目标检测(七)——YOLO
You Only Look Once: Unified, Real-Time Object Detection
arxiv: http://arxiv.org/abs/1506.02640
github: https://github.com/pjreddie/darknet
blog: https://pjreddie.com/publications/yolo/
github: https://github.com/gliese581gg/YOLO_tensorflow
github: https://github.com/xingwangsfu/caffe-yolo
github: https://github.com/tommy-qichang/yolo.torch
github: https://github.com/frischzenger/yolo-windows
YOLO(You Only Look Once: Unified, Real-Time Object Detection),是Joseph Redmon和Ali Farhadi等人于2015年提出的基于单个神经网络的目标检测系统。
早期的目标检测方法通常是通过提取图像的一些 robust 的特征(如 Haar、SIFT、HOG 等),使用 DPM (Deformable Parts Model)模型,用滑动窗口(silding window)的方式来预测具有较高 score 的 bounding box。这种方式非常耗时,而且精度又不怎么高。后来出现了object proposal方法(其中selective search为这类方法的典型代表),相比于sliding window这中穷举的方式,减少了大量的计算,同时在性能上也有很大的提高。利用 selective search的结果,结合卷积神经网络的R-CNN出现后,Object detection 的性能有了一个质的飞越。基于 R-CNN 发展出来的 SPPnet、Fast R-CNN、Faster R-CNN 等方法,证明了 “Proposal + Classification” 的方法在 Objection Detection 上的有效性。
相比于 R-CNN 系列的方法,YOLO提供了另外一种思路,将 Object Detection 的问题转化成一个 Regression 问题。给定输入图像,直接在图像的多个位置上回归出目标的bounding box以及其分类类别。YOLO是一个可以一次性预测多个Box位置和类别的卷积神经网络,能够实现端到端的目标检测和识别,其最大的优势就是速度快。事实上,目标检测的本质就是回归,因此一个实现回归功能的CNN并不需要复杂的设计过程。YOLO没有选择滑动窗口(silding window)或提取proposal的方式训练网络,而是直接选用整图训练模型。这样做的好处在于可以更好的区分目标和背景区域,相比之下,采用proposal训练方式的Fast-R-CNN常常把背景区域误检为特定目标。

算法流程
- 将图像resize到448 * 448作为神经网络的输入 ;
- 运行神经网络,得到一些bounding box坐标、box中包含物体的置信度和class probabilities ;
- 进行非极大值抑制,筛选Boxes。
创新点
- YOLO将目标检测问题转化为回归问题,不需要复杂的流程。在测试阶段,我们只需要对新图像跑一下我们的神经网络,就可以得到预测结果。我们的基准网络可以在 Titan X GPU 不经过批处理下得到 每秒 45帧的处理速度。快速网络可以得到每秒 150 帧。在实时检测系统中, YOLO的效果是最好的。
- YOLO 在做出预测时是推理整个图像的。与滑动窗口和候选区域算法不同, YOLO 在训练和测试时,从整个图像综合考虑,不仅分析物体的 appearance 还分析其 contextual 信息。Fast R-CNN 比较容易将背景误检测为物体,因为它不考虑 contextual 信息。YOLO 把背景误检测为物体的概率不到 Fast R-CNN 的一半。
- YOLO 对物体的泛化能力比较好。当在自然图像上训练,在艺术图像上检测时,YOLO的效果要比 DPM 和 R-CNN 好很多。
YOLO 缺点
- YOLO的物体检测精度低于其他state-of-the-art的物体检测系统。
- YOLO容易产生物体的定位错误。
- YOLO对小物体的检测效果不好(尤其是密集的小物体,因为一个栅格只能预测2个物体)。
YOLO 网络结构


YOLO检测网络包括24个卷积层和2个全连接层。
其中,卷积层用来提取图像特征,全连接层用来预测图像位置和类别概率值。
YOLO网络借鉴了GoogLeNet分类网络结构。不同的是,YOLO未使用inception module,而是使用1x1卷积层(此处1x1卷积层的存在是为了跨通道信息整合)+3x3卷积层简单替代。
具体流程
1. resize
直接将输入图像的大小resize为448 * 448,不管输入图像的原始尺寸,这样就应该注意在进行检测的时候输入不同长宽比的图像检测结果可能不一样,因为resize以后图像产生很大的变形。尽量维持训练数据与检测数据图像的尺寸相似。
2. 划分栅格预测

