Redis数据结构详解以及常见的使用方法与场景
Redis数据结构详解以及常见的使用方法与场景
Redis数据类型
与Memcached仅支持简单的key-value结构的数据记录不同,Redis支持的数据类型要丰富得多,常用的数据类型主要有五种:String、List、Hash、Set和Sorted Set。另外还有两种:Bitmaps,HyperLoglog
Redis数据类型内存结构分析
Redis内部使用一个redisObject对象来表示所有的key和value。redisObject主要的信息包括数据类型(type)、编码方式(encoding)、数据指针(ptr)、虚拟内存(vm)等。type代表一个value对象具体是何种数据类型,encoding是不同数据类型在redis内部式。
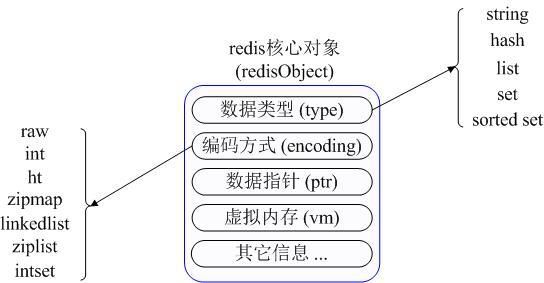
redisObject 对象示意图
下面分别介绍5种数据类型的用法。
String类型
字符串是Redis值的最基础的类型。Redis中使用的字符串是通过包装的,基于c语言字符数组实现的简单动态字符串(simple dynamic string, SDS)一个抽象数据结构。其源码定义如下:
struct sdshdr {
int len; //len表示buf中存储的字符串的长度。
int free; //free表示buf中空闲空间的长度。
char buf[]; //buf用于存储字符串内容。
};
![]()
C语言字符串内存结构示意图1
假设上图是”hello”字符串的内存结构,这个时候len=5,free=2那么redis包装后(sds)其长度为:
sizeof(struct sdshdr) + len + free + 1
其中buf的大小为:
len + free + 1
1表示1个字节是用来存储结束符’\0’的。Redis字符串是二进制安全的,因为二进制数据通常会有中间某个字节存储’\0’的这种情况,这意味着一个Redis字符串可以包含任何种类的数据,例如一个JPEG图像或者一个序列化的Ruby对象。二进制是否安全,简单的理解就是能不能在字符串中间有‘\0’,如下图:
![]()
C语言字符串内存结构示意图2
对于上图,sds认为这个字符串是“hello world”,而C语言的字符处理函数认为这个字符串是“hello”。
典型应用场景
- 缓存功能: String是最常用的一种数据类型,普通的key/value存储都可以归为此类。通常用于作为缓存层,mysql等关系型数据库作为存储层,绝大部分请求的数据都是从Redis中获取,由于redis具有支撑高并发的特性。与mysql等关系型数据库不同的是,redis没有命令空间,且没有对健名有强制要求(除了不能使用一些特殊字符)。因此设计合理的健名,有利于防止健冲突和项目的可维护性,比较推荐的方式是“业务名:对象名:id:[属性]”作为健名。
例如:mysql的数据库名是vs,用户名为user,那么对应的健可以用“vs:user:1”,"vs:user:1:name"来表示。
- 计算:许多应用都会使用Redis作为计数的基础工具,它可以实现快速计数、查询缓存的功能,同事数据可以异步落地到其他数据源。例如视频播放次数,微博点赞数等。
- 共享session:单点登陆,将session集中管理。这种功能下需要保证redis的高可用性和扩展性。
- 限速:很多应用出于安全考虑,会在每次进行登陆时,提示用户输入手机验证码,从而确定用户是否是本人。但是短信接口不能被频繁访问,因此需要限制用户每分钟获取验证码,除了前端做时间限制之外,后端可以使用redis来生成一个有expire过期时间的key,key存在则不允许访问。
常用命令
(1)set——设置key对应的值为String类型的value
(2)get——获取key对应的值
(3)mget——批量获取多个key的值,如果可以不存在则返回nil
(4)incr && incrby——incr对key对应的值进行加加操作,并返回新的值;incrby加指定值
(5)decr && decrby——decr对key对应的值进行减减操作,并返回新的值;decrby减指定值
(6)其他命令
| 命令 |
说明 |
| setnx |
设置key对应的值为String类型的value,如果key已经存在则返回0 |
| setex |
设置key对应的值为String类型的value,并设定有效期 |
| setrange |
设置key对应value的子字符串 |
| getrange |
获取key对应value的子字符串 |
| mset |
批量设置多个key的值,如果成功表示所有值都被设置,否则返回0表示没有任何值被设置 |
| msetnx |
同mset,不存在就设置,不会覆盖已有的key |
| getset |
设置key的值,并返回key旧的值 |
| append |
给指定key的value追加字符串,并返回新字符串的长度 |
| strlen |
取指定key的value的长度 |
Hash类型
