实习:slam算法的学习整理
1.odom
2.updata_odom
3.updata_laser
updata_landmark
4.resample pf.c
相机的位姿转换是基于世界坐标系的,观察到的路标也会在世界坐标系中不断收敛,若不是计算错误,基本上不会产生漂移。而IMU是自身坐标系标定的,在转换到世界坐标系时候一定会产生误差,时序累积必定产生漂移。两种方式的优缺点互补,这就引发视觉SLAM的融合思想,既是SensorFusion。
闭环检测一般使用词袋模型作为场景匹配方法。而作为一个场景识别问题,闭环检测可以看做是一个视觉系统的模式识别问题。所以可以使用各种机器学习的方法来做,比如什么决策树/SVM,也可以试试Deep Learning。不过实际当中要求实时检测,没有那么多时间训练分类器。所以SLAM更侧重在线的学习方法。
无论使用什么混合权重,权重加总应该等于1。
odom_model_type是"diff",那么使用sample_motion_model_odometry算法,这种模型使用噪声参数odom_alpha_1到odom_alpha4。 如果是"omni" 模型用于全向底座,使用噪声参数odom_alpha_1到odom_alpha_5。前4个参数类似于“diff”模型,第5个参数用于捕获机器人在垂直于前进方向的位移(没有旋转)趋势。
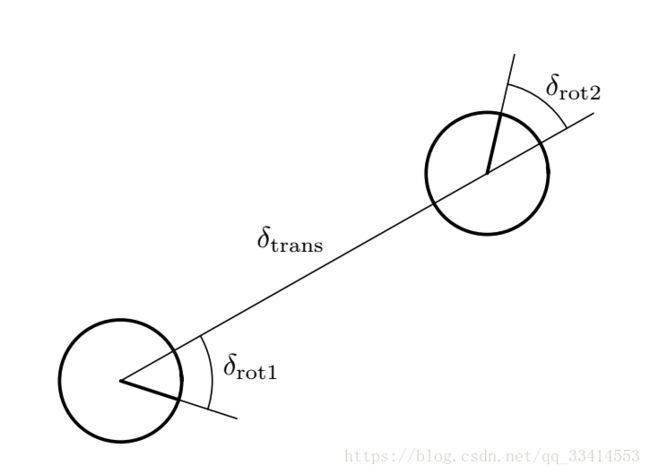
运用高斯分布表达噪声模型,则运动模型算法流程如下:

采用采样方式表达运动模型,主要运用于粒子滤波算法中(学习重点):

描述机器人制图Mapping(占用概率栅格地图和cost-map)的时候做如下假设:机器人的位姿已知。这样制图问题就变成了单纯地图更新的过程。
描述机器人定位问题的时候假设:环境地图Map已知。
地图可以分为如下几种类型:度量地图Metric Map、拓扑地图、语义地图
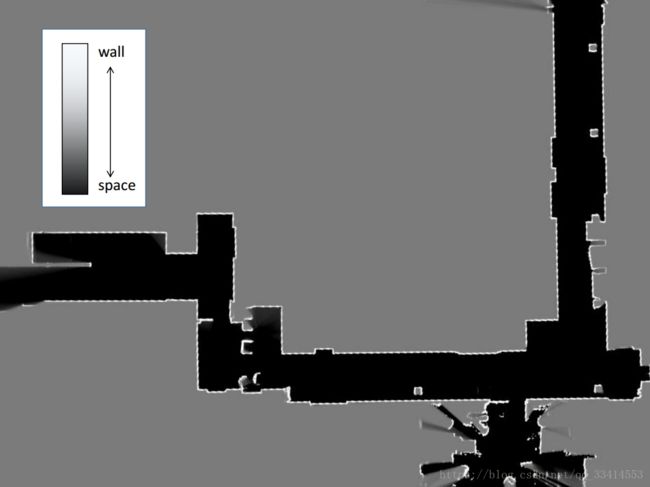
占用概率栅格地图是一种栅格地图,栅格中的值通常为概率值。主要使用栅格地图,简单来说就是占据的地方变黑,障碍物为白,不使用的地方为灰。
cost地图主要用于路径规划,用于描述环境中的障碍物和自由空间。通常也用栅格地图表示,常见的整体代价地图和分层代价地图。
https://zhuanlan.zhihu.com/p/21738718
发现一个牛逼的东西:https://github.com/yhexie/ROS-Academy-for-Beginners
有中国大学的各种仿真demo
Beam Model叫做测量光束模型。完全的物理模型,只针对激光发出的测量光束建模。将一次测量误差分解为四个误差。
phhit,测量本身产生的误差,符合高斯分布。phxx,由于存在运动物体产生的误差。
Likehood field,似然场模型,和测量光束模型相比,考虑了地图的因素。不再是对激光的扫描线物理建模,而是考虑测量到的物体的因素。似然比模型本身是一个传感器观测模型,之所以可以实现扫描匹配,是通过划分栅格,步进的方式求的最大的Score,将此作为最佳的位姿。
https://github.com/yhexie
www.cnblogs.com/yhlx125/
牛逼的博客。
调用Global_localization服务虽然可以完成小车的自主初始化位姿,但是粒子收敛时间很长,平均在90s左右,如果减少相对粒子数min_particles,max_particles,收敛时间会相对减小。Amcl中默认的最小,最大粒子数分别为500,5000。
粒子的数量是粒子滤波器发挥较好作用的关键环节。当粒子数量较多的时候,能够降低粒子飘移带来的不良影像。但是这样会增加计算负荷,进而影响滤波的效果。对于例子数量增多带来的计算量大的问题,使用KLD采样方法。
KLD采样产生是通过观测两个概率分布不同的KL距离。KL距离是用于表示概率分布p和概率分布q之间的逼近误差。
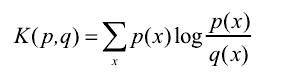
逼近误差定义:
在AMCL当中采用KLD采样算法可以动态调整粒子的数量
2DSLAM问题通常被认为是后验概率估计问题。其解决方案大多数是基于贝叶斯滤波器的概率模型方法。根据随机估计可知,整个SLAM问题可以描述成求解如下分布:
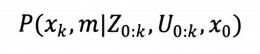
递归的贝叶斯估计方法主要分成预测和更新两步,
https://blog.csdn.net/David_Han008/article/details/68926189
A*算法博客 : theory.stanford.edu/~amitp/GameProgramming/AStarComparison.html
路径规划博客:https://blog.csdn.net/changbaohua/article/details/3860307
https://blog.csdn.net/hulizhi321/article/details/79631008