数据分析:Python分析学生数据
本文为优达学城数据分析入门课程的mini项目,所用数据集为优达学城某段时间内的学生数据。
数据简介
全部数据包含三个文件,其内容分别为:
- enrollments.csv:

- daily-engagement.csv

- project-submissions.csv

各字段的意义见table_desc.txt,文末附录会给出。
载入数据
import csv
def readcsv_Dict(file):
with open(file) as fd:
reader=csv.DictReader(fd) #以字典形式读取CSV,适用于带headline的数据
return list(reader)enrollments=readcsv_Dict("./enrollments.csv")
engagements=readcsv_Dict("./daily-engagement.csv")
submissions=readcsv_Dict("./project-submissions.csv")
print(len(enrollments),len(engagements),len(submissions))输出为:1640,136240,3642
预览数据
enrollments[0]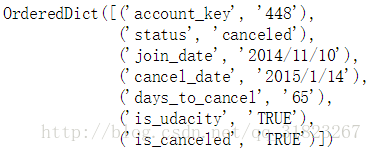
engagements[0]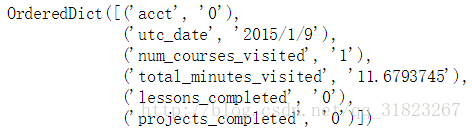
submissions[0]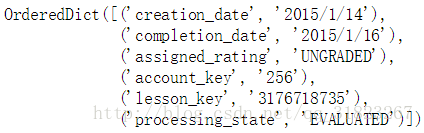
数据处理
格式修正
从CSV中读出的数据是以字符串存储在内存中的,需要对原数据中的数值类型与时间类型进行还原。
from datetime import datetime as dt
def parase_data(data):
if data=="":
return None
else:
return dt.strptime(data, '%Y/%m/%d')
def parase_maybe_int(i):
if i=="":
return None
else:
return int(i)#字符串转换
for line in enrollments:
line['join_date']=parase_data(line['join_date'])
line['cancel_date']=parase_data(line['cancel_date'])
line['days_to_cancel']=parase_maybe_int(line['days_to_cancel'])
line['is_udacity']=(line['is_udacity']=='TRUE')
line['is_canceled']=(line['is_canceled']=='TRUE')
for line in engagements:
line['utc_date']=parase_data(line['utc_date'])
line['num_courses_visited']=parase_maybe_int(float(line['num_courses_visited']))
line['total_minutes_visited']=float(line['total_minutes_visited'])
line['lessons_completed']=parase_maybe_int(float(line['lessons_completed']))
line['projects_completed']=parase_maybe_int(float(line['projects_completed']))
for line in submissions:
line['creation_date']=parase_data(line['creation_date'])
line['completion_date']=parase_data(line['completion_date'])
# print(enrollments[0])
# print(engagements[0])
# print(submissions[0])字段修正
注意到engagements中的学生账户字段标识与另两文件中的不一样,将其修改为与另两者一致的’account_key’。
#修改不一致的键值(这里也可以直接对原文件进行修改)
for line in engagements:
line['account_key']=line['acct']
del line['acct']
print(engagements[0])计算学生数
计算三个文件中分别有多少学生的数据。
def get_unique_stu(stu_list):
unique_stu=set()
for stu in stu_list:
unique_stu.add(stu['account_key'])
return unique_stuunique_enroller=get_unique_stu(enrollments)
unique_engager=get_unique_stu(engagements)
unique_submitter=get_unique_stu(submissions)
print(len(unique_enroller),len(unique_engager),len(unique_submitter))输出为:1302,1237,743
处理异常值
可以看到enrollments中的学生数要多于engagement中的学生数,这是不合理的,正常来说应该是engagement中的学生数大于等于enrollments的学生数,所以数据中一定存在异常值。
找出在enrollments中存在却不在engagement中存在的学生,这里排除掉当天注册又注销的学生。
def find_outlier():
for enroll_stu in enrollments:
stu=enroll_stu['account_key']
if stu not in unique_engager and enroll_stu['join_date']!=enroll_stu['cancel_date']:
