大数据数据仓库——hive学习权威指南
友情提示:更多有关大数据、人工智能方面技术文章请关注博主个人微信公众号:高级大数据架构师!
学习hive权威指南
目录:
- ETL介绍
- 大数据平台架构概述
- 系统数据流动
- hive概述
- hive在hadoop生态系统中
- hive体系结构
- hive安装及使用
- hive客户端的基本语句
- hive在HDFS文件系统中的结构
- 修改hive元数据储存的数据库
- hive操作命令
- hive常用配置
- hive常用的Linux命令选项
- hive三种表的创建方式
- hive外部表
- hive临时表
- hive分区表
- hive桶表
- hive分析函数
- hive数据的导入和导出
- hive常见的hql语句
- hive和MapReduce的相关运行参数
- hive自定义UDF函数
- hiveserver2与jdbc客户端
- hive运行模式与虚拟列
- 【案列一】日志数据文件分析
- 【案列二】hive shell 自动化加载数据
- hive优化
- hadoop & hive压缩
- hive存储格式
- hive总结&应用场景
一、ETL介绍:
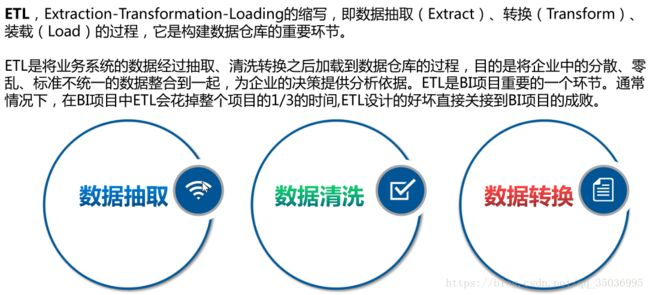
数据抽取:把不同的数据源数据抓取过来,存到某个地方
数据清洗:过滤那些不符合要求的数据或者修正数据之后再进行抽取
不完整的数据:比如数据里一些应该有的信息缺失,需要补全后再写入数据仓库
错误的数据:比如字符串数据后面有一个回车操作、日期格式不正确、日期越界等,需要修正之后再抽取
重复的数据:重复数据记录的所有字段,需要去重
数据转换:不一致的数据转换,比如同一个供应商在结算系统的编码是XX0001,而在CRM中编码是YY0001,统一编码 实现有多种方法:
1、借助ETL工具(如Oracle的OWB、SQL Server的DTS、SQL Server的SSIS服务、Informatic等等)实现
OWB:Oracle Warehouse Builder
DTS:Data Transformation Service
SSIS:SQL Server Integration Services
2、SQL方式实现
3、ETL工具和SQL相结合-----》间接引出hive
借助工具可以快速的建立起ETL工程,屏蔽了复杂的编码任务,提高了速度,降低了难度,但是缺少灵活性。
SQL的方法优点是灵活,提高ETL运行效率,但是编码复杂,对技术要求比较高。
第三种是综合了前面二种的优点,会极大地提高ETL的开发速度和效率
二、大数据平台架构概述:

数据抽取:Canal/Sqoop(主要解决数据库数据接入问题)、还有大量的数据采用Flume解决方案
数据存储:HDFS(文件存储)、HBase(KV存储)、Kafka(消息缓存)
调度:采用了Yarn的统一调度以及Kubernetes的基于容器的管理和调度的技术
计算分析:MR、HIVE、Storm、Spark、Kylin以及深度学习平台比如Caffe、Tensorflow等等
应用平台:交互分析sql,多维分析:时间、地域等等,
可视化:数据分析tableau,阿里datav、hcharts、echarts
数据应用就是指数据的业务
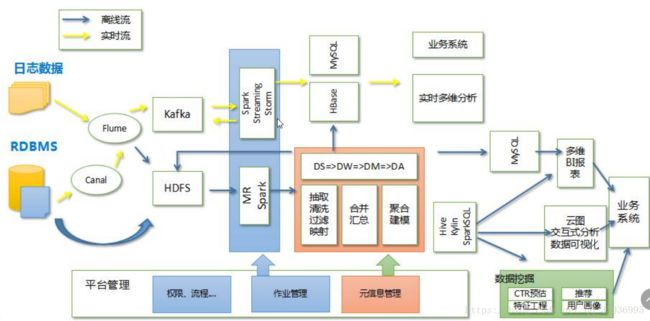
三、系统数据流动:
四、hive概述:

由Facebook开源用于解决海量结构化日志的数据统计,后称为Apache Hive为一个开源项目
结构化数据:数据类型,字段,value---》hive
非结构化数据:比如文本、图片、音频、视频---》会有非关系型数据库存储,或者转换为结构化
结构化日志数据:服务器生成的日志数据,会以空格或者指表符分割的数据,比如:apache、nginx等等

Hive 是一个基于 Hadoop 文件系统之上的数据仓库架构,存储用hdfs,计算用mapreduce
Hive 可以理解为一个工具,不存在主从架构,不需要安装在每台服务器上,只需要安装几台就行了
hive还支持类sql语言,它可以将结构化的数据文件映射为一张数据库表,并提供简单的SQL查询功能
hive有个默认数据库:derby,默认存储元数据---》后期转换成关系型数据库存储mysql
hive的版本:apache-hive-1.2.1 、hive-0.13.1-cdh5.3.6
https://github.com/apache/ 主要查看版本的依赖
下载地址:
apache的:http://archive.apache.org/dist/hive/
cdh的:http://archive.cloudera.com/cdh5/cdh/5/
sql on hadoop的框架:
hive--》披着sql外衣的map-reduce
impala--》查询引擎,适用于交互式的实时处理场景
presto--》分布式的sql查询引擎,适用于实时的数据分析
spark sql
等等。。。。
详细了解sql on hadoop请访问博主的博客:
https://blog.csdn.net/qq_35036995/article/details/80297129
五、Hive在Hadoop生态体系中

六、hive体系结构:
hive架构图

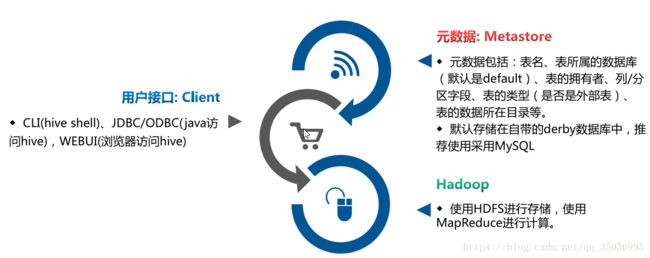
client:
命令行 -常用
JDBC
metastore元数据:存储在数据库
默认的数据库derby 后期开发改成mysql
元数据:表名,表的所属的数据库,表的拥有者,表的分区信息,表的类型,表数据的存储的位置
cli-》metastore
TBLS-》DBS-》hdfs的路径
Hadoop:
使用mapreduce的计算模型
使用hdfs进行存储hive表数据

