
backend: LMDB
}
}
layer {
name: "data"
type: "Data"
top: "data"
top: "label"
include {
phase: TEST
}
transform_param {
mirror: false
crop_size: 227
mean_file: "models/my_network/imagenet_mean.binaryproto" # 修改
}
data_param {
source: "models/my_network/ilsvrc12_val_lmdb" # 修改
batch_size: 50
backend: LMDB
}
}
# 修改输出通道数
layer {
name: "fc8"
type: "InnerProduct"
bottom: "fc7"
top: "fc8"
param {
lr_mult: 1
decay_mult: 1
}
param {
lr_mult: 2
decay_mult: 0
}
inner_product_param {
num_output: 2 # 这里是二分类,所以输出通道数为2
weight_filler {
type: "gaussian"
std: 0.01
}
bias_filler {
type: "constant"
value: 0
}
}
}
说明:注意最后的 loss 层用的是 softmax 损失函数,它主要用于多标签分类,所以在 fc8 层的输出通道数应该是 2,因为要给出每张图片分别属于两个类的概率。如果将最后的 loss 函数改为 Sigmoid 损失函数,那么输出通道数就应该修改为 1,因为对于每张图片它只会判断是 or 否,输出为 0 or 1,也就是判断是猫 or 不是猫。
CaffeNet 的网络结构:

2)训练:
在 my_network 下编写脚本:train.sh
# !/usr/bin/env sh
set -e
/data/zyy/usr/local/anaconda/envs/caffe27/caffe/build/tools/caffe train \
--solver=/data/zyy/usr/local/anaconda/envs/caffe27/caffe/models/my_network/solver.prototxt $@
运行该 sh 文件即可:.\train.sh
或者直接在终端输入训练命令:
./build/tools/caffe train --solver=models/my_network/solver.prototxt
要指定用某一个gpu,只需要在指令后面加上 -gpu 1,多块 gpu训练则用 -gpu 0,1,2
训练完以后用 test 数据测试一下:
./build/examples/cpp_classification/classification.bin \
models/my_network/deploy.prototxt \
models/my_network/caffenet_train/solver_iter_20000.caffemodel \
models/my_network/imagenet_mean.binaryproto \
data/kaggle/synset_words.txt data/kaggle/test/1.jpg

5. 绘制loss曲线
使用 Caffe 自带工具绘制 loss 曲线,具体绘制方法参考:使用Caffe自带工具绘制loss曲线
迭代了 21000 次左右,accuracy = 0.945
loss 曲线如下:
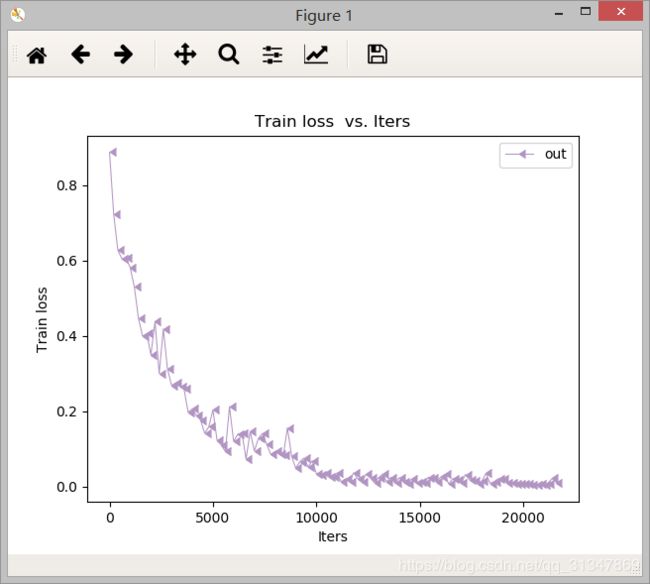
6. 训练问题记录
1) loss不下降
train loss 一直在 0.69 不下降,是学习率太大的原因,调小学习率到 0.08。
2) 测试报错
Cannot copy param 0 weights from layer 'fc8'; shape mismatch. Source param shape is 2 4096 (8192); target param shape is 1 4096 (4096). To learn this layer's parameters from scratch rather than copying from a saved net, rename the layer
参考:Caffe使用经验积累
出现这个问题一般是层与层的之间 blob 维度对应不上,需要改prototxt
检查一下 train_val.prototxt 和 deploy.prototxt 的 fc8 层输出维度是否一致,果然是我忘记改 depoly.prototxt 的输出维度了。- -!
参考文章:
训练我们自己的数据
用 caffe 搭建简单的二分类网络