RocketMQ基础概念及使用总结
一.了解RocketMQ?
rocketMQ是阿里开源的一款十分优秀的消息队列,rocketMQ具有很多其他消息队列不具有的特性,更重要的是rocketMQ是用java开发的学习成本较低,并且经历了双11的数据洪峰的考验。rocketMQ已经加入了apache,成为apache的顶级项目,最近阿里的另一款开源项目dubbo也重新开始维护。
阿里在RocketMQ 项目基础上衍生的项目如下:
com.taobao.metaq v3.0 = RocketMQ + 淘宝个性化需求为淘宝应用提供消息服务。
om.alipay.zpullmsg v1.0 = RocketMQ + 支付宝个性化需求为支付宝应用提供消息服务
com.alibaba.commonmq v1.0 = Notify + RocketMQ + B2B 个性化需求为 B2B 应用提供消息服务
目前RocketMQ的代码托管在github上:
老的地址:https://github.com/alibaba/RocketMQ
新的地址:https://github.com/apache/incubator-rocketmq
中间件比较:
https://rocketmq.apache.org/docs/motivation/
https://help.aliyun.com/document_detail/52577.html?spm=5176.7946988.881668.1.754942betpCaPZ
二.RocketMQ 是什么?
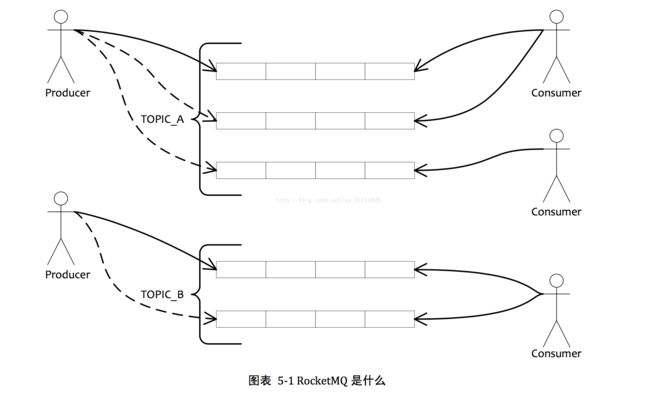
1.是一个队列模型的消息中间件,具有高性能、高可靠、高实时、分布式特点。
2.Producer、Consumer队列都可以分布式。
3.Producer向一些队列轮流发送消息,队列集合称为 Topic,Consumer 如果做广播消费,则一个consumer实例消费这个Topic 对应的所有队列,如果做集群消费,则多个Consumer 实例平均消费这个topic对应的队列集合。(默认是集群消费)
4.能够保证严格的消息顺序(因为性能原因,不能保证消息不重复,因为总有网络不可达的情况发生,需业务端保证)。
5.提供丰富的消息拉取模式
6.高效的订阅者水平扩展能力
7.实时的消息订阅机制
8.亿级消息堆积能力
9.较少的依赖
三.RocketMQ的基本概念
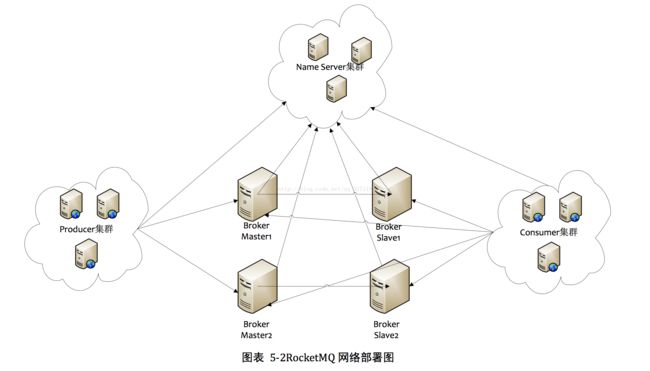
1.Name Server
它是一个几乎无状态节点,可集群部署,节点之间无任何信息同步。(2.X版本之前rocketMQ使用zookeeper做topic路由管理)。Name Server 是专为 RocketMQ设计的轻量级名称服务,代码小于1000行,具有简单、可集群横吐扩展、无状态等特点。将要支持的主备自动切换功能会强依赖 Name Server。
2. Broker
Broker 部署相对复杂,Broker分为Master与Slave,一个Master可以对应多个Slave,但是一个Slave只能对应一个Master,Master与Slave的对应关系通过指定相同的BrokerName,不同的BrokerId来定义,BrokerId为0表示Master,非0表示Slave。Master也可以部署多个。每个Broker与Name Server 集群中的所有节点建立长连接,定时注册Topic信息到所有Name Server。
3. Producer
Producer 与Name Server集群中的其中一个节点(随机选择,但不同于上一次)建立长连接,定期从Name Server取Topic路由信息,并向提供Topic服务的Master建立长连接,且定时向Master发送心跳。Producer完全无状态,可集群部署。
4. Consumer
Consumer与Name Server集群中的其中一个节点(随机选择,但不同于上一次)建立长连接,定期从Name Server 取Topic路由信息,并向提供Topic服务的Master、Slave建立长连接,且定时向Master、Slave发送心跳。Consumer既可以从Master订阅消息,也可以从Slave订阅消息,订阅规则由Broker配置决定(目前版本没有找到可配置的地方,可以在原码里修改)。
5.Producer Group
用来表示一个収送消息应用,一个Producer Group下包含多个Producer实例,可以是多台机器,也可以是一台机器的多个迕程,或者一个进程的多个Producer对象。一个Producer Group可以发送多个Topic消息,Producer Group作用如下:
1.标识一类 Producer
2.可以通过运维工具查询这个发送消息应用下有多个Producer实例
3.发送分布式事务消息时,如果 Producer中途意外宕机,Broker会主动回调 Producer Group内的任意一台机器来确认事务状态。
6.Consumer Group
用来表示一个消费消息应用,一个Consumer Group下包含多个Consumer实例,可以是多台机器,也可以是多个进程,或者是一个进程的多个Consumer对象。一个Consumer Group下的多个Consumer以均摊方式消费消息,如果设置为广播方式,那么这个 Consumer Group下的每个实例都消费全量数据。
三.生产消息
producer配置

