Faster RCNN算法详解
本文仅供个人学习使用,如有侵权立刻删除;原文链接传送:http://blog.csdn.net/u014696921/article/details/53767153自2015以来,人工智能在计算机视觉领域(人脸识别\物体分类\图片描述)已经超越人类的识别正确率和速度,而关于速度的提升,不得不提RGB的开山之作(Faster-RCNN) .先来个概述:Faster-RCNN通过交叉训练方式,共享 卷积特征,从而大幅缩减了训练参数(原文描述为RPN cost-free)------ 除了CNN网络架构本身具有的权值共享,在RGB的论文里我们再次感受到共享思想的伟大:通过交替训练两个类型的网络达到(cost-free)!当然,从实验数据来看:也取得了近乎real-time的性能,真是“Deep learning 搞定一切vision task”.另外, 我也基于该技术做了一个实时场景分析和描述的人工智能系统:先进行场景中各类物体的识别(Faster-RCNN),再使用自然语言描述(LSTM),(即具备感知(识别物体)和认知能力(学习如何去表达)). 点击打开链接 效果如论文所述"waives nearly all computational burdens of Selective Search at test-time—the effective running time for proposals is just 10 milliseconds."
INTRODUCTION
首先,论文回顾Fast-RCNN:与典型的RCNN不同的是,典型的RCNN使用Selective Search;而Fast-RCNN使用EdgeBoxes。直接取得性能上的优势,论文给出的数据是,Selective Search:2 seconds per image,而使用EdgeBoxes是0.2 seconds per image,也就是Fast-RCNN提高了十倍的速度.
然后, 论文指出Faster-RCNN( 可以看做是对 Fast-RCNN 的再次改进版):主要解决的是如何在RPN网络中快速获得 proposal, 作者在他的论文中提出,卷积后的特征图其实是可以用来生成 region proposals ! 所以,作者通过增加两个独立\平行的全连接层来实现 Region Proposal Networks (RPN) , 一个用来以回归方式生成推荐区域(region bounds),另一个则是objectness score。
接着,作者強調:为了面对平移(缩放)不变性,经典做法有:对输入图片或者卷积网络里的滤波器进行整体尺度\矩形长宽比例的采样;而作者的做法是:对推荐区域(novel “anchor” boxes)进行尺度\矩形比例的采样.结果是,对推荐区域采样的模型,不管是速度还是准确率都取得很好的性能.
最后,为了将fully-convolutional network (FCN)的RPN 与 Fast-RCNN 相结合,作者给出了一种简单的训练方法:固定 proposals数目, 为训练RPN和Fast-RCNN, 这两个训练的task交替微调网络 ,交替过程实现卷积特征共享----注意这里就是大招!!!因此不需要重复的卷积计算, 共享卷积特征也让两个网络快速地收敛,所以,大幅地提高了网络的训练和测试(应用)速度------这就是Faster-RCNN的优势所在, 一种优雅并且高效的方案.
