hadoop集群环境搭建之伪分布式集群环境搭建(一)
hadoop集群环境搭建之伪分布式集群环境搭建(一)
1、Linux基本环境配置
1.1 虚拟机网络模式选择NAT
一般虚拟机默认是NAT模式
1.2 修改主机名
vim /etc/sysconfig/network
NETWORKING=yes
HOSTNAME=zhang # 主机名1.3 修改IP
切换root的用户,修改/etc/sysconfig/network-scripts/ifcfg-eth0文件
有的是/etc/sysconfig/network-scripts/ifcfg-eno16777736文件
vim /etc/sysconfig/network-scripts/ifcfg-eth0
TYPE=Ethernet
IPV4_FAILURE_FATAL=no
IPV6INIT=yes
IPV6_AUTOCONF=yes
IPV6_DEFROUTE=yes
IPV6_FAILURE_FATAL=no
NAME=eno16777736
UUID=2ce59a48-ae92-483b-a73c-7844147b6ba0
HWADDR=00:0C:29:21:8D:08
PREFIX0=24
DEFROUTE=yes # 是否把这个eth设置为默认路由,设置为yes
BOOTPROTO=static # 设置static
ONBOOT=yes # 开始机自动网络
IPADDR=192.168.108.99 # 设置IP
NETMASK=255.255.255.0 # 子网掩码
GATEWAY0=192.168.108.2 # 设置网关
DNS1=192.168.108.2 #和网关保持一致就行1.4 修改主机名和IP的映射关系
以root用户,打开/etc/hosts文件
vim /etc/hosts
192.168.108.99 zhang修改/etc/hostname中文件
vim /etc/hostname
zhang1.5 关闭防火墙
#查看防火墙状态
service iptables status
#关闭防火墙
service iptables stop
#查看防火墙开机启动状态
chkconfig iptables --list
#关闭防火墙开机启动
chkconfig iptables off1.6 修改sudo
切换到root用户下
su root修改/etc/sudoers文件权限,不然修改不了该文件
chmod u+w /etc/sudoers打开/etc/sudoers文件
vim /etc/sudoers给用户添加执行的权限
# hadoop 用户名
hadoop ALL=(root) NOPASSWD:ALL1.7 关闭linux图形化界面
centos 7以下版本:
vim /etc/inittab
id:5:initdefault:
改为
id:3:initdefault:centos 7.x版本:
- 删除已经存在的符号链接
rm /etc/systemd/system/default.target- 默认级别转换为3
# 默认级别转换为3(文本模式)
ln -sf /lib/systemd/system/multi-user.target /etc/systemd/system/default.target
# 默认级别转换为5(图形模式)
ln -sf /lib/systemd/system/graphical.target /etc/systemd/system/default.target- 重启
reboot如果需要切换图形界面执行命令:startx
2、Linux之java环境安装
在CentOS 7.x的Linux操作系统下,会自带openjdk的环境,如果我们想自己安装jdk环境,需要卸载自带的openjdk环境。
步骤如下:
2.1 查看java环境
java -version2.2 查询jdk
# 查看linux的jdk
rpm -qa | grep jdk2.3 删除jdk
# 移除openjdk
yum -y remove java-openjdk-xxxxxjava-openjdk-xxxxx :是需要删除的openjdk
删除自带的openjdk环境后,我们就开始安装我们的jdk。
2.4 从Windows或其他机器获取tar包
# 将文件传出Linux中的用户目录
scp D:/dsoftmanager/jdk-8u151-linux-x64.tar.gz root@192.168.108.99:/home/hadoopD:/dsoftmanager/jdk-8u151-linux-x64.tar.gz:A机器的tar包目录位置
[email protected]:/home/hadoop:linux机器存储tar的目录位置
2.5 解压tar包到指定的目录
# 创建java目录
mkdir /java
# 将文件复制到java目录
cp /home/hadoop/jdk-8u151-linux-x64.tar.gz /java
# 进入/java
cd /java
# 解压缩
tar -zxvf jdk-8u151-linux-x64.tar.gz 2.6 配置环境变量
# 打开配置文件
vim /etc/profile打开/etc/profile文件,在文件的末尾,放入下面的配置信息:
# 配置java环境
JAVA_HOME=/java/jdk1.8.0_151
PATH=$PATH:$JAVA_HOME/bin:/usr/bin:/usr/sbin:/bin:/sbin:/usr/X11R6/bin
CLASSPATH=.:$JAVA_HOME/lib/tools.jar:$JAVA_HOME/lib/dt.jar
export JAVA_HOME PATH CLASSPATH2.7 重启机器