Driver:
解析器:解析的HQL语句
编译器:把HQL翻译成mapreduce代码
优化器:优化
执行器:把代码提交给yarn

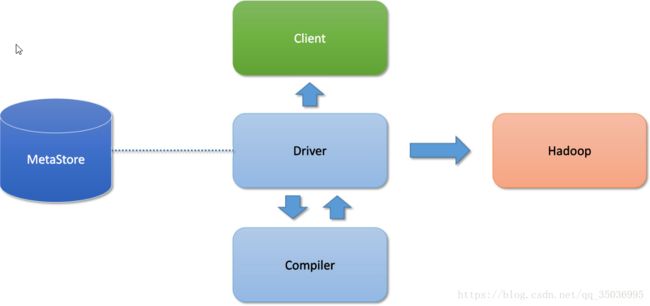
hive通过client提交的job,Driver经过解析、编译、优化、执行-》最后提交给hadoop的MapReduce处理
七、Hive安装及使用
请访问:https://blog.csdn.net/qq_35036995/article/details/80249944
八、Hive客户端的基础语句:
1、进入到hive的客户端:bin/hive;
2、查看数据库:show databases;
3、创建数据库:create database test;
4、进入到数据库:use test;
5、查看表:show tables;
6、数据类型:
tinyint、smallint、int、bigint -》int
float、double、date
string、vachar、char -》string
7、create table hive_table(
id int,
name string
);
8、加载数据:
load data local inpath '/opt/datas/hive_test.txt' into table hive_table;
local:指定本地的数据文件存放路径
不加local:指定数据在hdfs的路径
9、查询语句:
select * from hive_table;
10、hive的默认数据分隔符是\001,也就是^A ,分割符 " ", "," ,"\t"等等
如果说数据的分隔符与表的数据分隔符不一致的话,读取数据为null
按下crtl+v然后再按下crtl+a就会出来^A(\001)
create table row_table(
id int,
name string
)ROW FORMAT DELIMITED FIELDS TERMINATED BY " ";
load data local inpath '/opt/datas/hive_test.txt' into table row_table;
九、hive在hdfs上的文件结构
数据仓库的位置 数据库目录 表目录 表的数据文件
/user/hive/warehouse /test.db /row_table /hive_test.txt
default默认的数据库:指的就是这个/user/hive/warehouse路径
十、修改元数据存储的数据库:
1、用bin/hive同时打开多个客户端会报错
java.sql.SQLException: Another instance of Derby may have already booted the database /opt/modules/apache/hive-1.2.1/metastore_db.
derby数据库默认只能开启一个客户端,这是一个缺陷,换个数据库存储元数据
数据库可选有这几种:derby mssql mysql oracle postgres
一般选择mysql元数据存储
MySQL安装请访问:https://blog.csdn.net/qq_35036995/article/details/80297000
hive与mysql集成请访问:https://blog.csdn.net/qq_35036995/article/details/80297070
十一、Hive操作命令



1、描述表信息
desc tablename;
desc extended 表名;
desc formatted 表名;
2、修改表名
alter table table_oldname rename to new_table_name;
3、给表增加一个列
alter table new_table add columns(age int);
alter table new_table add columns(sex string comment 'sex');添加注释
4、修改列的名字以及类型
create table test_change(a int,b int,c int);
修改列名 a -> a1
alter table test_change change a a1 int;
a1改a2,数据类型改成String,并且放在b的后面;
alter table test_change change a1 a2 string after b int;
将c改成c1,并放在第一列
alter table test_change change c c1 int first;
5、替换列(不能删除列,但是可以修改和替换,)是全表替换
ALTER TABLE table_name ADD|REPLACE COLUMNS (col_name data_type [COMMENT col_comment], ...)
alter table test_change replace columns(foo int , too string);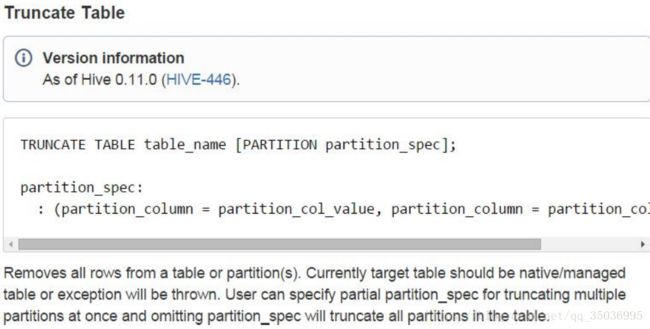
6、清除表数据truncate
只清除表数据,元数据信息还是存在的,表的结构已经表还是在的
truncate table row_table;
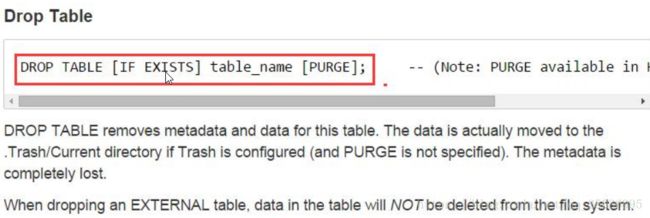
7、删除表数据drop
drop table row_table;
清除数据,表以及表的结构清除,元数据也清除
8、删除数据库
drop database test_db CASCADE;
删除数据库的信息,如果数据库不为空的话,则要加CASCADE字段
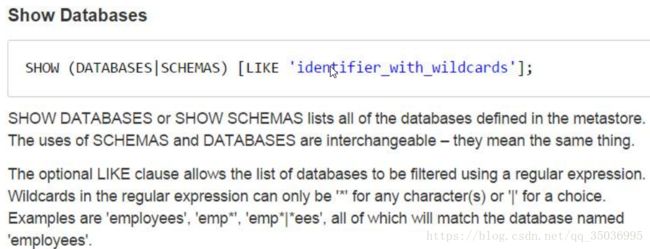
9、查看hive自带的函数: show functions;
desc function when;
desc function extended when; ->查看详细的用法
十二、hive的常用配置

