Python 实战-第 1 周-练习项目02-爬取商品信息
成果展示
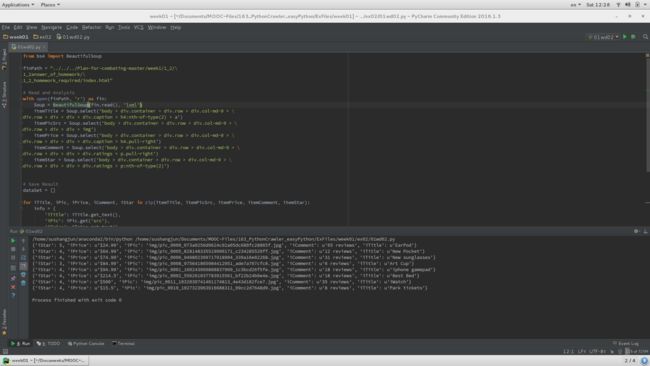
代码
贴代码如下。同时放在 GitHub 库 上
from bs4 import BeautifulSoup
finPath = "../../../Plan-for-combating-master/week1/1_2/\
1_2answer_of_homework/\
1_2_homework_required/index.html"
# Read and Analyse
with open(finPath, 'r') as fin:
Soup = BeautifulSoup(fin.read(), 'lxml')
itemTitle = Soup.select('body > div.container > div.row > div.col-md-9 > \
div.row > div > div > div.caption > h4:nth-of-type(2) > a')
itemPicSrc = Soup.select('body > div.container > div.row > div.col-md-9 > \
div.row > div > div > img')
itemPrice = Soup.select('body > div.container > div.row > div.col-md-9 > \
div.row > div > div > div.caption > h4.pull-right')
itemComment = Soup.select('body > div.container > div.row > div.col-md-9 > \
div.row > div > div > div.ratings > p.pull-right')
itemStar = Soup.select('body > div.container > div.row > div.col-md-9 > \
div.row > div > div > div.ratings > p:nth-of-type(2)')
# Save Result
dataSet = []
for iTitle, iPic, iPrice, iComment, iStar in zip(itemTitle, itemPicSrc, itemPrice, itemComment, itemStar):
info = {
'iTitle': iTitle.get_text(),
'iPic': iPic.get('src'),
'iPrice': iPrice.get_text(),
'iComment': iComment.get_text(),
'iStar': len(iStar.find_all("span", class_="glyphicon glyphicon-star"))
}
dataSet.append(info)
# See Result
for info in dataSet:
print(info)
总结
0. 导入模块与文件
from bs4 import BeautifulSoup
# 若使用 from bs4 import BeautifulSoup as bs
# 则代码中所有 BeautifulSoup 均可替换成缩写 bs
with open(finPath, 'r') as fin:
# finPath 是 index.html 文件路径
# 以只读方式读取到变量 fin 中
1. 如何解析待爬取的网页
Soup = BeautifulSoup(fin.read(), 'lxml')
# 将从 fin 中读出的字符串(全文)解析为 lxml 格式
2. 直接拷贝通过 Chrome 「Inspect」(「检查」)得到的 CSS Selector 代码,作为 Soup.select() 的参数输入,得到空白列表
其中,作为 Soup.select() 参数的 CSS Selector 代码为
body > div:nth-child(2) > div > div.col-md-9 > div:nth-child(2) > div:nth-child(1) > div > div.caption > h4:nth-child(2) > a
解决方法
仅仅把 nth-child(num) 换成 nth-of-type(num) 是不起作用的。需要把大部分的 :nth-child(num) 换成用对应的CSS 类选择器才行。
例如上述代码中 div:nth-child(2) 对应的 HTML 代码为 body > div:nth-child(2) 改为 body > div.container。
其他部分如法炮制,除非某些标签不是靠类选择器来区分,例如这里最底层的 标签本身是没有类名的,因此仍然用 :nth-of-type(2) 定位。
最后修改 Soup.select() 的参数为如下字符串,从而得到所有包含标题的 标签
'body > div.container > div.row > div.col-md-9 > div.row > div > div > div.caption > h4:nth-of-type(2) > a'
3. 如何统计评分星级? 注意到「评价星级」并非是普通文本内容,无法直接通过 get_text() 或者 get() 得到
解决方法
查看网页中与评分星级有关的 HTML 代码发现,每一个星星,对应着一段这样的代码
即 CSS 选择器 body > div.container > div.row > div.col-md-9 > \div.row > div > div > div.ratings > p:nth-of-type(2) 指向的位置的标签数为星级数。
那么如何计算标签数呢?如果能够找到这个位置下所有的标签,就有可能完成这一任务了。
幸运的是 BeautifulSoup 提供了这样一个方法:find_all(),该方法可根据搜索调用该方法的对象中是否有关键字所代表的标签;更棒的是该方法支持通过 按 CSS 搜索。因此我们可以编写下述 python 代码,首先将所有包含评分星级的 HTML 代码导入 itemStar 中,执行 print() 语句将展示 itemStar[0] 对应的评分星级数:
itemStar = Soup.select('body > div.container > div.row > div.col-md-9 > div.row > div > div > div.ratings > p:nth-of-type(2)')
print(len(itemStar[0].find_all("span", class_="glyphicon glyphicon-star")))
4. 如何保存结果?
爬取完毕后,或许需要保存爬取结果以便后续分析。这里我将爬取结果暂存于内存中(即不导出为文件)。
最开始我的代码是这样的:
for iTitle, iPic, iPrice, iComment, iStar in zip(itemTitle, itemPicSrc, itemPrice, itemComment, itemStar):
info = {
'iTitle': iTitle.get_text(),
'iPic': iPic.get('src'),
'iPrice': iPrice.get_text(),
'iComment': iComment.get_text(),
'iStar': len(iStar.find_all("span", class_="glyphicon glyphicon-star"))
}
print(info)
然而为什么结果只有 1 项(5 个属性)?
解决办法
观察视频中源代码与自己代码在这部分的差别后,我发现:视频中的源代码是用一个列表保存结果的,而列表的每一项是一个字典。我的问题在于:每次循环时都更新名为 info 的字典,因此最后打印出的内容是最后一项商品信息。
知道了问题,于是修改代码如下:
# Save Result
dataSet = []
for iTitle, iPic, iPrice, iComment, iStar in zip(itemTitle, itemPicSrc, itemPrice, itemComment, itemStar):
info = {
'iTitle': iTitle.get_text(),
'iPic': iPic.get('src'),
'iPrice': iPrice.get_text(),
'iComment': iComment.get_text(),
'iStar': len(iStar.find_all("span", class_="glyphicon glyphicon-star"))
}
dataSet.append(info)
# See Result
for info in dataSet:
print(info)