Region Proposal Networks
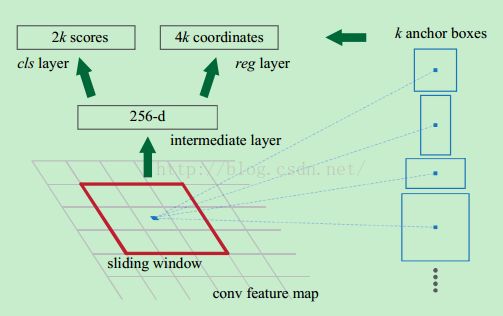
RPN的目的是实现"attention"机制,告诉后续的扮演检测\识别\分类角色的Fast-RCNN应该注意哪些区域,它从任意尺寸的图片中得到一系列的带有 objectness score 的 object proposals。具体流程是:使用一个小的网络在已经进行通过卷积计算得到的feature map上进行滑动扫描,这个小的网络每次在一个feature map上的一个窗口进行滑动(这个窗口大小为n*n----在这里,再次看到神经网络中用于缩减网络训练参数的局部感知策略receptive field,通常n=228在VGG-16,而作者论文使用n=3),滑动操作后映射到一个低维向量(例如256D或512D,这里说256或512是低维,有些同学发邮件问我:n=3,n*n=9,为什么256是低维呢?那么解释一下:低维相对不是指窗口大小,窗口是用来滑动的!256相对的是a convolutional feature map of a size W × H (typically ∼2,400),而2400这个特征数很大,所以说256是低维.另外需要明白的是:这里的256维里的每一个数都是一个Anchor(由2400的特征数滑动后操作后,再进行压缩))最后将这个低维向量送入到两个独立\平行的全连接层:box回归层(a box-regression layer (reg))和box分类层(a box-classification layer (cls))。如下图所示:
Translation-Invariant Anchors
在计算机视觉中的一个挑战就是平移不变性:比如人脸识别任务中,小的人脸(24*24的分辨率)和大的人脸(1080*720)如何在同一个训练好权值的网络中都能正确识别. 传统有两种主流的解决方式,第一:对图像或feature map层进行尺度\宽高的采样;第二,对滤波器进行尺度\宽高的采样(或可以认为是滑动窗口). 但作者的解决该问题的具体实现是:通过卷积核中心(用来生成推荐窗口的Anchor)进行尺度、宽高比的采样。如上图右边,文中使用了3 scales and 3 aspect ratios (1:1,1:2,2:1), 就产生了 k = 9 anchors at each sliding position.
A Loss Function for Learning Region Proposals
anchors(卷积核的中心)分为两类:与ground-truth box 有较高的 IoU 或 与任意一个 ground-truth box 的 IoU 大于0.7 的 anchor 都标为 positive label; 与所有 ground-truth box 的IoU 都小于0.3的 anchor 都标为 negative label。其余非正非负的都被丢掉。
对于每一个 anchor boxi, 其 loss function 定义为:
L(pi,ti)=Lcls(pi,p?i)+λp?iLreg(ti,t?i)
其中,pi 是预测其是一个 object 的 probability ,当其label 为 positive 时,p?i 为1,否则为0。 ti={tx,ty,tw,th} 是预测的 bounding box,t?i 是与这个 anchor 相对应的 ground-truth box 。 classification loss Lcls 是一个二分类(是或者不是object)的 softmax loss 。regression loss Lreg(ti,t?i)=R(ti?t?i), R 是 Fast R-CNN 中定义的 robust loss function (smooth-L1) ,p?iLreg 表示只针对 positive anchors (p?i = 1). 这里还有一个平衡因子 λ , 文中设为10,表示更倾向于box location。
Optimization
使用 back-propagation(反向传播) and stochastic gradient descent (随机梯度) 对这个RPN进行训练,每张图片随机采样了256个 anchors , 这里作者认为如果使用所有的anchors来训练的话,this will bias towards negative samples as they are dominate。所以这里作者将采样的正负positive and negative anchors have a ratio of 1:1. 新增的两层使用高斯来初始化,其余使用 ImageNet 的 model 初始化。
Sharing Convolutional Features for Region Proposal and Object Detection
通过交替优化来学习共享的特征,共四个步骤:
- 1. 用 ImageNet 的 model 初始化一个RPN,然后针对 region proposal task 进行微调。
- 2. 利用第一步得到的 proposals 作为Fast-RCNN 的输入,来训练这个承担detection任务的network.注意: 到这里两个网络还是分开的,没有 share conv layers 。
- 3. 利用第二部训练好的Fast-RCNN来初始化 RPN , 继续训练RPN,这里训练的时候固定 conv layers ,只微调仅属于RPN 那一部分的网络层。
- 4. 再固定 conv layers ,只微调仅属于 Fast-RCNN 的fc 层。
- 第4步结束后,我们已经共享了卷积层,接下来我们就可以进行交替训练(1-4).很好理解吧.
Implementation Details
每个 anchor , 使用 3 scales with box areas of 1282, 2562, and 5122 pixels, and 3 aspect ratios of 1:1, 1:2, and 2:1. 忽略了所有的 cross-boundary anchors 。在 proposal regions 上根据 cls scores 进行了 nonmaximum suppression (NMS) 。
Experiments
作者文中讨论的各种策略和参数进行各个数据集的实验和对应的数据结果.