发送消息注意事项
1.一个应用尽可能用一个Topic,消息子类型用tags来标识,tags可以由应用自由设置。只有发送消息设置了tags,消费方在订阅消息时,才可以利用tags在broker做消息过滤。 message.setTags("TagA");
2.每个消息在业务局面的唯一标识码,要设置到keys字段,方便将来定位消息丢失问题。服务器会为每个消息创建索引(哈希索引),应用可以通过topic,key来查询这条消息内 容,以及消息被谁消费。由于是哈希索引,请务必保证key尽可能唯一,这样可以避免潜在的哈希冲突。 //订单Id String orderId = "20034568923546"; message.setKeys(orderId);
3.消息发送成功或者失败,要打印消息日志,务必要打印sendresult和key字段。
4.send消息方法,只要不抛异常,就代表发送成功。但是发送成功会有多个状态,在sendResult里定义。
SEND_OK 消息发送成功
FLUSH_DISK_TIMEOUT 消息发送成功,但是服务器刷盘超时,消息已经迕入服务器队列,只有此时服务器宕机,消息才会丢失
FLUSH_SLAVE_TIMEOUT 消息发送成功,但是服务器同步到 Slave时超时,消息已经迕入服务器队列,只有此时服务器宕机,消息才会丢失
SLAVE_NOT_AVAILABLE 消息发送成功,但是此时 slave 不可用,消息已经迕入服务器队列,只有此时服务器宕机,消息才会丢失
对于精确发送顺序消息的应用,由于顺序消息的局限性,可能会涉及到主备自动切换问题,所以如果sendresult中的status字段不等于SEND_OK,就应该尝试重试。对于其他应用,则没有必要返样。
5. 对于消息不可丢失应用,务必要有消息重发机制,例如如果消息发送失败,存储到数据库,能有定时程序尝试重发,或者人工触发重发。
消息发送失败如何处理
Producer的send方法本身支持内部重试,重试逻辑如下:
1.至多重试 3 次。
2.如果发送失败,则轮转到下一个 Broker。
3.这个方法的总耗时时间不超过 sendMsgTimeout设置的值,默认10s。所以,如果本身向broker发送消息产生超时异常,就不会再做重试。
以上策略仍然不能保证消息一定发送成功,为保证消息一定成功,建议应用这样做:
如果调用send同步方法发送失败,则尝试将消息存储到db,由后台线程定时重试,保证消息一定到达Broker。
上述 db 重试方式为什么没有集成到 MQ客户端内部做,而是要求应用自己去完成,阿里主要是基于以下几点考虑:
1.MQ的客户端设计为无状态模式,方便任意的水平扩展,且对机器资源的消耗仅仅是cpu、内存、网络。
2.如果MQ客户端内部集成一个KV存储模块,那么数据只有同步落盘才能较可靠,而同步落盘本身性能开销较大,所以通常会采用异步落盘,又由于应用关闭过程不受MQ运维人员控制,可能经常会发生kill -9 这样暴力方式关闭,造成数据没有及时落盘而丢失。
3.Producer所在机器的可靠性较低,一般为虚拟机,不适合存储重要数据。
综上,建议重试过程交由应用来控制。
四.消费消息
消费过程要做到幂等(即消费端去重)
RocketMQ 无法避免消息重复,所以如果业务对消费重复非常敏感,务必要在业务局面去重,有以下几种去重方式:
1.将消息的唯一键,可以是 msgId,也可以是消息内容中的唯一标识字段,例如订单Id等,消费之前判断是否在 Db或Tair(全局KV存储)中存在,如果不存在则插入入,并消费,否则跳过。(实际过程要考虑原子性问题,判断是否存在可以尝试插入,如果报主键冲突,则插入失败,直接跳过) msgId一定是全句唯一标识符,但是可能会存在同样的消息有两个不同 msgId的情况(有多种原因),这种情况可能会使业务上重复消费,建议最好使用消息内容中的唯一标识字段去重。
2.使用业务局面的状态机去重 。
RocketMQ的Consumer都是从Broker拉消息来消费,但是为了能做到实时收消息,RocketMQ使用长轮询方式,可以保证消息实时性同Push方式一致。'
push consumer配置