YOLO将输入图像划分为S*S的栅格,每个栅格负责检测中心落在该栅格中的物体。每一个栅格预测B个bounding boxes,以及这些bounding boxes的confidence scores。 这个 confidence scores反映了模型对于这个栅格的预测:该栅格是否含有物体,以及这个box的坐标预测的有多准。
公式定义如下:
![]()
如果这个栅格中不存在一个 object,则confidence score应该为0;否则的话,confidence score则为 predicted bounding box与 ground truth box之间的 IOU(intersection over union)。

YOLO对每个bounding box有5个predictions:x, y, w, h, and confidence。
坐标x,y代表了预测的bounding box的中心与栅格边界的相对值。
坐标w,h代表了预测的bounding box的width、height相对于整幅图像width,height的比例。
confidence就是预测的bounding box和ground truth box的IOU值。

每一个栅格还要预测C个 conditional class probability(条件类别概率):Pr(Classi|Object)。即在一个栅格包含一个Object的前提下,它属于某个类的概率。
我们只为每个栅格预测一组(C个)类概率,而不考虑框B的数量。
注意:
conditional class probability信息是针对每个网格的。
confidence信息是针对每个bounding box的。
在测试阶段,将每个栅格的conditional class probabilities与每个 bounding box的 confidence相乘,这样既可得到每个bounding box的具体类别的confidence score。这乘积既包含了bounding box中预测的class的 probability信息,也反映了bounding box是否含有Object和bounding box坐标的准确度。
3. 非极大值抑制

损失函数
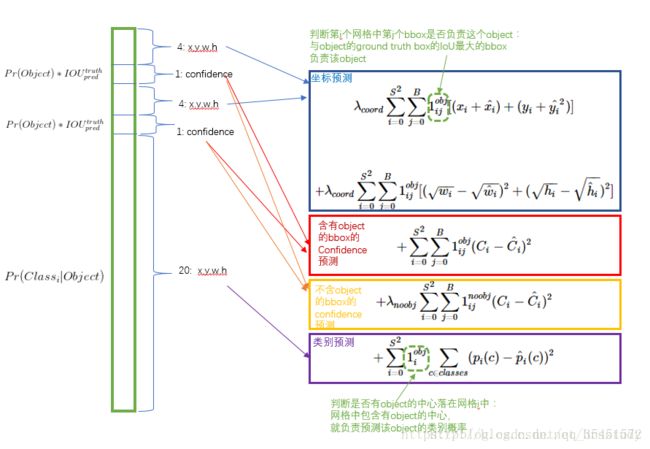
S:栅格的个数;
B:每个栅格预测框的个数;
C:目标类别id;
λcoord = 5;
λnoobj = 0.5。
损失函数的设计目标就是让坐标(x,y,w,h),confidence,classification 这个三个方面达到很好的平衡。
简单的全部采用了sum-squared error loss来做这件事会有以下不足:
a) 8维的localization error和20维的classification error同等重要显然是不合理的。
b) 如果一些栅格中没有object(一幅图中这种栅格很多),那么就会将这些栅格中的bounding box的confidence 置为0,相比于较少的有object的栅格,这些不包含物体的栅格对梯度更新的贡献会远大于包含物体的栅格对梯度更新的贡献,这会导致网络不稳定甚至发散。
解决方案如下:
更重视8维的坐标预测,给这些损失前面赋予更大的loss weight, 记为 λcoord ,在pascal VOC训练中取5。(上图蓝色框) 对没有object的bbox的confidence loss,赋予小的loss weight,记为 λnoobj ,在pascal VOC训练中取0.5。(上图橙色框)
有object的bbox的confidence loss (上图红色框) 和类别的loss (上图紫色框)的loss weight正常取1。、
对不同大小的bbox预测中,相比于大bbox预测偏一点,小box预测偏相同的尺寸对IOU的影响更大。而sum-square error loss中对同样的偏移loss是一样。
为了缓和这个问题,作者用了一个巧妙的办法,就是将box的width和height取平方根代替原本的height和width。 如下图:small bbox的横轴值较小,发生偏移时,反应到y轴上的loss(下图绿色)比big box(下图红色)要大。
在 YOLO中,每个栅格预测多个bounding box,但在网络模型的训练中,希望每一个物体最后由一个bounding box predictor来负责预测。
因此,当前哪一个predictor预测的bounding box与ground truth box的IOU最大,这个 predictor就负责 predict object。
这会使得每个predictor可以专门的负责特定的物体检测。随着训练的进行,每一个 predictor对特定的物体尺寸、长宽比的物体的类别的预测会越来越好。
参考
YOLO - CSDN博客
YOLOv1论文理解 - CSDN博客
深度学习时代的目标检测算法 - 炼数成金订阅号
YOLO - Google 幻灯片