Conclusion
纵观全文,详述了如何使用 Region Proposal Networks (RPN) 来生成 region proposals(通过卷积核中心(用来生成推荐窗口的Anchor)尺度和比例采样实现平移不变性) ,然后使用Fast-RCNN进行物体检测, 接着使用交替训练从而共享特征(也就是减少了网络参有数)----再次強調大招在这里!!!, 最终region proposal step is nearly cost-free,也就是近乎实时的性能.
总结: 另CNN在人工智能领域脱颖而出的是许多精妙的思想,受生物视觉所启发的局部感知策略,基于统计特性的权值共享,利用特征聚合的池化……这些tricks优化performance的同时,也以指数级递减了计算的复杂度,再者为架构并行和数据切分训练提供了可能。而作者通过交替训练方式进一步把参数共享的思想, 推到当前学术水平的极致.
本文是继RCNN[1],fast RCNN[2]之后,目标检测界的领军人物Ross Girshick团队在2015年的又一力作。简单网络目标检测速度达到17fps,在PASCAL VOC上准确率为59.9%;复杂网络达到5fps,准确率78.8%。
作者在github上给出了基于matlab和python的源码。对Region CNN算法不了解的同学,请先参看这两篇文章:《RCNN算法详解》,《fast RCNN算法详解》。
思想
从RCNN到fast RCNN,再到本文的faster RCNN,目标检测的四个基本步骤(候选区域生成,特征提取,分类,位置精修)终于被统一到一个深度网络框架之内。所有计算没有重复,完全在GPU中完成,大大提高了运行速度。 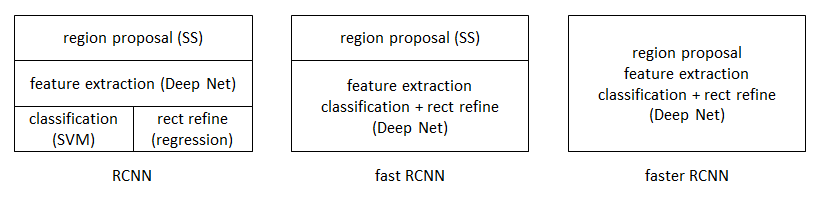
faster RCNN可以简单地看做“区域生成网络+fast RCNN“的系统,用区域生成网络代替fast RCNN中的Selective Search方法。本篇论文着重解决了这个系统中的三个问题:
1. 如何设计区域生成网络
2. 如何训练区域生成网络
3. 如何让区域生成网络和fast RCNN网络共享特征提取网络
区域生成网络:结构
基本设想是:在提取好的特征图上,对所有可能的候选框进行判别。由于后续还有位置精修步骤,所以候选框实际比较稀疏。 
特征提取
原始特征提取(上图灰色方框)包含若干层conv+relu,直接套用ImageNet上常见的分类网络即可。本文试验了两种网络:5层的ZF[3],16层的VGG-16[4],具体结构不再赘述。
额外添加一个conv+relu层,输出51*39*256维特征(feature)。
候选区域(anchor)
特征可以看做一个尺度51*39的256通道图像,对于该图像的每一个位置,考虑9个可能的候选窗口:三种面积{1282,2562,5122}×三种比例{1:1,1:2,2:1}。这些候选窗口称为anchors。下图示出51*39个anchor中心,以及9种anchor示例。 
在整个faster RCNN算法中,有三种尺度。
原图尺度:原始输入的大小。不受任何限制,不影响性能。
归一化尺度:输入特征提取网络的大小,在测试时设置,源码中opts.test_scale=600。anchor在这个尺度上设定。这个参数和anchor的相对大小决定了想要检测的目标范围。
网络输入尺度:输入特征检测网络的大小,在训练时设置,源码中为224*224。
窗口分类和位置精修
分类层(cls_score)输出每一个位置上,9个anchor属于前景和背景的概率;窗口回归层(bbox_pred)输出每一个位置上,9个anchor对应窗口应该平移缩放的参数。
对于每一个位置来说,分类层从256维特征中输出属于前景和背景的概率;窗口回归层从256维特征中输出4个平移缩放参数。
就局部来说,这两层是全连接网络;就全局来说,由于网络在所有位置(共51*39个)的参数相同,所以实际用尺寸为1×1的卷积网络实现。
需要注意的是:并没有显式地提取任何候选窗口,完全使用网络自身完成判断和修正。
区域生成网络:训练
样本
考察训练集中的每张图像:
a. 对每个标定的真值候选区域,与其重叠比例最大的anchor记为前景样本
b. 对a)剩余的anchor,如果其与某个标定重叠比例大于0.7,记为前景样本;如果其与任意一个标定的重叠比例都小于0.3,记为背景样本
c. 对a),b)剩余的anchor,弃去不用。
d. 跨越图像边界的anchor弃去不用
代价函数
同时最小化两种代价:
a. 分类误差
b. 前景样本的窗口位置偏差
具体参看fast RCNN中的“分类与位置调整”段落。
超参数
原始特征提取网络使用ImageNet的分类样本初始化,其余新增层随机初始化。
每个mini-batch包含从一张图像中提取的256个anchor,前景背景样本1:1.