1、hive的日志文件log4j:默认是在${java.io.tmpdir}/${user.name}也就是/tmp/hadoop/hive.log
修改 hive-log4j.properties.template 修改为hive-log4j.properties
修改 hive.log.dir=/opt/modules/apache/hive-1.2.1/logs
2、显示数据库和列名,添加配置信息到hive-site.xml
如下图:
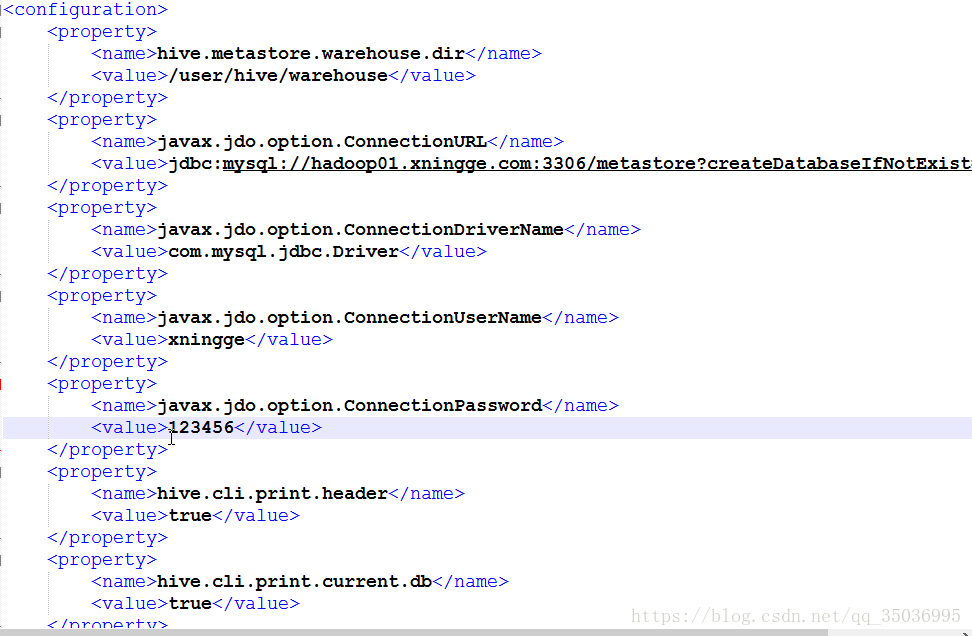
十三、hive常用的linux命令选项
查看帮助信息 bin/hive -help
1、--database指定登陆到哪个database 下面去
bin/hive --database mydb;
2、指定一条sql语句,必须用引号包裹
bin/hive -e 'show databses'
bin/hive -e 'select * from mydb.new_table'
3、指定写sql语句的文件,执行sql
bin/hive -f hivesql
指定一些较为的sql语句,周期性的执行
4、查看sql语句文件
bin/hive -i hivesql
执行文件的sql语句并进入到hive的客户端
用来初始化一些操作
5、bin/hive -S hivesql
静默模式
6、在当前回话窗口修改参数的属性,临时生效
bin/hive --hiveconf hive.cli.print.header=false;
7、在hive的客户端中使用set修改参数属性(临时生效),以及查看参数的属性
set hive.cli.print.header -》查看参数的属性
set hive.cli.print.header=true; -》修改参数属性
8、常用的shell : ! 和 dfs
-》! 表示访问的linux本地的文件系统 ->! ls /opt/modules/apache/
-》dfs表示访问的是hdfs的文件系统 -> dfs -ls /;
9、CREATE database_name[LOCATION hdfs_path]
create database hive_test LOCATION "/location";
自定义数据库在hdfs上的路径,把指定/location当成默认的数据库,
所以这边数据库的名字不显示
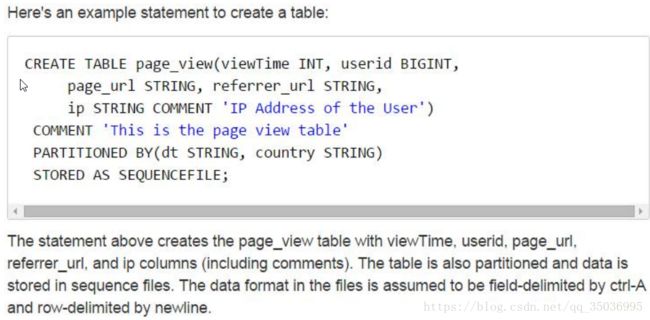
十四、hive三种表的创建方式
1、【普通的创建】
create table stu_info(
num int,
name string
)
row format delimited fields terminated by " ";
加载数据到本地:将本地的数据复制到表对应的位置
load data local inpath '/opt/datas/test.txt' into table stu_info; 注意:'/opt/datas/test.txt' 本地数据目录位置
加载hdfs数据:将hdfs上的数据移动到表对应的位置
load data inpath '/table_stu.txt' into table stu_info; 注意:'/table_stu.txt' 本地数据目录位置

2、【子查询方式: as select】
[AS select_statement];
create table stu_as as select name from stu_info;
将查询的数据和表的结构赋予一张新的表
类似于保存一个中间结果集

3、【like方式】
LIKE existing_table_or_view_name
create table stu_like like stu_info;
复制表的结构赋予一张新的表
接下来创建两张表(为学习其他表建立基本表):

【databases】
create database db_emp;
【员工表】
create table emp(
empno int comment '员工编号',
ename string comment '员工姓名',
job string comment '员工职位',
mgr int comment '领导编号',
hiredate string comment '入职时间',
sal double comment '薪资',
comm double comment '奖金',
deptno int comment '部门编号'
)
row format delimited fields terminated by '\t';
load data local inpath '/opt/datas/emp.txt' into table emp;注意: '/opt/datas/emp.txt'本地数据目录位置
【部门表】
create table dept(
deptno int comment '部门编号',
dname string comment '部门名称',
loc string comment '地址'
)
row format delimited fields terminated by '\t';
load data local inpath '/opt/datas/dept.txt' into table dept;
【覆盖表的数据overwrite】内部机制有删除的操作,删除原来的数据加载表中
load data local inpath '/opt/datas/dept.txt' overwrite into table dept;注意: '/opt/datas/dept.txt' 本地数据目录位置
十五、hive外部表

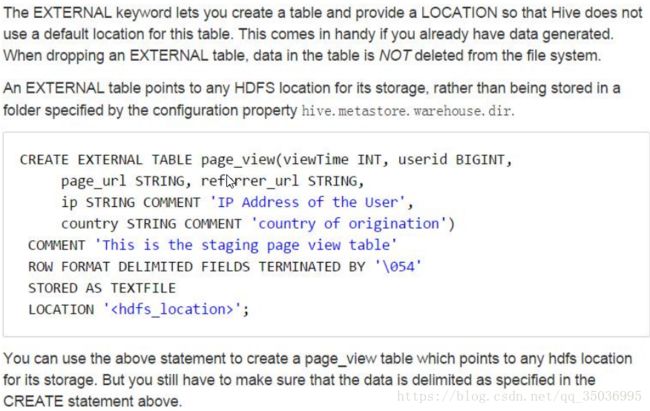
关键词 [EXTERNAL]
[LOCATION hdfs_path]共享数据:去加载hdfs上所属路径下的数据
create table emp_part(
empno int comment '员工编号',
ename string comment '员工姓名',
job string comment '员工职位',
mgr int comment '领导编号',
hiredate string comment '入职时间',
sal double comment '薪资',
comm double comment '奖金',
deptno int comment '部门编号'
)
row format delimited fields terminated by '\t'
LOCATION '/user/hive/warehouse/emp_db.db/emp';
如果你改变emp这张表的数据,那么emp1也会发生改变
如果你改变emp1这张表的数据,那么emp也会发生改变
删除表
drop table emp1;
-》数据共用一份数据,结果就把共享的数据删除了
-》删除表的时候会删除表对应的元数据信息(emp)
-》清除表对应的hdfs上的文件夹
创建外部表
create EXTERNAL table dept_ext(
deptno int comment '部门编号',
dname string comment '部门名称',
loc string comment '地址'
)
row format delimited fields terminated by '\t'
LOCATION '/user/hive/warehouse/db_emp.db/dept';
表的类型Table Type: EXTERNAL_TABLE
删除表:drop table dept_ext;
-》外部表只是删除元数据(dept_ext)
-》不会删除对应的文件夹
-》一般先创建内部表,然后根据需求创建多张外部表
-》外部表主要是数据安全性的作用
hive内部表和外部表的区别:
1)创建表的时候:创建内部表时,会将数据移动到数据仓库指向的路径;若创建外部表,仅记录数据所在的路径,不对数据的位置做任何的改变
2)删除表时:在删除表的时候,内部表的元数据和数据一起删除,而外部表只删除元数据,不删除数据。这样外部表相对于内部表来说更加安全一些,数据组织也更加灵活,方便数据共享
十六、hive临时表
create table dept_tmp(
deptno int,
dname string,
loc string
)
row format delimited fields terminated by '\t';
load data local inpath '/opt/datas/dept.txt' into table dept_tmp;
数据存放路径location:
Location:hdfs://hadoop01.com:8020/tmp/hive/hadoop/23a93177-f22f-4035-a2e3-c51cf315625f/_tmp_space.db/962463c2-6563-47a8-9e62-2a1e8eb6ed19
关闭hive cli:
自动删除临时表
也可以手动删除drop
CREATE TEMPORARY TABLE IF NOT EXISTS dept_tmp(
deptno int ,
dname string ,
loc string
)row format delimited fields terminated by '\t';
LOCATION '/user/hive/warehouse/db_emp.db/dept';
关闭hive cli:
自动删除临时表的数据
也可以手动删除drop,删除临时表的数据及数据文件
十七、hive分区表

