Python爬虫实战之通过ajax获得图片地址实现全站图片下载(三)
Python 爬虫多线程实现下载图片
本篇文章可能跟上一篇有点像 只是换了个页面 然后搞定他的ajax 通过直接访问ajax的接口来实现图片的下载 因为再源代码中已经没有办法显示他的url链接了
这样的访问也称为异步访问 同步的话 是在网页中直接看到源码
异步访问的优点是 网页加载速度快
爬取网址:http://www.mmjpg.com/
一.获得主页上所有的图片链接地址

1.首先按f12 点击elemnts

2.点击下图的小箭头 选择主图中的任意一个图片 那我们这里点击第一个 图片

3.获得url 如下图
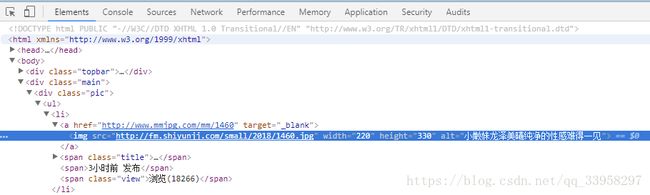
4.显示控制台 为了验证xpath是否正确
5.通过xpath获得href和名字

这里可以看到 一共获得了15个这样的地址 为什么是15个呢
因为 主页上的主图就15个 所以 这里获得的没有问题 那么留着
6.获得图片的url.
![]()
7.获得接口地址.
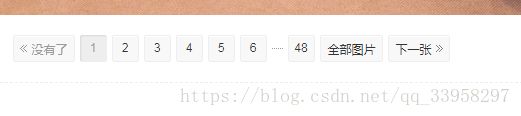
找个图进入之后 我们可以看到下方有页面选择 然后还一个全部图片
如果按照第一篇文章的方法来的话 肯定是点击一页 然后下载
这样的话 效率非常低
但是其他又给我们提供好了 一个接口等于
只要点击全部图片 就可以返回接口数据
这里我们需要获得第一张的图片地址 为后面的操作做准备
8.构造图片名称,实现下载.
这里是重点了:
其实正常来说 已经是看js代码的 但是因为程序会自己按照js里写的代码来执行,而且既然是异步 那么他肯定也是需要发包的 那么我们只要截取他发布的地址 就可以实现获得这个接口 清理的目的 有就是为了能看清楚 发的什么包
首先 点击network 点击那个清理的
然后 点击全部图片

可以看到 他发了一个data.php的一个包出去 而且是xhr正说明是使用ajax
那么我们看一下 他返回了什么

我们发现他返回了一堆好像看不懂的东西 但是有感觉好像哪里有见过其中的几个
其实只要看左边的后两个图的名字 就知道了
左边这两个图的名字 是2ide 3i9p 正好发现和这个返回的值中第二个和第三个值有一样的部分 那会不会是巧合呢 为了验证我们的猜想 我们回到elements选项卡
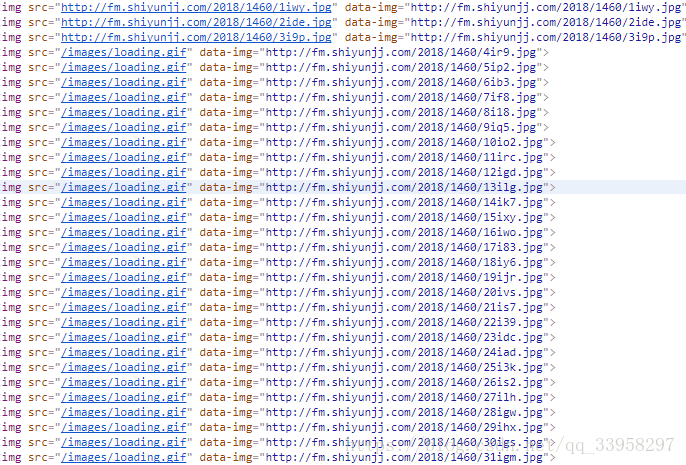
可以看到 好像和我们的猜想是一样的
但是他只返回了2个字符 但是图片是需要4个字符
我们仔细看一下 其实他是有规律的
会发现 第一个字符是按照顺序排下来的 也就是说 有多少个图片他就会从1一直到多少
第二个字符是固定的值i
这样的话 我们自己就可以构造这个图片的名字 直接实现发包进行下载 也就完全不用每次都访问每页再下载了
9.获取下图图片的请求头