前60K迭代,学习率0.001,后20K迭代,学习率0.0001。
momentum设置为0.9,weight decay设置为0.0005。[5]
共享特征
区域生成网络(RPN)和fast RCNN都需要一个原始特征提取网络(下图灰色方框)。这个网络使用ImageNet的分类库得到初始参数W0,但要如何精调参数,使其同时满足两方的需求呢?本文讲解了三种方法。 
轮流训练
a. 从W0开始,训练RPN。用RPN提取训练集上的候选区域
b. 从W0开始,用候选区域训练Fast RCNN,参数记为W1
c. 从W1开始,训练RPN…
具体操作时,仅执行两次迭代,并在训练时冻结了部分层。论文中的实验使用此方法。
如Ross Girshick在ICCV 15年的讲座Training R-CNNs of various velocities中所述,采用此方法没有什么根本原因,主要是因为”实现问题,以及截稿日期“。
近似联合训练
直接在上图结构上训练。在backward计算梯度时,把提取的ROI区域当做固定值看待;在backward更新参数时,来自RPN和来自Fast RCNN的增量合并输入原始特征提取层。
此方法和前方法效果类似,但能将训练时间减少20%-25%。公布的python代码中包含此方法。
联合训练
直接在上图结构上训练。但在backward计算梯度时,要考虑ROI区域的变化的影响。推导超出本文范畴,请参看15年NIP论文[6]。
实验
除了开篇提到的基本性能外,还有一些值得注意的结论
-
与Selective Search方法(黑)相比,当每张图生成的候选区域从2000减少到300时,本文RPN方法(红蓝)的召回率下降不大。说明RPN方法的目的性更明确。

-
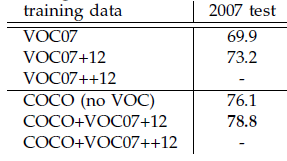
使用更大的Microsoft COCO库[7]训练,直接在PASCAL VOC上测试,准确率提升6%。说明faster RCNN迁移性良好,没有over fitting。
- Girshick, Ross, et al. “Rich feature hierarchies for accurate object detection and semantic segmentation.” Proceedings of the IEEE conference on computer vision and pattern recognition. 2014. ↩
- Girshick, Ross. “Fast r-cnn.” Proceedings of the IEEE International Conference on Computer Vision. 2015. ↩
- M. D. Zeiler and R. Fergus, “Visualizing and understanding convolutional neural networks,” in European Conference on Computer Vision (ECCV), 2014. ↩
- K. Simonyan and A. Zisserman, “Very deep convolutional networks for large-scale image recognition,” in International Conference on Learning Representations (ICLR), 2015. ↩
- learning rate-控制增量和梯度之间的关系;momentum-保持前次迭代的增量;weight decay-每次迭代缩小参数,相当于正则化。 ↩
- Jaderberg et al. “Spatial Transformer Networks”
NIPS 2015 ↩ - 30万+图像,80类检测库。参看http://mscoco.org/。 ↩