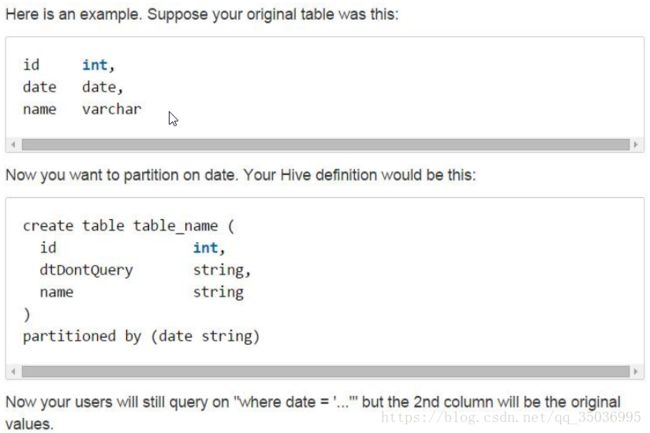

企业中如何使用分区表

[PARTITIONED BY (col_name data_type [COMMENT col_comment], ...)]
普通表:select * from logs where `date`='2018120'
执行流程:对全表的数据进行查询,然后才会进行过滤
分区表:select * from logs where `date`='2018120' and hour='00'
执行流程:直接加载对应文件夹路径下的数据
分区表的字段是逻辑性的,体现在hdfs上形成一个文件夹存在,并不在数据中,
必须不能是数据中包含的字段
【一级分区】
create table emp_part(
empno int ,
ename string ,
job string ,
mgr int ,
hiredate string,
sal double ,
comm double ,
deptno int
)PARTITIONED BY(`date` string)
row format delimited fields terminated by '\t';
load data local inpath '/opt/datas/emp.txt' into table emp_part partition(`date`='2018120');
load data local inpath '/opt/datas/emp.txt' into table emp_part partition(`date`='2018121');
load data local inpath '/opt/datas/emp.txt' into table emp_part partition(`date`='2018122');
select * from emp_part where `date`='2018120';
【二级分区】
create table emp_part2(
empno int ,
ename string ,
job string ,
mgr int ,
hiredate string,
sal double ,
comm double ,
deptno int
)
PARTITIONED BY(`date` string,hour string)
row format delimited fields terminated by '\t';
load data local inpath '/opt/datas/emp.txt' into table emp_part2 partition(`date`='2018120',hour='01');
load data local inpath '/opt/datas/emp.txt' into table emp_part2 partition(`date`='2018120',hour='02');
select * from emp_part2 where `date`='2018120';
select * from emp_part2 where `date`='2018120' and hour='01';
-》分区表的作用主要是提高了查询的效率
十八、hive桶表
桶表:获取更高的处理效率、join、抽样数据
[CLUSTERED BY (col_name, col_name, ...) [SORTED BY (col_name [ASC|DESC], ...)] INTO num_buckets BUCKETS]
create table emp_bu(
empno int ,
ename string ,
job string ,
mgr int ,
hiredate string,
sal double ,
comm double ,
deptno int
)CLUSTERED BY (empno) INTO 4 BUCKETS
row format delimited fields terminated by '\t';
先建表,然后设置
set hive.enforce.bucketing = true;
insert overwrite table emp_bu select * from emp;
十九、hive分析函数
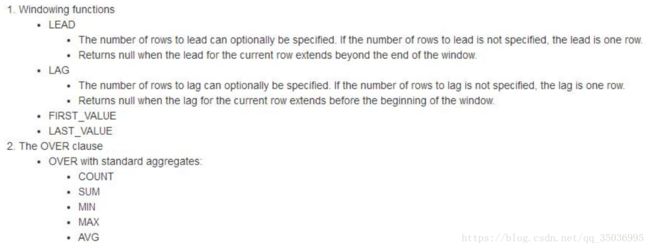
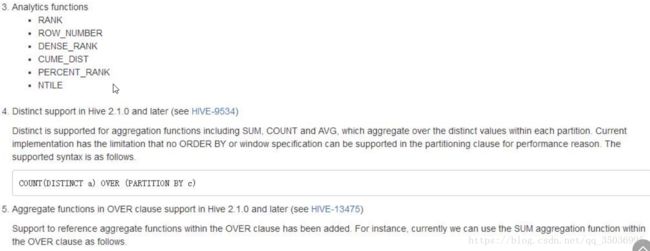
官网:https://cwiki.apache.org/confluence/display/Hive/LanguageManual+WindowingAndAnalytics
分析函数over:分析函数用于计算基于组的某种聚合值,它和聚合函数不同之处是对于每个组返回多行,而聚合函数对于每个组返回一行数据。
主要作用:对于分组后的数据进行处理,然后输出处理后的结果
需求1: 查询部门编号为10的所有员工,按照薪资进行降序排序desc(默认升序)
select * from emp where deptno=10 order by sal desc;
结果:
7839 KING PRESIDENT NULL 1981-11-17 5000.0 NULL 10
7782 CLARK MANAGER 7839 1981-6-9 2450.0 NULL 10
7934 MILLER CLERK 7782 1982-1-23 1300.0 NULL 10
需求2:将每个部门薪资最高的那个人的薪资显示在最后一列
select empno,ename, deptno,sal, max(sal) over(partition by deptno order by sal desc ) as sal_111 from emp;
结果:
7839 KING 10 5000.0 5000.0 1
7782 CLARK 10 2450.0 5000.0 2
7934 MILLER 10 1300.0 5000.0 3
7788 SCOTT 20 3000.0 3000.0
7902 FORD 20 3000.0 3000.0
7566 JONES 20 2975.0 3000.0
7876 ADAMS 20 1100.0 3000.0
7369 SMITH 20 800.0 3000.0
7698 BLAKE 30 2850.0 2850.0
7499 ALLEN 30 1600.0 2850.0
7844 TURNER 30 1500.0 2850.0
7654 MARTIN 30 1250.0 2850.0
7521 WARD 30 1250.0 2850.0
7900 JAMES 30 950.0 2850.0
需求3:将每个部门薪资最高的那个人的薪资显示在最后一列并且显示唯一的编号
select empno,ename, deptno,sal, row_number() over(partition by deptno order by sal desc ) as sal_111 from emp ;
结果:
7839 KING 10 5000.0 1
7782 CLARK 10 2450.0 2
7934 MILLER 10 1300.0 3
7788 SCOTT 20 3000.0 1
7902 FORD 20 3000.0 2
7566 JONES 20 2975.0 3
7876 ADAMS 20 1100.0 4
7369 SMITH 20 800.0 5
7698 BLAKE 30 2850.0 1
7499 ALLEN 30 1600.0 2
7844 TURNER 30 1500.0 3
7654 MARTIN 30 1250.0 4
7521 WARD 30 1250.0 5
7900 JAMES 30 950.0 6
需求4:获取每个部门薪资最高的前两位(嵌套子查询的方式)
select empno,ename, deptno,sal from(select empno,ename, deptno,sal,row_number() over (partition by deptno order by sal desc) as rn from emp) as tmp where rn < 3;
结果:
7839 KING 10 5000.0
7782 CLARK 10 2450.0
7788 SCOTT 20 3000.0
7902 FORD 20 3000.0
7698 BLAKE 30 2850.0
7499 ALLEN 30 1600.0
二十、hive数据导入和导出