# 立即重启机器
shutdown -r now
或者
reboot如果不重启,配置不会生效。
2.8 java环境测试
# 测试java环境是否安装成功
java -version
javac -version出现如下信息,表示安装成功。
[hadoop@localhost Desktop]$ java -version
java version "1.8.0_151"
Java(TM) SE Runtime Environment (build 1.8.0_151-b12)
Java HotSpot(TM) 64-Bit Server VM (build 25.151-b12, mixed mode)
[hadoop@localhost Desktop]$ javac -version
javac 1.8.0_1513、hadoop伪分布式集群环境搭建
关于Linux机器环境和java环境配置,参考我的上一篇文章:hadoop集群环境搭建之Linux基本环境和java环境配置(一),在Linux环境和java环境配置好之后,我们开始搭建hadoop的伪分布式集群(伪分布式集群:在一台机器上跑hadoop需要的服务)吧。
3.1 上传hadoop安装包
scp d:/dsoftmanager/hadoop-2.7.5.tar.gz root@192.168.108.99:/home/hadoop3.2 解压安装包
# 创建一个hadoop的目录
mkdir /hadoop
# 将/home/hadoop目录下的hadoop-2.7.5.tar.gz文件复制到/hadoop目录下
cp /home/hadoop/hadoop-2.7.5.tar.gz /hadoop
# 进入/hadoop目录
cd /hadoop
# 解压
tar -zxvf hadoop-2.7.5.tar.gz3.3 配置hadoop环境变量
# 打开配置文件
vim /etc/profile
# 在配置文件中末尾输入
export HADOOP_HOME=/hadoop/hadoop-2.7.5
export PATH=$PATH:$JAVA_HOME/bin:$HADOOP_HOME/bin:$HADOOP_HOME/sbin重启Linux,测试hadoop配置是否生效
# 重启
reboot
# 测试hadoop环境配置是否生效
echo ${HADOOP_HOME}输出:/hadoop/hadoop-2.7.5
3.4 修改hadoop配置
3.4.1 将
${HADOOP_HOME}设置权限许可sudo chown -R hadoop:hadoop ${HADOOP_HOME}3.4.2 配置
hadoop-env.sh的JAVA_HOME参数# 使用sudo命令,打开hadoop-env.sh文件 sudo vim ${HADOOP_HOME}/etc/hadoop/hadoop-env.sh # 修改JAVA_HOME的环境配置为如下所示: export JAVA_HOME=/java/jdk1.8.0_1513.4.3 配置core-site.xml文件
# 创建一个tmp目录 mkdir ${HADOOP_HOME}/tmp # 设置权限 sudo chown hadoop:hadoop ${HADOOP_HOME}/tmp # 打开core-site.xml文件 sudo vim ${HADOOP_HOME}/etc/hadoop/core-site.xml # 在<configuration>中添加配置 <configuration> <property> <name>fs.defaultFSname> <value>hdfs://zhang:9000value> property> <property> <name>hadoop.tmp.dirname> <value>/hadoop/hadoop-2.7.5/tmpvalue> property> configuration>3.4.4 配置hdfs-site.xml文件
<configuration> <property> <name>dfs.replicationname> <value>1value> property> <property> <name>dfs.secondary.http.addressname> <value>192.168.108.99:50090value> property> configuration>3.4.5 配置mapred-site.xml文件
# 将mapred-site.xml.template改为mapred-site.xml sudo mv mapred-site.xml.template mapred-site.xml # 配置mapred-site.xml <configuration> <property> <name>mapreduce.framework.namename> <value>yarnvalue> property> configuration>3.4.6 配置yarn-site.xml文件
<configuration> <property> <name>yarn.resourcemanager.hostnamename> <value>zhangvalue> property> <property> <name>yarn.nodemanager.aux-servicesname> <value>mapreduce_shufflevalue> property> configuration>
3.5 格式化namenode
hdfs namenode -format格式化成功会在${HADOOP_HOME}/tmp/dfs/name/current/目录生成几个文件,表示成功,如下:

