Jetson Tx2上运行的代码分析
代码来自于https://github.com/dusty-nv/jetson-inference
运行:
下载代码->按照代码的编译过程cmake->下载CmakePreBuild.sh中网址的内容(这些是网络的model),然后放到指定的位置,就可以运行程序实例
使用cgdb分析代码 比gdb好用
以程序./imagenet-console airplane_0.jpg output.jpg为例,分析程序的运行过程
imagenet-console.cpp
main()
L31 imageNet* net = imageNet::Create(argc, argv);
imageNet.cpp
L50
L58 net->init(networkType, maxBatchSize, precision, device, allowGPUFallback)
L90 init( "networks/googlenet.prototxt", "networks/bvlc_googlenet.caffemodel", NULL, "networks/ilsvrc12_synset_words.txt", IMAGENET_DEFAULT_INPUT, IMAGENET_DEFAULT_OUTPUT, maxBatchSize, precision, device, allowGPUFallback );
L125
tensorNet::LoadNetwork( prototxt_path, model_path, mean_binary, input, output,
maxBatchSize, precision, device, allowGPUFallback )
tensorNet.cpp
L468 return LoadNetwork(prototxt_path, model_path, mean_path, input_blob, outputs, maxBatchSize, precision, device, allowGPUFallback );
L 473
precision==TYPE_FASTEST
L566 gieModelStream << cache.rdbuf();这句话应该是导入模型
L624 gieModelStream.read((char*)modelMem, modelSize);将gieModelStream中的模型的参数读入到modelMem中
nvinfer1::ICudaEngine* engine = infer->deserializeCudaEngine(modelMem, modelSize, NULL) 把模型参数传递给tensorRT 应该是交给GPU的意思
综上分析 导入模型主要使用的时TensorRT的api等,所以要先学习TensorRT的开发
https://docs.nvidia.com/deeplearning/sdk/tensorrt-developer-guide/index.html
what is TensorRT:
TensorRT是用来在开发板上构建神经网络模型的工具。包括C++ API和python API
可以集成多个框架构建的模型(caffe pytorch tensorflow)
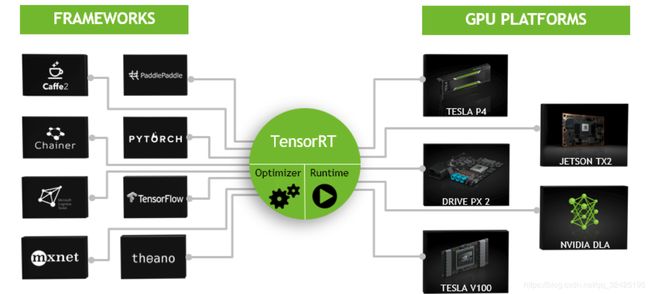
神经网络经过训练后,Tensorrt可以将网络压缩、优化并作为运行时部署,而无需框架开销。
Tensorrt结合层,优化内核选择,还根据指定的精度(fp32、fp16或int8)执行标准化和到优化矩阵数学的转换,以提高延迟、吞吐量和效率。
衡量模型的5个方面:吞吐量 效率 等待时间 准确性 内存占用
2。TensoeRT的c++ API与 python API对比
如果你有一个训练好的模型,则需要一下步骤:
- Creating a TensorRT network definition from your model
- Invoking the TensorRT builder to create an optimized runtime engine from the network
- Serializing and deserializing the engine so that it can be rapidly recreated at runtime
- Feeding the engine with data to perform inference
C++能适用于任何场景 尤其是关键场景 安全性要求很高的场景。而python API则更好用,因为有很多的库
2.1 用c++实例化TensorRT对象
先创建ICudaEngine对象(从用户的网络模型中创建或者从磁盘读取) 再创建IExecutionCOntext对象
创建Logger对象
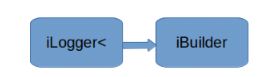
 使用
使用
使用iNetwork创建parser,来解析模型

cudaEngine
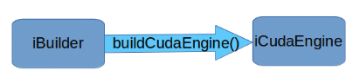


推荐在runtime或builder前创建cuda context
2.2使用c++创建模型
使用TensorRT parser导入模型

或者
使用TensorRT API直接定义模型(定义网络的各个层和参数):通过网络定义API直接将网络定义到TensorRT,而不是使用解析器。 此方案假定在网络创建期间,每层权重已准备好在主机内存中传递给TensorRT。
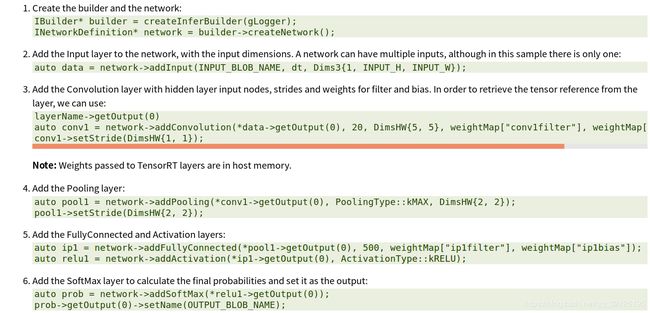
2.3 在c++中构建engine