【导入】
1、load data [loacl]
-》本地,将数据文件copy到hdfs对应的目录,适合大部分的场景使用
load data local inpath 'loac_path' into table tablename;
-》HDFS,将数据文件move到hdfs对应的目录上,适合大数据集的存储
load data inpath 'hdfs_path' into table tablename;
2、load data + overwrite 【覆盖数据】
load data [local] inpath 'path' overwrite into table tablename;
-》适合重复写入数据的表,一般指的临时表,作为过渡使用
3、子查询 as select
create table tb2(先建表) as select * from tb1;
-》适合数据查询结果的保存
4、insert方式
insert into table tablename select sql; -》追加
insert overwrite table tablename select sql; -》覆盖
测试:create table tb like dept;
insert into table tb select * from dept;
在关系型数据库插入一条数据:insert into table tablename values();
在hive中:insert into table tb values(50,'AA','bb');
注意:这种方式适合数据量非常小的情况下去使用,如果说数据量大,避免这种操作
show tables出现values__tmp__table__1这个临时表,关闭会话就消失
5、location方式

【导出】
1、insert
insert overwrite [local] directory 'path' select sql;
-》本地
insert overwrite local directory '/opt/datas/emp_in01' select * from emp;
insert overwrite local directory '/opt/datas/emp_in01' row format delimited fields terminated by "\t" select * from emp;
-》HDFS
insert overwrite directory '/emp_insert' select * from emp;
insert overwrite directory '/emp_insert' row format delimited fields terminated by "\t" select * from emp;
2、bin/hdfs dfs -get xxx 下载数据文件
hive> dfs -get xxx (hive的客户端)
3、bin/hive -e 或者 -f + >> 或者 > (追加和覆盖符号)
4、sqoop 方式:import导入和export 导出
二十一、hive常见的hql语句



【过滤】
where 、limit、distinct、between and 、null、 is not null
select * from emp where sal >3000;
select * from emp limit 5;
select distinct deptno from emp;
select * from emp where sal between 1000 and 3000;
select empno,ename from emp where comm is null;
select empno,ename from emp where comm is not null;
【聚合函数】
count、sum、max、min、avg、group by 、having
select avg(sal) avg_sal from emp;
按部门分组求出每个部门的平均工资
select 中出现的字段,需要用聚合函数包裹或者放入group by 中
select deptno,avg(sal) from emp group by deptno;
10 2916.6666666666665
20 2175.0
30 1566.6666666666667
select deptno,max(job),avg(sal) from emp group by deptno;
10 PRESIDENT 2916.6666666666665
20 MANAGER 2175.0
30 SALESMAN 1566.6666666666667
select deptno,avg(sal) from emp group by deptno,job;
having和where 是差不多的用法,都是筛选语句
可以一起使用,先执行where后执行having
select deptno,avg(sal) avg_sal from emp group by deptno having avg_sal >2000 ;
【join】
left join, right join,inner join(等值),全join
创建两张表A,B
A表: B表:
ID Name ID phone
1 张三 1 111
2 李四 2 112
3 王五 3 113
5 赵六 4 114
drop table A;
drop table B;
create table A(
id int,
name string
)row format delimited fields terminated by "\t";
create table B(
id int,
name int
)row format delimited fields terminated by "\t";
load data local inpath '/opt/datas/A' into table A;
load data local inpath '/opt/datas/B' into table B;
等值join :id值都会出现
select aaa.ID,aaa.Name ,bbb.ID ,bbb.phone from A aaa join B bbb on aaa.ID=bbb.ID;
左join:以左表为基准,没有匹配到的字段就是null
select aaa.ID,aaa.Name ,bbb.ID ,bbb.phone from A aaa left join B bbb on aaa.ID=bbb.ID;
右join: 以右表为基准,没有匹配到的字段就是null
select aaa.ID,aaa.Name ,bbb.ID ,bbb.phone from A aaa right join B bbb on aaa.ID=bbb.ID;
全join:所有的字段都会出现,匹配或者匹配不上都会出现,没有匹配上的字段就是null
select aaa.ID,aaa.Name ,bbb.ID ,bbb.phone from A aaa full join B bbb on aaa.ID=bbb.ID;
【排序】
1、order by :全局排序,设置多个reduce没有太大的作用
select * from emp order by sal;
2、sort by :局部排序,对于每个reduce的结果进行排序,设置reduce=4,导出到本地
insert overwrite local directory '/opt/datas/emp_sort' row format delimited fields terminated by "\t" select * from emp sort by sal;
3、distribute by(底层是mr分区)
-》可以按照指定的值进行分区
-》先分区后排序,一般和sort by连用
insert overwrite local directory '/opt/datas/emp_dist' row format delimited fields terminated by "\t" select * from emp distribute by deptno sort by sal;
4、cluster by :相当于 distribute by +sort by 组合使用
-》排序只能倒序排序,不能指定排序的规则为desc或者asc;
-》相同的工资放在一起,因为数据的原因,相同工资有点少;
insert overwrite local directory '/opt/datas/emp_cluster' row format delimited fields terminated by "\t" select * from emp cluster by sal;
二十二、hive和mapreduce的运行参数
设置每个reduce处理的数据量:(单位是字节)
set hive.exec.reducers.bytes.per.reducer=
设置最大运行的reduce的个数:默认1009
set hive.exec.reducers.max=
max number of reducers will be used. If the one specified in the configuration parameter mapred.reduce.tasks is
negative, Hive will use this one as the max number of reducers when automatically determine number of reducers.
设置实际运行的reduce的个数,默认是1个
set mapreduce.job.reduces=
二十三、hive自定义UDF函数


UDF :一进一出
转换大小写
用IDEA开发工具写一个简单的UDF函数
hive的maven依赖:
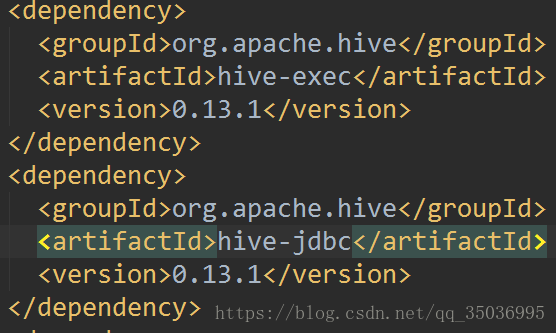
阿里的镜像资源下载:

继承UDF类,实现evaluate(Text str)
public class Lower extends UDF {
public Text evaluate(Text str){
if (str == null) {
return null;
}
if (StringUtils.isBlank(str.toString())) {
return null;
}
return new Text(str.toString().toLowerCase());
}
//测试
public static void main(String[] args) {
// TODO Auto-generated method stub
System.out.println(new Lower().evaluate(new Text("TAYLOR swift")));
}
}
包名.类名
com.xningge.Lower
将写好的代码打成jar包,上传linux
将jar包添加到hive里面去
add jar /opt/datas/lower_hive.jar;
创建一个函数
create temporary function LowerUdf as 'com.xningge.Lower';
查看函数:show functions;
-》使用函数
select empno,ename, LowerUdf(ename) lower_name from emp;
二十四、hiveserver2与jdbc客户端