3.6 启动各个服务
进入${HADOOP_HOME}目录
3.6.1 启动namenode
# 启动namenode sbin/hadoop-daemon.sh start namenode出现如下结果,表示启动成功

3.6.2 启动datanode
# 启动datanode sbin/hadoop-daemon.sh start datanode出现如下结果,表示启动成功

3.6.3 启动SecondaryNameNode
# 启动secondarynamenode sbin/hadoop-daemon.sh start secondarynamenode出现如下结果,表示启动成功

3.6.4 启动Resourcemanager
# 启动resourcemanager sbin/yarn-daemon.sh start resourcemanager出现如下结果,表示启动成功

3.6.5 启动nodemanager
# 启动nodemanager sbin/yarn-daemon.sh start nodemanager出现如下结果,表示启动成功

3.6.6 使用
jsp命令查看是否启动成功
3.6.7 启动
dfs服务和yarn服务的另外方式# 开启dfs,包括namenode,datanode,secondarynamenode服务 sbin/start-dfs.sh # 开启yarn,包括resourcemanager,nodemanager sbin/start-yarn.sh # 开启所有的服务(过时) sbin/start-all.sh在执行启动时,需要输入用户密码
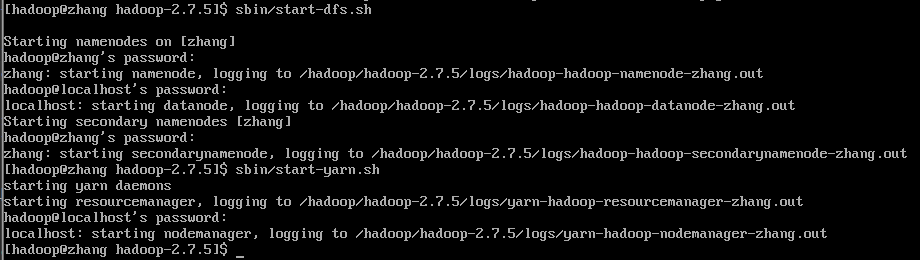
3.6.8 打开yarn的web页面
YARN的Web客户端端口号是8088,通过http://192.168.108.99:8088/可以查看。