Hash是一个String类型的field和value之间的映射表,即redis的Hash数据类型的key(hash表名称)对应的value实际的内部存储结构为一个HashMap,因此Hash特别适合存储对象。相对于把一个对象的每个属性存储为String类型,将整个对象存储在Hash类型中会占用更少内存。
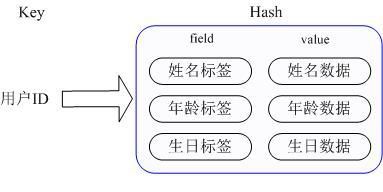
Hash 数据类型内部结构示意图
当前HashMap的实现有两种方式:当HashMap的成员比较少时Redis为了节省内存会采用类似一维数组的方式来紧凑存储,而不会采用真正的HashMap结构,这时对应的value的redisObject的encoding为zipmap,当成员数量增大时会自动转成真正的HashMap,此时encoding为ht。
应用场景
用一个对象来存储用户信息,商品信息,订单信息等等。
例如:UserInfo对象,可以直接redis.hmset(key,userInfoMap),也就是把对象变成属性值键值对形式存储。
通常使用redis存储对象有三种方式
(1)原生字符串每个属性一个键。优点:简单直观,属性操作方便,缺点:占用键过多,内存消耗较多,信息内聚性差,不建议使用。
(2)序列化字符串。将对象序列化,可以是json,xml。优点:简化编程。缺点:序列化反序列化有开销。
(3)哈希。每个对象属性使用一组键值对,然而总体只有一个键。优点:简单直观。缺点:存在哈希ziplist和hashtable两种内部编码转化,hashtable会消耗更多内存。当value大于64字节或者field(属性)个数超过512,内部编码会变成hashtable。
常用命令
(1)hset——设置key对应的HashMap中的field的value
(2)hget——获取key对应的HashMap中的field的value
(3)hgetall——获取key对应的HashMap中的所有field的value
(4)其它命令
| 命令 |
说明 |
| hsetnx |
设置key对应的HashMap中的field的value,如果不存在则先创建 |
| hmset |
批量设置key对应的HashMap中的field的value |
| hmget |
批量获取key对应的HashMap中的field的value |
| hincrby |
给key对应的HashMap中的field的value加指定的值 |
| hexits |
测试key对应的HashMap中的field是否存在 |
| hlen |
返回key对应的HashMap中的field的数量 |
| hdel |
删除key对应的HashMap中的field |
| hkeys |
返回key对应的HashMap中所有的field |
| hvals |
返回key对应的HashMap中所有的field的value |
List类型
Redis的List类型其实就是每一个元素都是String类型的双向链表。我们可以从链表的头部和尾部添加或者删除元素。这样的List既可以作为栈,也可以作为队列使用。

List数据结构内部示意图
应用场景
如好友列表,粉丝列表,消息队列,最新消息排行等。
消息队列:生产者客户端使用lpush从列表左侧插入元素,多个消费者客户端使用brpop命令阻塞式的“抢”列表尾部元素,多个客户端保证了消费的负载均衡和高可用。例如订单的处理。
文章列表:例如csdn常见的文章列表,每个用户都有自己文章。假设有一个业务需要分页展示文章列表。此时可以考虑使用列表,因为列表有序,同时又支持按照索引范围获取元素。
例如:
首先是hash存储一篇文章:hmset artcle:1 title xx timestamp 1476536196 content xxx
然后为用户添加文章:lpush user:1:articles article:1 article:2
最后:articles = lrange user:1:articles 0 9
for article inarticles:
hgetall(article)
但是,列表保存也不是完全没问题,分页获取,hgetall操作会较多;列表太大的话,lrange获取中间范围的性能就会差,这是数据结构导致的。
常用命令
(1)lpush——在key对应的list的头部添加一个元素。
(2)lrange——获取key对应的list的指定下标范围的元素,-1表示获取所有元素。
(3)lpop——从key对应的list的尾部删除一个元素,并返回该元素
从上面的操作可以看出,lpush、lpop从表头操作。
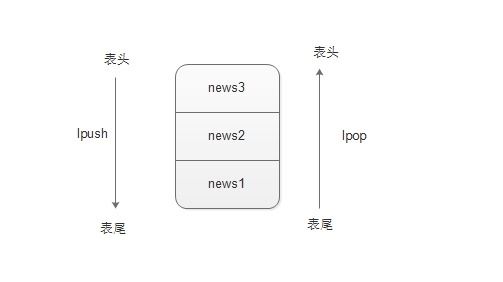
(4)rpush——在key对应的list的尾部添加一个元素。
(5)rpop——从key对应的list的尾部删除一个元素,并返回该元素。
从上面的操作可以看出,rpush、rpop从表尾操作。
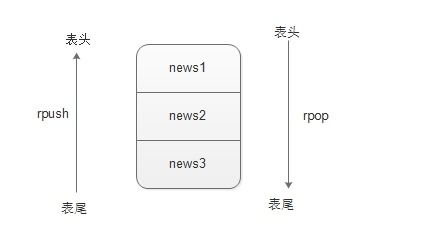
(6)其他命令
| 命令 |
说明 |
| linsert |
在key对应的list的特定元素的前或后插入元素 |
| lset |