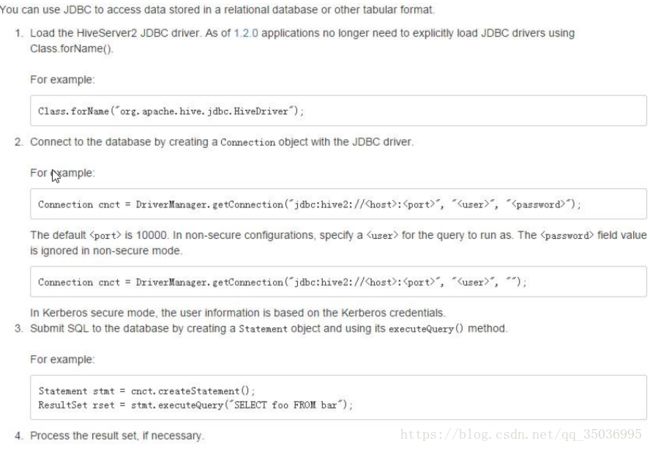
将hive编程一个服务对外开放,通过客户端去连接
启动服务端:bin/hiveserver2
后台启动:bin/hiveserver2 &
开启客户端:bin/beeline
查看客户端帮助信息: bin/beeline --help
beeline> !help (不加分号)
官网:beeline -u jdbc:hive2://hadoop01.xningge.com:10000/ -n scott -w password_file
连接hiveserver2 :
-n 指定用户名:linux上的用户
-p:指定密码: linux用户的密码
bin/beeline -u jdbc:hive2://hadoop01.xningge.com:10000/ -n xningge -p 123456
或者
bin/beeline
!connect jdbc:hive2://hadoop01.xningge.com:10000
hive JDBC 远程连接
官网:https://cwiki.apache.org/confluence/display/Hive/HiveServer2+Clients#HiveServer2Clients-JDBC
二十五、Hive的运行模式与虚拟列
hive的配置模式分为三种:
--依据hive的安装和metastore的设置机器而言
嵌入模式:使用自带的derby数据库
本地模式:将metastore放在mysql上,且mysql与hive安装在同一台机器
远程模式:将metastore放在mysql上,mysql和hive不在同一台机器上
对于远程调控模式,则需要让mysql向集群对外提供服务,则需要配置metastore
配置: 指明存放metastore的mysql所在的机器号
启动服务:bin/hive --service metastore &
fetch模式
Expects one of [none, minimal, more].
Some select queries can be converted to single FETCH task minimizing latency.
Currently the query should be single sourced not having any subquery and should not have
any aggregations or distincts (which incurs RS), lateral views and joins.
0. none : disable hive.fetch.task.conversion
1. minimal : SELECT STAR, FILTER on partition columns, LIMIT only
2. more : SELECT, FILTER, LIMIT only (support TABLESAMPLE and virtual columns)
none: 不管你写什么sql都会跑mapreduce,不开启fetch模式
minimal:当select * 、针对分区字段进行过滤、limit不跑mapreduce
more: 当select 、过滤、limit不跑mapreduce
虚拟列:Virtual Colums
INPUT__FILE__NAME 输入文件名称,显示这行数据所在的绝对路径
BLOCK__OFFSET__INSIDE__FILE 记录数据在块中的偏移量
select *, BLOCK__OFFSET__INSIDE__FILE from dept;
10 ACCOUNTING NEW YORK 0
20 RESEARCH DALLAS 23
30 SALES CHICAGO 42
40 OPERATIONS BOSTON 59
二十五、【案列】日志数据文件分析
需求:统计24小时内的每个时段的pv和uv
pv统计总的浏览量
uv统计guid去重后的总量
获取时间字段,日期和小时-》分区表
数据清洗:获取日期和小时,获取想要字段
2015-08-28 18:14:59 -》28和18 substring方式获取
数据分析
hive :select sql
数据导出:
sqoop:导出mysql
最终结果预期:
日期 小时 pv uv
日期和小时:tracktime
pv:url
uv:guid
1、【数据收集】
登陆hive:
启动服务端:bin/hiveserver2 &
启动客户端:bin/beeline -u jdbc:hive2://hadoop01.xningge.com:10000/ -n xningge -p 123456
创建源表:
create database track_log;
create table yhd_source(
id string,
url string,
referer string,
keyword string,
type string,
guid string,
pageId string,
moduleId string,
linkId string,
attachedInfo string,
sessionId string,
trackerU string,
trackerType string,
ip string,
trackerSrc string,
cookie string,
orderCode string,
trackTime string,
endUserId string,
firstLink string,
sessionViewNo string,
productId string,
curMerchantId string,
provinceId string,
cityId string,
fee string,
edmActivity string,
edmEmail string,
edmJobId string,
ieVersion string,
platform string,
internalKeyword string,
resultSum string,
currentPage string,
linkPosition string,
buttonPosition string
)
row format delimited fields terminated by '\t';
load data local inpath '/opt/datas/2015082818' into table yhd_source;
load data local inpath '/opt/datas/2015082819' into table yhd_source;
2、【数据清洗】
create table yhd_qingxi(
id string,
url string,
guid string,
date string,
hour string
)
row format delimited fields terminated by '\t';
insert into table yhd_qingxi select id,url,guid,substring(trackTime,9,2) date,substring(trackTime,12,2) hour from yhd_source;
select id,url,guid,date,hour from yhd_qingxi;
创建分区表:根据时间字段进行分区
create table yhd_part(
id string,
url string,
guid string
)partitioned by (date string,hour string)
row format delimited fields terminated by '\t';
insert into table yhd_part partition(date='20150828',hour='18')
select id,url,guid from yhd_qingxi where date='28' and hour='18';
insert into table yhd_part partition(date='20150828',hour='19')
select id,url,guid from yhd_qingxi where date='28' and hour='19';
select id,url,guid from yhd_part where date='20150828' and hour='18';
select id,url,guid from yhd_part where date='20150828' and hour='19';
动态分区:
表示是否开启动态分区
表示动态分区最大个数
每个节点上支持动态分区的个数
使用动态分区,需要改变模式为非严格模式
set设置:
set hive.exec.dynamic.partition.mode=nonstrict;
create table yhd_part2(
id string,
url string,
guid string
)partitioned by (date string,hour string)
row format delimited fields terminated by '\t';
固定写死的格式
insert into table yhd_part partition(date='20150828',hour='18')
select id,url,guid from yhd_qingxi where date='28' and hour='18';
动态分区(非常灵活)
insert into table yhd_part2 partition (date,hour) select * from yhd_qingxi;
select id,url,guid from yhd_part2 where date='20150828' and hour='18';
3、数据分析
PV:
select date,hour,count(url) pv from yhd_part group by date,hour;
结果:
+-----------+-------+--------+--+
| date | hour | pv |
+-----------+-------+--------+--+
| 20150828 | 18 | 64972 |
| 20150828 | 19 | 61162 |
+-----------+-------+--------+--+
UV
select date,hour,count(distinct guid) uv from yhd_part group by date,hour;
结果:
+-----------+-------+--------+--+
| date | hour | uv |
+-----------+-------+--------+--+
| 20150828 | 18 | 23938 |
| 20150828 | 19 | 22330 |
+-----------+-------+--------+--+
最终结果导入最终结果表中:
create table result as select date,hour,count(url) pv,count(distinct guid) uv from yhd_part group by date,hour;
结果:
+--------------+--------------+------------+------------+--+
| result.date | result.hour | result.pv | result.uv |
+--------------+--------------+------------+------------+--+
| 20150828 | 18 | 64972 | 23938 |
| 20150828 | 19 | 61162 | 22330 |
+--------------+--------------+------------+------------+--+
4、数据导出:
将最终的结果保存在mysql:
在mysql里创建表:
create table save(
date varchar(30),
hour varchar(30),
pv varchar(30),
uv varchar(30),
primary key(date,hour)
);
sqoop方式:
hive-》mysql
bin/sqoop export \
--connect jdbc:mysql://hadoop01.xningge.com:3306/t_data_pv_uv \
--username xningge \
--password WN@950421 \
--table save \
--export-dir /user/hive/warehouse/track_log.db/result \
-m 1 \
--input-fields-terminated-by '\001'
二十六、【案列二】hive shell脚本 自动化加载数据
效果:
access_log/20180122/
2018012201.log
2018012202.log
2018012203.log
【案例实现】
创建源表
create database load_hive;
create table load_tb(
id string,
url string,
referer string,
keyword string,
type string,
guid string,
pageId string,
moduleId string,
linkId string,
attachedInfo string,
sessionId string,
trackerU string,
trackerType string,
ip string,
trackerSrc string,
cookie string,
orderCode string,
trackTime string,
endUserId string,
firstLink string,
sessionViewNo string,
productId string,
curMerchantId string,
provinceId string,
cityId string,
fee string,
edmActivity string,
edmEmail string,
edmJobId string,
ieVersion string,
platform string,
internalKeyword string,
resultSum string,
currentPage string,
linkPosition string,
buttonPosition string
)partitioned by(date string,hour string)
row format delimited fields terminated by '\t';
启动服务:bin/hiveserver2 &
启动客户端:bin/beeline -u jdbc:hive2://hadoop01.xningge.com:10000 -n xningge -p 123456
1、通过hive -e 的方式:
创建一个脚本:load_to_hive.sh

