Keras深度学习环境配置(WIN10/GPU加速版)
Keras深度学习环境配置(WIN10/GPU加速版)
本人目前在用深度学习方法做命名实体识别。起初学习阶段因为数据量不大,所以直接用CPU来训练模型;不过真正落实到研究则需要大量数据才能训练出泛化能力强的模型,这时就要利用GPU来加速神经网络训练。
本人通过查阅资料配置好了GPU加速版的Keras框架,下面分享给大家。
一、本机配置
- 系统:WIN10 64位 企业版
- 显卡:NVIDIA GeForce GTX 1060 6GB Max-Q
二、安装内容
- CUDA 9.2
- cuDNN 9.2 v7.2.1.38
- Anaconda 5.2(Python 3.6)
- tensorflow-gpu 1.9.0
- Keras
- Pycharm 2017(安装过程略)
- Visual Studio 2017(安装过程略)
三、配置过程
1、安装CUDA
首先在确定你的显卡是否支持CUDA,可以在这里查看,如果显卡在列表中则说明支持CUDA。

然后查看显卡支持的CUDA版本,方法是进入NVIDIA控制面板==>帮助==>系统信息==>组件==>NVCUDA.DLL==>产品名称。这里我的显卡支持的CUDA版本为9.2,其他版本我尝试过,都无法成功安装。所以要安装显卡支持的CUDA版本,才能进行后续的配置。

CUDA下载地址 https://developer.nvidia.com/cuda-toolkit-archive,选择对应版本下载。
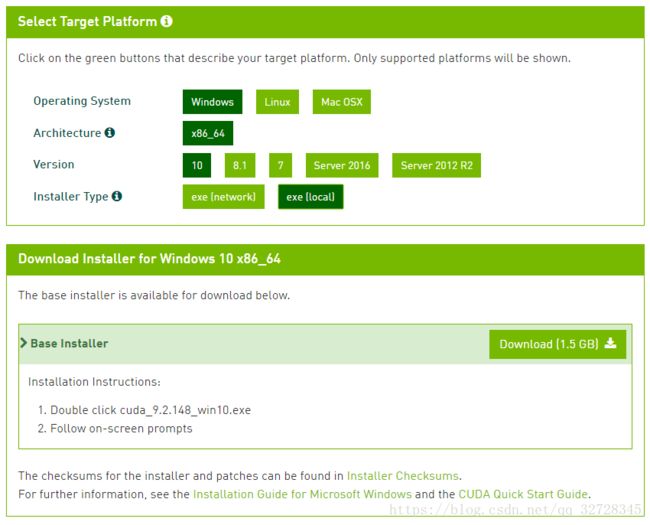
安装之前会检查系统兼容性,显卡支持当前版本CUDA时的界面如下,否则就要换成其他版本的CUDA。安装过程较简单,这里不详述(安装时需要Visual Studio或者VC++库,没有的自行下载安装即可)。

安装完成后打开命令行,输入”nvcc -V”,出现下列信息说明安装成功。

2、配置CUDA
安装成功后在我的电脑上右键,打开属性==>高级系统设置==>高级==>环境变量,可以看到系统中多了两个环境变量:CUDA_PATH 和 CUDA_PATH_V9_2,接下来我们添加如下几个环境变量:
- CUDA_BIN_PATH = %CUDA_PATH%\bin
- CUDA_LIB_PATH = %CUDA_PATH%\lib\x64
- CUDA_SDK_PATH = C:\ProgramData\NVIDIA Corporation\CUDA Samples\v9.2
- CUDA_SDK_BIN_PATH = %CUDA_SDK_PATH%\bin\win64
- CUDA_SDK_LIB_PATH = %CUDA_SDK_PATH%\common\lib\x64

接着在用户变量的Path中添加:C:\ProgramData\NVIDIA GPU Computing Toolkit\v9.2

我们打开命令行,输入”set cuda”查看配置情况,如下图所示说明配置成功。

或者,我们也可以进入 C:\Program Files\NVIDIA GPU Computing Toolkit\CUDA\v9.2\extras\demo_suite 目录,使用命令行运行 bandwidthTest 和 deviceQuery,若能看到显卡信息和 “Result = PASS”,说明CUDA配置成功。


3、下载并配置cuDNN
cuDNN是专门针对Deep Learning框架设计的一套GPU计算加速方案,它优化了一些常用的神经网络操作,比如卷积、池化、Softmax以及激活函数等,可将其视为CUDA的补丁。
下载地址为 https://developer.nvidia.com/rdp/cudnn-archive ,首先要注册账号,然后根据之前安装的CUDA版本选择相应版本的cuDNN。

下载后解压,得到一个名字为cuda的文件夹,然后将里面bin、include和lib文件夹的内容拷贝到CUDA安装目录的相应文件夹中即可(CUDA默认安装目录为:C:\Program Files\NVIDIA GPU Computing Toolkit\CUDA\v9.2)。

4、安装并配置 Anaconda
Anaconda是Python的一个发行版本,提供包管理与环境管理的功能,并集成了一些常用的科学计算、机器学习和数据处理等工具包,无需自己安装,使用起来很方便。在这里下载,本文选择的是Python3.6 64位版。

安装完成后将Anaconda根目录和Scripts文件夹加入系统变量的Path中。
![]()
打开命令行,输入”python –version”,如下图所示说明配置成功。

5、安装 tensorflow-gpu
因为我们需要GPU加速,所以要下载GPU版的tensorflow。不过,tensorflow目前还不能支持CUDA 9.2,因此只能通过源码编译进行安装,这里直接使用大神编译好的安装包,在这里下载,根据Python版本进行选择。

下载后进入其所在目录,打开命令行,输入”pip install tensorflow_gpu-1.9.0-cp36-cp36m-win_amd64.whl”进行安装。我当时安装1.8.0版本没有成功,换成1.9.0版本就成功了,所以这里建议大家多尝试。

安装后打开命令行,输入”python”进入python环境,然后输入”import tensorflow as tf”,若能正常导入tensorflow包说明安装成功,如下图所示。

6、安装 keras
打开命令行,输入”pip install keras”即可。然后打开命令行,输入”python”进入python环境,然后输入”import keras”,若能正常导入keras包说明安装成功,如下图所示。

这里我们看到一句日志输出:Using TensorFlow backend。因为Keras是一个模型级的库,它本身并不处理张量加减乘除、卷积等底层操作,而是依赖于某种特定的、优化良好的张量操作库完成,这些张量操作库称为Keras的“后端引擎”。
Keras提供了三种后端引擎Theano/Tensorflow/CNTK。我们可以进入C:\Users\Administrator\.keras目录,打开keras(JSON格式),内容如下图所示。其中,”backend”属性的值为”tensorflow”,说明Keras默认的后端引擎为TensorFow。

如果采用TensorFlow作为后端,当机器上有可用的GPU时,代码会自动调用GPU进行并行计算。
四、GPU运行测试
至此,我们的配置工作已经完成,接下使用minst数据集训练CNN来测试程序是否使用GPU进行计算,代码可以从这里获取。本人使用的IDE为Pycharm,在这里下载,安装后需要设置Python解释器,如下图所示,然后就可以运行测试程序了。

第一次迭代前输出如下日志信息,说明接下来要使用GPU来训练神经网络,也就代表GPU加速的Keras深度学习环境配置成功!