2.4 将网络模型序列化
序列化和去序列化是可选的,避免了读取构建网络需要的较长时间。当engine构建好以后,我们就将它序列化后保存在磁盘上。以后可以从磁盘上读取,去序列化后恢复为原来的engine

3.使用python API
4.使用自定义层扩展TensorRT
4.1 使用c++增加自定义层
IPlugin V2是基类 IPluginCreator是创建者类
5.不同精度时如何工作
混合精度是在计算方法中组合使用不同的数值精度。 TensorRT可以存储权重和激活,并以32位浮点,16位浮点或量化的8位整数执行层。
使用低于FP32的精度可以减少内存使用,允许部署更大的网络。 数据传输花费的时间更少,计算性能也会提高,尤其是在Tensor Core支持该精度的GPU上。
默认情况下,TensorRT使用FP32推理,但它也支持FP16和INT8。 在运行FP16推理时,它会自动将FP32权重转换为FP16权重。

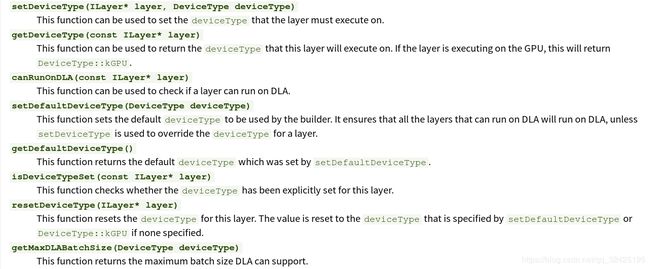
6.Working With DLA(Deep Learning Accelerator)
NVIDIA DLA(深度学习加速器)是一款针对深度学习操作的固定功能加速器引擎。 DLA旨在对卷积神经网络进行全硬件加速。 DLA支持各种层,如卷积,反卷积,完全连接,激活,池化,批量标准化等。
6.1 在DLA上运行tensorRT的推断
配置网络使用DLA
7.部署TensorRT优化模型
7.2 在嵌入式系统中部署模型
TensorRT can also be used to deploy trained networks to embedded systems such as NVIDIA Drive PX
1.将训练好的模型导出为TensorRT可以导入的形式
2.写程序(如时哟刚TensorRT C++的接口)来导入优化序列化模型
8.TensorRT与其他深度学习网络框架的协同工作
With the Python API, an existing model built with TensorFlow, Caffe, or an ONNX compatible framework can be used to build a TensorRT engine using the provided parsers. The Python API also supports frameworks that store layer weights in a NumPy compatible format, for example PyTorch.
8.3. Working With PyTorch And Other Frameworks
Using TensorRT with PyTorch and other frameworks involves replicating the network architecture using the TensorRT API, and then copying the weights from PyTorch (or any other framework with NumPy compatible weights). For more information on using TensorRT with a PyTorch model, see the network_api_pytorch_mnist Python sample.
9.C++和python的例子程序 由浅入深
10.别人的博客讲解
https://blog.csdn.net/qq_36124767/article/details/68484092
分步骤说明基本的流程(加载模型 运行等):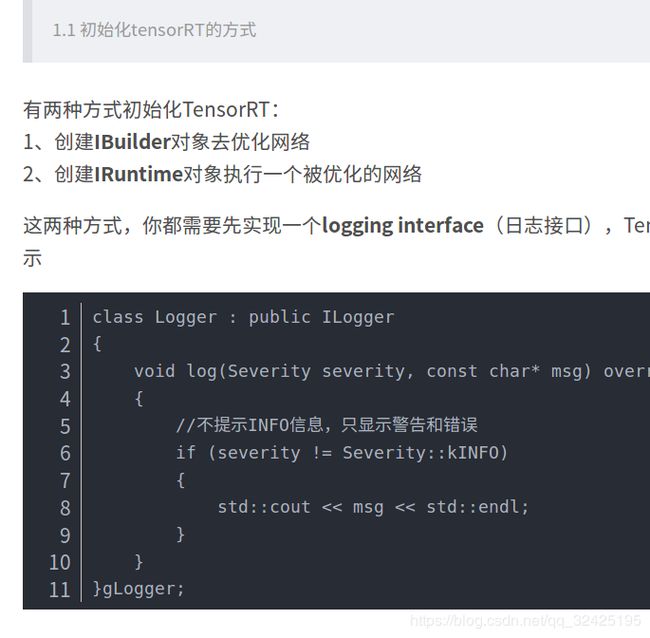
https://blog.csdn.net/xh_hit/article/details/79769599 TensorRT的加速原理
https://www.jianshu.com/p/59fe26073a41 与digits的混合使用
https://cloud.tencent.com/developer/article/1188762视频讲 解
解