查看分区:
show partitions load_tb;
在linux下,可以debug运行脚本
sh -x load_to_hive.sh
2、通过hive -f的方式:
1、创建一个文件:vi load.sql存放sql语句
load data local inpath '${hiveconf:log_dir}/${hiveconf:file_path}' into table load_log.load_tab
partition(dateTime='${hiveconf:DAY}',hour='${hiveconf:HOUR}'):
重命名load_to_hive.sh load_to_hive_file.sh
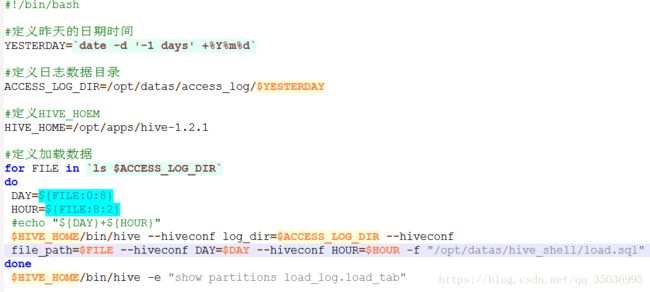
2.创建一个load.sql,把-e后面的复制过来(然后在修改):
针对变量,我们可以用--hiveconf 去传参
load data local inpath '${hiveconf:log_dir}/${hiveconf:file_path}' into table load_hive.load_h partition(date='${hiveconf:DAY}',hour='${hiveconf:HOUR}')
二十七、hive优化
详细优化策略:
hive中sql优化:https://blog.csdn.net/qq_35036995/article/details/80298449
hive整体架构优化:https://blog.csdn.net/qq_35036995/article/details/80298416
hive数据倾斜优化:https://blog.csdn.net/qq_35036995/article/details/80298403
hivejob中map优化:https://blog.csdn.net/qq_35036995/article/details/80298355
1、表拆分成小表
包含临时表、分区表、外部表
2、sql语句:
优化sql:复杂的sql-》子查询+join -》简化,拆分成多个简单的语句
join、filter:先过滤再join
3、设置map和reduce的个数
reduce数目:可以参数进行设置
hive: set mapreduce.job.reduces=
MR:job.setNumReduceTasks(tasks);
**map的数量:
Math.max(minSize, Math.min(maxSize, blockSize))
blocksize:128M
**代码块中
FileInputFormat.setMaxInputSplitSize(job, size);
FileInputFormat.setMinInputSplitSize(job, size);
通过spilt切片的大小来改变map任务数
4、开启并行化执行,默认是false
hive.exec.parallel
5、设置同时运行job的数目,根据集群设置,默认是8
hive.exec.parallel.thread.number
6、jvm重用
mapreduce.job.jvm.numtasks默认是1,运行一个job会启动一个jvm上运行
7、推测执行:
缺点:会消耗更多的资源,一般不建议开启,有可能数据会重复写入,造成异常
8、hive本地模式:
hive的本地模式hive.exec.mode.local.auto默认是false
hive底层运行的hadoop集群中的资源,yarn调度,本地模式不会再集群所有机器上运行,会选一台作为本地运行,一般处理小数据量级的数据速度回很快
限制:job输入的数据不能大于128M,map的个数不能超过4个,默认reduce数目 1个
测试:
create table result4 as
select
date date,
sum(pv) PV,
count(distinct guid) UV,
count(distinct case when length(user_id)!=0 then guid else null end) login_user,
count(distinct case when length(user_id)=0 then guid else null end) visitor,
avg(stay_time) avg_time,
(count(case when pv>=2 then session_id else null end)/count(session_id)) session_jump,
count(distinct ip) IP
from session_info
where date='2015082818'
group by date;
9、数据倾斜
在MR程序中由于某个key值分布不均,导致某个reduce运行速度异常缓慢,严重影响了整个job的运行
【根据产生原因进行解析:】
考虑分区阶段-》默认的分区采用hash值,可以自定义实现分区规避产生倾斜
或者直接在key中加入随机数,相同的key呢会分到一个reduce处理,不同的key分到不同的reduce进行处理,加上随机值打乱分区
在hive中
产生倾斜的主要语句:join、group by、distinct
join:连接某个key值时,key值数据量变多
join:
map join、reduce join、SMB join(sort merge bucket)
map join适合小表join大表的场景【读取小表缓存到内存中,在map端完成reduce,减轻reduce聚合压力】
reduce join适合大表join 大表的场景【加上随机数,把倾斜的数据分到不同的reduce上】
SMB join 适合大表join 大表的场景 创建桶表
分区与分区join,减小join的范围
桶join只适合桶与桶之间的join,适合抽样调查
注意:桶表之间的join,两张表的个数要么一致,要么倍数关系
A:10000万 3桶
1
2
3
b:10000万 3桶
1
2
3
4
5
6
在join时,A表就会join B表1和4,也就说B表1 和4桶的数量等于A表的 1桶,以此类推
最终就是减小join的范围,避免数据倾斜的问题
map join
开启map join ,默认是true,符合条件就去执行
执行map join 的条件,默认是10M
is on, and the sum of size for n-1 of the tables/partitions for a n-way join is smaller than this size, the join is directly
converted to a mapjoin(there is no conditional task). The default is 10MB
如何判断是key导致的问题
通过时间判断
如果每个reduce的运行时间都很长,那么可能是redcue数目设置过少造成的
如果大部分的reduce任务在几分钟完成了,而某一个reduce可能30分钟还没完成,可能是倾斜
可能也是某个节点造成的问题
可以考虑使用推测执行,如果推测执行的任务也很慢,就有可能是倾斜的问题
如果推测执行的新任务在短时间内完成,可能就是节点造成的某个任务运行过慢
自定义counter(context.getCounter()方法自定义计数器)
判断统计查看每个任务的信息
输入记录条数
输出的记录条数
二十八、hadoop & hive压缩
MR
流程:inputformat -> map() ->shuffle ->redcue() ->outputforat
可以mr中实现
优化一:combiner
优化二:compress压缩
使用和配置压缩的前提,当前的hadoop环境必须支持压缩
命令:bin/hadoop checknative
cdh版本的native包替换到hadoop/lib/native下
编译:
如果自己编译源码的步骤
https://github.com/snappy下载snappy的压缩文件,让系统有snappy库
snappy-1.1.1.tar.gz
下载依赖包
snappy安装: yum没法成功,必须编译snappy的源码
./configure
make
make install
下载依赖:
sudo yum -y install build-essential autoconf automake libtool cmake zlib1g-dev pkg-config libssl-dev
sudo yum install snappy libsnappy-dev
-》执行编译的命令
mvn clean package -Pnative -Drequire.snappy -DskipTests -Dtar
或者
mvn clean package -Pnative,dist -DskipTests -Dtar
不同压缩格式牵扯到不同的压缩算法
压缩能减少IO的负载(磁盘、网络)
压缩要支持可分割性(Splittability must be taken into account)
压缩后分为多个块,每个map解压自己的文件,不可分割是不是就不能解压自己的了
MR压缩设置:
map
mapreduce.map.output.compress=true
mapreduce.map.output.compress.codec=org.apache.hadoop.io.compress.SnappyCodec
reduce
mapreduce.output.fileoutputformat.compress=true
mapreduce.output.fileoutputformat.compress.codec=org.apache.hadoop.io.compress.SnappyCodec
通过-D制定运行参数,后面参数选项的格式:key=value