print(enroll_stu)
find_outlier()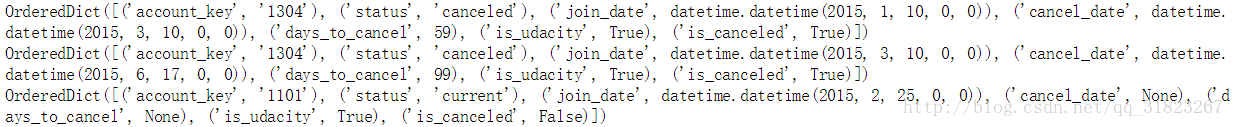
发现异常值有一个共同点:(‘is_udacity’, True),都为优达学城的测试账号。
删除掉这些测试账号。
test_acct=[]
for stu in enrollments:
if stu['is_udacity']:
test_acct.append(stu['account_key'])
test_acct=list(set(test_acct))
def remove_test_acct(stu_list):
tmp=[]
for stu in stu_list:
if stu['account_key'] not in test_acct:
tmp.append(stu)
return tmp
enrollments=remove_test_acct(enrollments)
engagements=remove_test_acct(engagements)
submissions=remove_test_acct(submissions)
print(len(test_acct))有6个测试账号。
筛选数据
由于整个数据集中包含了七天免费试用的学生,这一部分学生数据明显是没有意义的,需要筛选出付费学生的数据。
paid_students_join_date={}
for stu in enrollments:
#未注销或者取消时间超过七天的学生
if not stu['is_canceled'] or stu['days_to_cancel']>7:
#当字典中不存在条目时创建,且只保留最新的join_date
if stu['account_key'] not in paid_students_join_date or stu['join_date']>paid_students_join_date[stu['account_key']]:
paid_students_join_date[stu['account_key']]=stu['join_date']
paid_acct=list(set(paid_students_join_date.keys()))
def remove_free_acct(stu_list):
tmp=[]
for stu in stu_list:
if stu['account_key'] in paid_acct:
tmp.append(stu)
return tmp
paid_enrollments=remove_free_acct(enrollments)
paid_engagements=remove_free_acct(engagements)
paid_submissions=remove_free_acct(submissions)
print(len(paid_acct))共有995名付费学生。
分析数据
一周数据
这里只分析一周内的数据。
paid_engagement_1stweek=[]
for stu in paid_engagements:
days=(stu['utc_date']-paid_students_join_date[stu['account_key']]).days
if (days>=0 and days<7):
paid_engagement_1stweek.append(stu)
print(len(paid_engagement_1stweek))一周内有6919条数据。
学习时间
from collections import defaultdict
#整合同一学生账户的信息
def group_data(data,key_name):
grouped_data=defaultdict(list) #value为列表的字典
for data_point in data:
grouped_data[data_point[key_name]].append(data_point) #将同一账户的信息整合
return grouped_data
#在整合信息中计算某个字段的累加值
def count_total(grouped_data,field_name):
total_dic={}
for acct in grouped_data:
total=0
for info in grouped_data[acct]:
total+=info[field_name]
total_dic[acct]=total
return total_dic
engager_acct_1stweek=group_data(paid_engagement_1stweek,'account_key')
total_minutes_byacct=count_total(engager_acct_1stweek,'total_minutes_visited')
total_minutes=list(total_minutes_byacct.values())import numpy as np
print(np.mean(total_minutes),np.max(total_minutes),np.min(total_minutes),np.std(total_minutes))输出:306.708326753 3564.7332645 0.0 412.99693341
完成课程数
total_lessons_byacct=count_total(engager_acct_1stweek,'lessons_completed')
total_lessons=list(total_lessons_byacct.values())
print(np.mean(total_lessons),np.max(total_lessons),np.min(total_lessons),np.std(total_lessons))输出:1.63618090452 36 0 3.00256129983
课程访问量
total_courses_visited_byacct=count_total(engager_acct_1stweek,'num_courses_visited')