3.7 运行MapReduce Job
在Hadoop的share目录中,自带jar包,里面有一些MapReduce的例子,位置在share/hadoop/mapreduce/hadoop-mapreduce-examples-2.7.5.jar。我们可以使用这些例子体验搭建好的Hadoop平台。我们以wordCount为例。
3.7.1 创建输入目录
# 进入${HADOOP_HOME}目录 cd ${HADOOP_HOME} # 创建输入目录 bin/hdfs dfs -mkdir -p /wordcounttest/input3.7.2 创建测试文件wc.input,内容如下:
在
${HADOOP_HOME}目录下,创建一个data目录。在data目录下创建一个wc.input文件,文件内容:# 创建data目录 mkdir data # 进入data目录 cd data # 创建wc.input vim wc.input # 在文件中输入,如下内容 hadoop mapreduce hive hbase spark storm sqoop hadoop hive spark hadoop3.7.3 将wc.input文件上传到HDFS的
/wordcounttest/input目录下:bin/hdfs dfs -put data/wc.input /wordcounttest/input3.7.4 查看
/wordcounttest/input目录bin/hdfs dfs -ls /wordcounttest/input
3.7.5 运行WordCount MapReduce Job
bin/yarn jar share/hadoop/mapreduce/hadoop-mapreduce-examples-2.7.5.jar wordcount /wordcounttest/input /wordcounttest/output
3.7.6 查看输出结果目录
bin/hdfs dfs -ls /wordcounttest/output
output目录中有两个文件,_SUCCESS文件是空文件,有这个文件说明Job执行成功。
part-r-00000文件是结果文件,其中-r-说明这个文件是Reduce阶段产生的结果。
3.7.7 查看输出文件结果
bin/hdfs dfs -cat /wordcounttest/output/part-r-00000
3.8 停止Hadoop服务
# 停止namenode
sbin/hadoop-daemon.sh stop namenode
# 停止datanode
sbin/hadoop-daemon.sh stop datanode
# 停止resourcemanager
sbin/yarn-daemon.sh stop resourcemanager
停止nodemanager
sbin/yarn-daemon.sh stop nodemanager停止Hadoop服务的其他方式
# 停止dfs服务
sbin/stop-dfs.sh
# 停止yarn服务
sbin/stop-yarn.sh
# 停止所有服务
sbin/stop-all.sh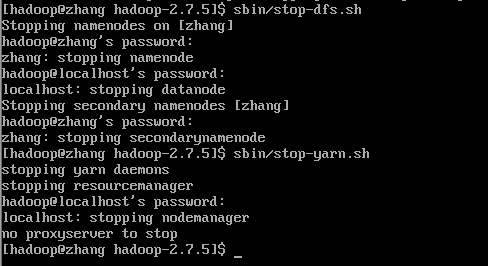
注1:开启历史服务
sbin/mr-jobhistory-daemon.sh start historyserver可以通过http://192.168.108.99:19888打开,可看到JobHistory页面
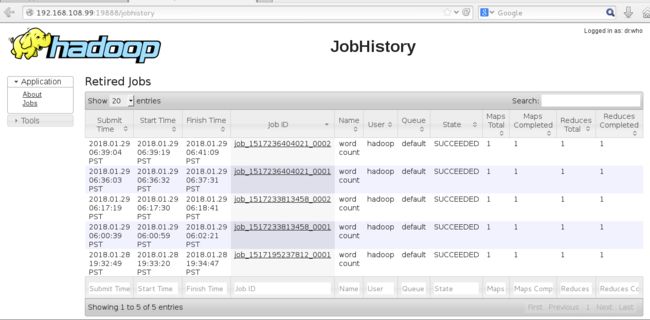
点击进去,可看见Job的详情页面。
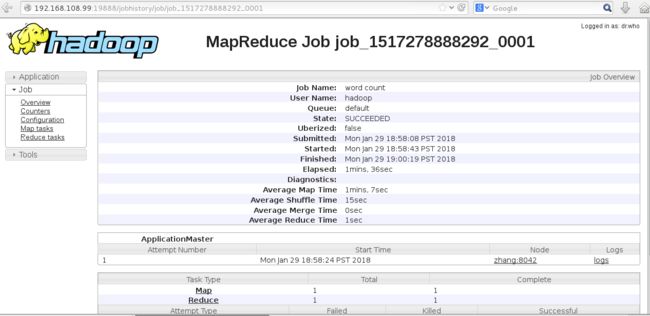
注2:开启日志
hadoop默认不启动日志,我们可以在yarn-site.xml文件中配置启用日志。
- 1.log环境配置
<property>
<name>yarn.log-aggregation-enablename>
<value>truevalue>
property>
<property>
<name>yarn.log-aggregation.retain-secondsname>
<value>106800value>
property>- 2.重启Yarn进程
# 停止yarn服务
sbin/stop-yarn.sh
# 启动yarn服务
sbin/start-yarn.sh- 3.重启HistoryServer进程
# 停止HistoryServer服务
sbin/mr-jobhistory-daemon.sh stop historyserver
# 开启HistoryServer服务
sbin/mr-jobhistory-daemon.sh start historyserver- 4.测试日志,运行一个MapReduce的demo,产生日志
bin/yarn jar share/hadoop/mapreduce/hadoop-mapreduce-examples-2.7.5.jar wordcount /wordcounttest/input /wordcounttest/output2- 5.查看日志:
进入MapReduce的Job页面
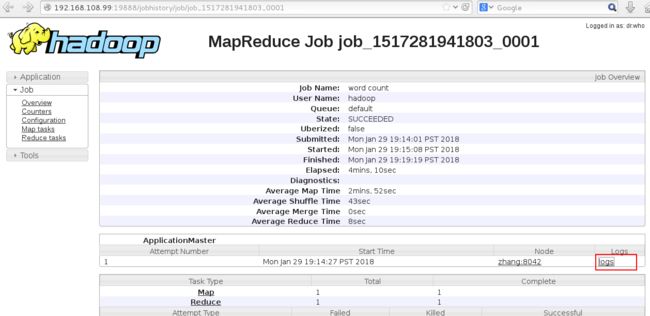
点击进入log页面,如下
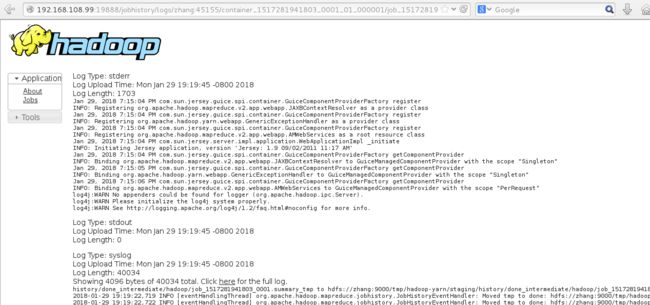
如果没有配置yarn-site.xml中的log配置,不会出现log,而是一串提示文字。