bin/yarn jar share/hadoop/mapreduce/hadoop-mapreduce-examples-2.5.0-cdh5.3.6.jar wordcount -Dmapreduce.map.output.compress=true -Dmapreduce.map.output.compress.codec=org.apache.hadoop.io.compress.SnappyCodec -Dmapreduce.output.fileoutputformat.compress=true -Dmapreduce.output.fileoutputformat.compress.codec=org.apache.hadoop.io.compress.SnappyCodec /input/WordCount.txt /ouputhdfs11
hive压缩设置
配置hive
map:
配置map
mapreduce.map.output.compress=true
mapreduce.map.output.compress.codec=org.apache.hadoop.io.compress.SnappyCodec
reduce:
mapreduce.output.fileoutputformat.compress=true
mapreduce.output.fileoutputformat.compress.codec=org.apache.hadoop.io.compress.SnappyCodec
二十九、hive存储格式
file_format:
: SEQUENCEFILE 行存储,hdfs底层的存储格式,存储的二进制文件
| TEXTFILE 行存储(磁盘开销大,数据解析开销也大)
| RCFILE 数据按行分块,每块按照列存储(压缩快)
| ORC 数据按行分块,每块按照列存储(压缩快,是RCfile的改良版)
| PARQUET 行式存储,同时具有很好的压缩性能
| AVRO
| INPUTFORMAT input_format_classname OUTPUTFORMAT output_format_classname 自定义格式
【原文本数据】
create table file_source(
id string,
url string,
referer string,
keyword string,
type string,
guid string,
pageId string,
moduleId string,
linkId string,
attachedInfo string,
sessionId string,
trackerU string,
trackerType string,
ip string,
trackerSrc string,
cookie string,
orderCode string,
trackTime string,
endUserId string,
firstLink string,
sessionViewNo string,
productId string,
curMerchantId string,
provinceId string,
cityId string,
fee string,
edmActivity string,
edmEmail string,
edmJobId string,
ieVersion string,
platform string,
internalKeyword string,
resultSum string,
currentPage string,
linkPosition string,
buttonPosition string
)
row format delimited fields terminated by '\t';
load data local inpath '/opt/datas/2015082818' into table file_source;
【textfile】
create table file_textfile(
id string,
url string,
referer string,
keyword string,
type string,
guid string,
pageId string,
moduleId string,
linkId string,
attachedInfo string,
sessionId string,
trackerU string,
trackerType string,
ip string,
trackerSrc string,
cookie string,
orderCode string,
trackTime string,
endUserId string,
firstLink string,
sessionViewNo string,
productId string,
curMerchantId string,
provinceId string,
cityId string,
fee string,
edmActivity string,
edmEmail string,
edmJobId string,
ieVersion string,
platform string,
internalKeyword string,
resultSum string,
currentPage string,
linkPosition string,
buttonPosition string
)
row format delimited fields terminated by '\t'
stored as textfile;
insert overwrite table file_textfile select * from file_source;
【PARQUET】
create table file_parquet(
id string,
url string,
referer string,
keyword string,
type string,
guid string,
pageId string,
moduleId string,
linkId string,
attachedInfo string,
sessionId string,
trackerU string,
trackerType string,
ip string,
trackerSrc string,
cookie string,
orderCode string,
trackTime string,
endUserId string,
firstLink string,
sessionViewNo string,
productId string,
curMerchantId string,
provinceId string,
cityId string,
fee string,
edmActivity string,
edmEmail string,
edmJobId string,
ieVersion string,
platform string,
internalKeyword string,
resultSum string,
currentPage string,
linkPosition string,
buttonPosition string
)
row format delimited fields terminated by '\t'
stored as PARQUET;
insert overwrite table file_parquet select * from file_source;
【ORC】
create table file_orc(
id string,
url string,
referer string,
keyword string,
type string,
guid string,
pageId string,
moduleId string,
linkId string,
attachedInfo string,
sessionId string,
trackerU string,
trackerType string,
ip string,
trackerSrc string,
cookie string,
orderCode string,
trackTime string,
endUserId string,
firstLink string,
sessionViewNo string,
productId string,
curMerchantId string,
provinceId string,
cityId string,
fee string,
edmActivity string,
edmEmail string,
edmJobId string,
ieVersion string,
platform string,
internalKeyword string,
resultSum string,
currentPage string,
linkPosition string,
buttonPosition string
)
row format delimited fields terminated by '\t'
stored as ORC;
insert overwrite table file_orc select * from file_source;
【结果比较】
原始数据 37.60 MB
textfile 27.48 MB
parquet 16.14 MB
orc 4.40 MB
总结:
textfile 存储空间消耗空间比较大,并且压缩的text,无法分割和合并,查询的效率最低,可以直接存储,加载数据的速度最高
rcfile存储空间最小,查询的效率最高,需要通过text文件转化来加载,加载的速度最低
三十、hive总结&hive使用场景