total_courses_visited=list(total_courses_visited_byacct.values())
print(np.mean(total_lessons),np.max(total_lessons),np.min(total_lessons),np.std(total_lessons))输出:1.63618090452 36 0 3.00256129983
学习天数
当’num_courses_visited’字段不为零时则学习天数加一天。
total_studydays_byacct={}
for acct in engager_acct_1stweek:
total_studydays=0
for info in engager_acct_1stweek[acct]:
if info['num_courses_visited']==0:
continue
else:
total_studydays+=1
total_studydays_byacct[acct]=total_studydays
total_studydays=list(total_studydays_byacct.values())
print(np.mean(total_studydays),np.max(total_studydays),np.min(total_studydays),np.std(total_studydays))输出为:2.86733668342 7 0 2.25519800292
通过情况
以课程746169184与3176718735为例,计算通过这两门课程的学生数。
passing_acct=set()
project_key=['746169184','3176718735']
pass_flag=['PASSED','DISTINCTION']
for stu in paid_submissions:
if (stu['lesson_key'] in project_key) and (stu['assigned_rating'] in pass_flag):
passing_acct.add(stu['account_key'])
print(len(passing_acct))付费学生共有995名,最近一周有647名学生通过了这两门课程。
两群体数据对比
对比通过课程的学生与未通过学生的一系列数据,来发现规律。
#目前已有数据
# total_courses_visited_byacct
# total_lessons_byacct
# total_minutes_byacct
# total_studydays_byacct
def compare_stu_data(data_to_compare):
passing_stu_data={}
non_passing_stu_data={}
for stu_acct in data_to_compare:
if stu_acct in passing_acct:
passing_stu_data[stu_acct]=data_to_compare[stu_acct]
else:
non_passing_stu_data[stu_acct]=data_to_compare[stu_acct]
return passing_stu_data,non_passing_stu_data课程浏览量
passing_stu_courses_visited,non_passing_stu_courses_visited=compare_stu_data(total_courses_visited_byacct)
passing_visited_data,non_passing_visited_data=list(passing_stu_courses_visited.values()),list(non_passing_stu_courses_visited.values())
print(np.mean(passing_visited_data),np.max(passing_visited_data),np.min(passing_visited_data),np.std(passing_visited_data))
print(np.mean(non_passing_visited_data),np.max(non_passing_visited_data),np.min(non_passing_visited_data),np.std(non_passing_visited_data))输出:
4.72642967543 25 0 3.7002397793
2.58908045977 18 0 2.90670969025
差异显著。课程浏览量在一定程度上可以体现学生的学习兴趣,通过课程的学生的学习兴趣要比未通过的学生高。
课程完成量
passing_stu_lessons,non_passing_stu_lessons=compare_stu_data(total_lessons_byacct)
passing_lessons_data,non_passing_lessons_data=list(passing_stu_lessons.values()),list(non_passing_stu_lessons.values())
print(np.mean(passing_lessons_data),np.max(passing_lessons_data),np.min(passing_lessons_data),np.std(passing_lessons_data))
print(np.mean(non_passing_lessons_data),np.max(non_passing_lessons_data),np.min(non_passing_lessons_data),np.std(non_passing_lessons_data))输出:
2.05255023184 36 0 3.14222705558
0.862068965517 27 0 2.54915994183
差异显著。这个没什么好解释的。
学习时间
passing_stu_minutes,non_passing_stu_minutes=compare_stu_data(total_minutes_byacct)