pull consumer配置

message数据结构
针对producer

在Producer端,使用com.alibaba.rocketmq.common.message.Message这个数据结构,由于Broker会为Message增加数据结构,所以消息到达Consumer后,会在Message基础之上增加多个字段,Consumer看到的是com.alibaba.rocketmq.common.message.MessageExt返个数据结构,MessageExt继承于Message。
批量方式消费
某些业务流程如果支持批量方式消费,则可以很大程度上提高消费吞吏量,例如订单扣款类应用,一次处理一个订单耗时1秒钟,一次处理10个订单可能也只耗时2秒钟,这样即可大幅度提高消费的吞吐量,通过设置consumer的consumeMessageBatchMaxSize这个参数,默认是1,即一次只消费一条消息,例如设置为N,那么每次消费的 消息数小于等于N。
五.RocketMQ 存储特点
RocketMQ 参考了Kafka的持久化方式,充分利用Linux文件系统内存cache来提高性能。
Consumer消费消息过程,使用了零拷贝,零拷贝包含以下两种方式 :
1.使用 mmap + write 方式 优点:即使频繁调用,使用小块文件传输,效率也很高缺点:不能很好的利用DMA方式,会比sendfile多消耗CPU,内存安全性控制复杂,需要避免JVM Crash问题。
2.使用 sendfile 方式优点:可以利用DMA方式,消耗CPU较少,大块文件传输效率高,无内存安全新问题。 缺点:小块文件效率低于mmap方式,只能是BIO方式传输,不能使用NIO。
RocketMQ 选择了第一种方式,mmap+write方式,因为有小块数据传输的需求,效果会比sendfile更好。
数据存储结构
RocketMQ的所有消息都是持久化的,先写入系统PAGECACHE,然后刷盘,可以保证内存不磁盘都有一份数据,访问时,直接从内存读取。

集群管理够工具
http://192.168.102.35:8080/rocketmq-console/cluster/list.do
参考文档:
rocketmq开发指南-v3.2.4
RocketMQ运维指令