如果出现上图这样 一般是缓存导致的 最好的清理缓存 把所有的页面关闭
使用无痕重新访问就可以看到全部的请求头了

10. 我们这里没有获得一共有多少页,因为在ajax中返回的就是对应的值 只要把这里面的所有的字符串用完就下载完毕了。
二.编写代码实现下载
1. 需要用到的库有:
Requests lxml 如果没有安装的请自己安装一下
2. IDE : pycharm
3.python版本 :2.7.15
4.代码实现的是多线程下载,多线程的好处 就不用我多说了。
#!/usr/bin/env python
# -*- coding: utf-8 -*-
from threading import *
import requests
from lxml import etree
import os
gHeads = {
"User-Agent":"Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/55.0.2883.87 Safari/537.36",
}
nMaxThread = 3 #需要几条线程就设置几条
ThreadLock = BoundedSemaphore(nMaxThread)
class PhotoThread(Thread):
def __init__(self,url):
Thread.__init__(self)
self.url = url
def run(self):
try:
PhotoName,firsturl,uid = self.GetPhotoInfo(self.url)
if uid :
secName = self.GetPhotoRandomName(uid)
if secName:
self.DownloadPhoto(firsturl,secName,uid,PhotoName)
finally:
ThreadLock.release()
def GetPhotoInfo(self,url):
heads = {
"Host": "www.mmjpg.com",
"Referer": "http://www.mmjpg.com/"
}
heads.update(gHeads)
try:
html = requests.get(url,headers=heads)
if html.status_code == 200:
html.encoding="utf-8"
xmlContent = etree.HTML(html.text)
PhotoName = xmlContent.xpath("//div[@class='article']/h2/text()")[0] #这里使用的h2标签中的内容 并没有使用文章中的值 好处可以自己感受下
imgUrl = xmlContent.xpath("//div[@class='content']/a/img/@src")[0]
firstImgUrl = imgUrl[:imgUrl.rfind("/")]
uid = firstImgUrl[firstImgUrl.rfind("/")+1:]
return PhotoName,firstImgUrl,uid
except:
return None,None
def GetPhotoRandomName(self,uid):
heads = {
"Host":"www.mmjpg.com",
"Referer":"http://www.mmjpg.com/mm/%s"%(uid)
}
heads.update(gHeads)
try:
html = requests.get("http://www.mmjpg.com/data.php?id=%s&page=8999"%(uid),headers=heads).text
retName = html.split(",")
return retName
except:
return None
def DownloadPhoto(self,firstUrl,randomName,uid,photoName):
#http://img.mmjpg.com/2018/1367/2ig6.jpg
heads = {
"Host": "img.mmjpg.com",
"Referer":"http://www.mmjpg.com/mm/%s"%(uid)
}
heads.update(gHeads)
savePath = "./photo/%s"%photoName
if not os.path.exists(savePath):
os.makedirs(savePath)
for i in xrange(len(randomName)):
url = "%s/%si%s.jpg"%(firstUrl,i+1,randomName[i])
html = requests.get(url,headers=heads)
print "Download : %s/%d.jpg"%(photoName.encode("gbk"),i+1)
if html.status_code == 200 :
with open("%s/%d.jpg"%(savePath,i+1),"wb") as f:
f.write(html.content)
#sleep(0.2)
else:
return None
def main():
while True:
try:
nMaxPage = int(raw_input("请输入需要几页: "))
if nMaxPage > 0:
break
except ValueError:
continue
for i in xrange(nMaxPage):
url = "http://www.mmjpg.com/" if i == 0 else "http://www.mmjpg.com/home/%d"%(i+1)
html = requests.get(url,headers=gHeads).text
xmlContent = etree.HTML(html)
urlList = xmlContent.xpath("//div[@class='pic']/ul/li/a/@href")
for url in urlList:
ThreadLock.acquire()
t = PhotoThread(url)
t.start()
if __name__ == '__main__':
main()5.成果