passing_minutes_data,non_passing_minutes_data=list(passing_stu_minutes.values()),list(non_passing_stu_minutes.values())
print(np.mean(passing_minutes_data),np.max(passing_minutes_data),np.min(passing_minutes_data),np.std(passing_minutes_data))
print(np.mean(non_passing_minutes_data),np.max(non_passing_minutes_data),np.min(non_passing_minutes_data),np.std(non_passing_minutes_data))输出:
394.586046483 3564.7332645 0.0 448.49951933
143.326474266 1768.5227493 0.0 269.538619008
差异显著。同样无需解释。
学习天数
passing_stu_studydays,non_passing_stu_studydays=compare_stu_data(total_studydays_byacct)
passing_studydays_data,non_passing_studydays_data=list(passing_stu_studydays.values()),list(non_passing_stu_studydays.values())
print(np.mean(passing_studydays_data),np.max(passing_studydays_data),np.min(passing_studydays_data),np.std(passing_studydays_data))
print(np.mean(non_passing_studydays_data),np.max(non_passing_studydays_data),np.min(non_passing_studydays_data),np.std(non_passing_studydays_data))输出:
3.38485316847 7 0 2.25882147092
1.90517241379 7 0 1.90573144136
差异显著。
可视化
%matplotlib inline
import matplotlib.pyplot as plt学习时间
plt.xlabel("total_minutes")
plt.ylabel("num of stu")
plt.hist(passing_minutes_data,bins=30)
plt.hist(non_passing_minutes_data,bins=30)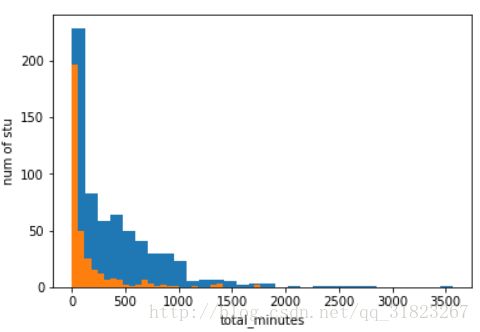
学习天数
通过的学生:
plt.xlabel("study days")
plt.ylabel("num of stu")
plt.hist(passing_studydays_data,bins=7)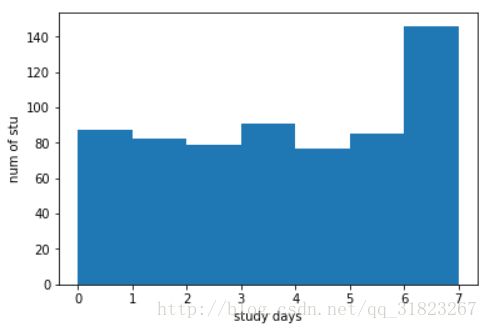
未通过的学生:
plt.xlabel("study days")
plt.ylabel("num of stu")
plt.hist(non_passing_studydays_data,bins=7)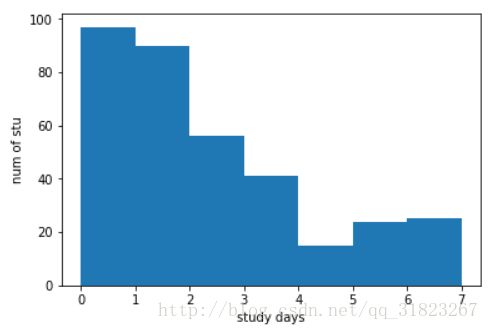
附录
enrollments.csv:
- account_key:学员帐号标识
- status:收集数据时,学员课程状态的数据,可能的值为“已取消”(’canceled’)和“学习中”(’current’)。
- join_date:学员加入课程的时间。
- cancel_date:学员取消的时间,如果学员没有取消则显示空。
- days_to_cancel:加入课程时间和取消时间之间间隔的天数,如果学员没有取消就显示空。
- is_udacity:如果是优达学城官方的测试账号,就显示 True,如果不是,显示 False。
- is_canceled:如果收集数据时,学员已经取消,就显示 True,如果还没有取消,显示 False。
daily_engagement.csv:报名注册表中每一位学生,在数据分析纳米学位的日常参与学习数据。
- acct:学员账号的唯一标识符,这是他们参与学习的数据。(导入数据后修改为account_key)
- utc_date:收集数据的日期。
- num_courses_visited:这一天里,学生访问数据分析纳米学位课程的数量(访问时间至少 2 分钟)。纳米学位课程和免费课程,如果内容相同,也需要分开考虑。
- total_minutes_visited:在这一天,学生学习数据分析纳米学位课程的总时间(分钟)。
- lessons_completed:在这一天,学生访问的数据分析纳米学位中的课程总数。
- projects_completed:在这一天,学生完成的数据分析纳米学位中的项目总数。
project_submissions.csv:关于在报名注册表中的每个学生提交数据分析纳米学位项目的数据。
- creation_date:项目提交的日期。
- completion_date:项目被评估的日期。
- assigned_rating:这个字段有4个可能的值:
blank - 项目没有被评估。
INCOMPLETE - 项目不符合要求。
PASSED - 项目符合要求。
DISTINCTION – 项目超出要求。
UNGRADED – 项目无法被评估。(例如:包括损坏的文件) - account_key:提交了该项目的学生账号的唯一标识符。
- lesson_key:提交了项目的唯一标识符。(练习使用ID:746169184,3176718735)
- processing_state:这个字段可能有2个可能的值:
CREATED - 项目已提交但没有被评估。
EVALUATED – 项目已经被评估。