梯度优化 SGD, BGD,MBD,Adagrad,Adadelta,Momentum,NAG,牛顿法
在腾讯的笔试题中,作者遇到了这样一道题:
下面哪种方法对超参数不敏感:
1、SGD2、BGD
3、Adadelta
4、Momentum
神经网络经典五大超参数:
学习率(Learning Rate)、权值初始化(Weight Initialization)、网络层数(Layers)
单层神经元数(Units)、正则惩罚项(Regularizer|Normalization)
显然在这里超参数指的是事先指定的learningrate,而对超参数不敏感的梯度算法是Adadelta,牛顿法。
现在开始具体讨论一下几种常见的梯度优化算法。
是指每一次反向传播中都将全部的样本进行处理计算梯度,更新权重。缺点是这样的方法造成处理数据量大,收敛慢;另外在数据量很大的时候,内存的要求很高。
我们假设损失函数J(θ)的计算方法是最小二乘法,变量为θ(θ即在机器学习训练中的权值w,通过不断对其的更新修改使得最后求得的损失极小),在样本为xi时,目标值为yi,经过计算求得的目标值为hθ(xi),则J(θ)的表达式可以写为:

为了得到J(θ)的最小值,对其求以θ为变量的偏导:
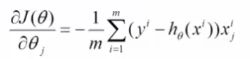
该值即为梯度值,已知梯度,θ值即可以更新为:
![]()
这里的γ值则表示向梯度下降的方向前进多少,即学习速率。
可以看出,每次求解梯度值对θ进行更新时,都需要对每个样本进行计算,这样的计算量大,计算速度也很慢。
故梯度下降算法可以简单表示:
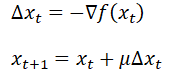
是指采用随机采用的方法,每次使用一个样本数据进行计算梯度。优点是,开始收敛速度快;缺点是一个样本往往不会一直向着整体样本的梯度方向,这样算法后期会有变慢。
随机梯度下降法可以解决批量梯度下降法的计算量过大的问题,每次求梯度只随机取一个样本进行计算。
仍旧假设使用最小二乘法来求损失函数,那么有:
![]()
继续对θ求偏导来求梯度值:

根据梯度值更新θ的值:
![]()
这样采用一个样本的梯度来作为整体梯度值的方法虽然速度比较快,但是一个样本的梯度不一定会和整体的收敛方向一致,会有误差的发生。
为了解决这个问题,可以每次采用少量的样本(如10个)来进行梯度求解,这样迭代速度既快,又不至于梯度与整体的收敛方向差别太大,这样的方法叫做小批量梯度下降法。

3、Adadelta自适应学习率调整:
在介绍Adadelta之前需要先了解Adagrad,
Adadelta的特点是在下降初期,梯度比较小,这时学习率会比较大,而到了中后期,接近最低点时,梯度较大,这时学习率也会相对减小,放慢速度,以便可以迭代到最低点。
假设梯度为gt,那么在使用Adagrad时并非直接减去gt*γ,而是先对学习率进行一个处理:

即把所有的梯度的平方根,作为一个正则化约束项,加上ε的作用是为了避免分母为0。
缺点:
由公式可以看出,仍依赖于人工设置一个全局学习率
设置过大的话,会使regularizer过于敏感,对梯度的调节太大
中后期,分母上梯度平方的累加将会越来越大,使,使得训练提前结束
Adadelta是对Adagrad的扩展,最初方案依然是对学习率进行自适应约束,但是进行了计算上的简化。Adagrad会累加之前所有的梯度平方,而Adadelta只累加固定大小的项,并且也不直接存储这些项,仅仅是近似计算对应的平均值。即:
在此处Adadelta其实还是依赖于全局学习率的,但是做了一定处理后,经过近似牛顿迭代法之后:
其中,代表求期望。
此时,可以看出Adadelta已经不用依赖于全局学习率了。
特点:
训练初中期,加速效果不错,很快
训练后期,反复在局部最小值附近抖动
4、Momentum冲量法:
梯度下降法在求解时的难题主要在于解决极小值和鞍点的问题,为了解决这个问题,可以模拟在现实中的惯性。物体有一个初始动量,在平缓的区域或者小的坑里也能继续向前运动试图滚出小坑,在动量变为0的时候停止,表示已经达到最低点。
简单表示冲量法对梯度的作用,设初始点为![]() ,以及初始的动量为
,以及初始的动量为![]() :
:

在简单的梯度下降算法的基础上,代表上一时刻的动量的项v被加入进来,并且每一次都会乘上一个衰减系数![]() ,该系数可以类比于物理运动中摩擦的存在,前一次的迭代位置方向可以影响到下一次迭代。直到动量小于某个值,或者梯度小于一个值,或者迭代到了一定的次数。
,该系数可以类比于物理运动中摩擦的存在,前一次的迭代位置方向可以影响到下一次迭代。直到动量小于某个值,或者梯度小于一个值,或者迭代到了一定的次数。
5、NGA算法:
NGA算法是一个对冲量算法的改进算法,其求梯度并非求解当前位置的梯度,而是应该 求解下一个时刻的梯度:

相当于一般的冲量算法是根据当前的梯度决定运动方向。而NGA算法则相当于看一下前方的梯度,再决定运动方向。
6、牛顿法:
之前有写过牛顿法,但是在这里再简单总结一下,以方便和其他几种方法作比较。
在介绍牛顿法之前,先介绍一点用于数值计算的牛顿-拉普森算法(NR):
NR算法是用来寻找实值方程的近似解的一种数值算法,已知初始点为![]() ,方程f(x),简单表示为:
,方程f(x),简单表示为:

也就是说,牛顿法其实就是给函数在当前位置做一个一阶展开,即每次迭代的x的变化量都为当前位置的斜率。


牛顿法:
对于凸函数(下图左),凸函数的导数曲线如下(右),找到其极值的位置就相当于找到其![]() 的所在位置,此时凸函数的斜率为0,已经达到极小值。
的所在位置,此时凸函数的斜率为0,已经达到极小值。


这时将牛顿-拉普森算法套用到![]() 上即可。故可以将牛顿法简单表示为:
上即可。故可以将牛顿法简单表示为:
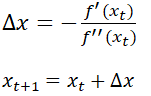
这种方法是求解一维的极值,扩展到高维的情况下的算法如下:

其中![]() 为二阶偏导矩阵,又称海森矩阵
为二阶偏导矩阵,又称海森矩阵
Hf(x)= 