设置key对应的list中指定下标元素的值 |
| lrem |
从key对应的list中删除n个和value相同的元素 |
| ltrim |
保留key对应的list中指定范围的元素 |
| rpoplpush |
从第一个list的尾部移除一个元素并添加到第二个list的头部 |
| llen |
返回key对应的list的长度 |
| lindex |
返回key对应的list中index的元素 |
有这么一个口诀:
lpush + lpop = stack(栈)
lpush + rpop = queue(队列)
lpush + ltrim = capped collection(有限集合)
lpush + brpop = Message Queue(消息队列)
Set类型
Redis 集合(Set类型)是一个无序的String类型数据的集合,类似List的一个列表,与List不同的是Set不能有重复的数据。实际上,Set的内部是用HashMap实现的,Set只用了HashMap的key列来存储对象。
首先可见创建一个HashSet的时候实际上创建了一个HashMap;Set中的元素,只是存放在了底层HashMap的key上,底层HashMap的value列为空,遍历HashSet的时候从HashMap中取出keySet来遍历。
Set底层结构示意图
应用场景
集合有取交集、并集、差集等操作,因此可以求共同好友、共同兴趣、分类标签等。
举例一个场景,tag标签。例如一个用户可能对娱乐,体育感兴趣,另一个用户对历史、新闻比较感兴趣。这些兴趣点就是标签。有了这些数据就可以协同过滤共同爱好,兴趣。
sadd user:1 tags tag1 tag2 tag3
sadd user:12tags tag1 tag2 tag5
常用命令
(1)sadd——在key对应的set中添加一个元素。
(2)smembers——获取key对应的set的所有元素。
(3)spop——随机返回并删除key对应的set中的一个元素。
(4)sdiff——求给定key对应的set与第一个key对应的set的差集
(5)suion——求给定key对应的set并集
(6)sinter——求给定key对应的set交集
(7)其他命令
| 命令 |
说明 |
| srem |
删除key对应的set中的一个元素 |
| sdiffstore |
求给定key对应的set与第一个key对应的set的差集,并存储到另一个key对应的set中 |
| sinterstore |
求给定key对应的set交集,并存储到另一个key对应的set中 |
| suionstore |
求给定key对应的set并集,并存储到另一个key对应的set中 |
| somve |
从第一个key对应的set中删除指定元素并添加到第二个key对应的set中 |
| scard |
返回key对应的set的元素个数 |
| sismember |
测试某个元素是否为key对应的set中的元素个数 |
| srandmember |
随机返回key对应的set中的一个元素,但不删除元素 |
SortSet
SortSet顾名思义,是一个排好序的Set,它在Set的基础上增加了一个顺序属性score,这个属性在添加修改元素时可以指定,每次指定后,SortSet会自动重新按新的值排序。
sorted set的内部使用HashMap和跳跃表(SkipList)来保证数据的存储和有序,HashMap里放的是成员到score的映射,而跳跃表里存放的是所有的成员,排序依据是HashMap里存的score。
应用场景
如按时间排序的时间轴。
sortset支持很多的排序,统计命令,因此做排行榜系统,按照时间维度,播放量,点赞数这类业务非常适用。
添加用户点赞数:zadd user:ranking:20180311 3 mike
点赞数增加:incrby user:ranking:20180311 1 mike
常用命令
(1)zadd ——在key对应的zset中添加一个元素
(2)zrange——获取key对应的zset中指定范围的元素,-1表示获取所有元素
(3)zrem——删除key对应的zset中的一个元素
(4)其它命令
| 命令 |
说明 |
| zincrby |
如果key对应的zset中已经存在元素member,则对member的score属性加指定的值 |
| zrank |
返回key对应的zset中指定member的排名。其中member按score值递增(从小到大);排名以0为底,也就是说,score值最小的成员排名为0 |
| zrevrank |
获得成员按score值递减(从大到小)排列的排名 |
| zrevrange |
返回有序集key中,指定区间内的成员。其中成员的位置按score值递减(从大到小)来排列 |
| zrangebyscore |
返回有序集key中,指定分数范围的元素列表 |
| zcount |
返回有序集key中,score值在min和max之间(默认包括score值等于min或max)的成员 |
| zcard |
返回key的有序集元素个数 |