ImageNet Classification with Deep Convolutional Neural Network 论文笔记与复现(AlexNet Colab+Keras TB可视化))
本文用于记录阅读论文ImageNet Classification with Deep Convolutional Neural Networks中总结有价值的点。不需要看论文详解的朋友,可以直接看第二部分的论文复现
文章目录
- 第一部分:论文笔记
- 0 Abstract
- 1 Introduction
- 2 The Dataset
- 3 The Architecture
- 3.1 ReLU Nonlinearity
- 3.2 Training on Multiple GPUs
- 3.3 Local Response Normalization
- 3.4 Overlapping Pooling
- 3.5 Overall Architecture
- 4 Reducing Overfitting
- 4.1 Data Augmentation
- 4.2 Dropout
- 5 Details of learning
- 6 Result
- 第二部分:论文复现(Colab+Keras)
- What is Colab?
- 改变Colab的工作路径
- Keras AlexNet 代码
- 1. import 用到的包,设置超参数
- 2. 数据预处理并设置学习率的变换规律
- 3. 搭建网络
- 4. 生成模型
- 5. 训练模型
- 6.实验结果
第一部分:论文笔记
0 Abstract
摘要部分首先说了作者团队用这个AlexNet参加了一个高像素的图像分类比赛肥肠牛批,这是一个state-of-the-art的惯用吹牛。
然后说这个网络用了6000万个参数和650000个神经元,由5个卷积层最后连上一个1000分类的softmax。
然后提出用non-saturating neurons(这个不懂没关系,这个概念在3.1会讲,大家忍不住的可以先去看3.1) 和 强力GPU来跑。
然后说为了减少全连接层(FC)过拟合用了drop-out。
1 Introduction
主要说了这几件事。
- 提升模型的表现可以收集更大的数据集,采用更强力的模型(我的理解是更深的神经网络),采用更好的技术来防止模型过拟合。
- 对于较小的数据集可以采用“标签-保留转换”这种数据增强的方式。
- 再次强调我们的模型很牛批,在什么什么比赛的排名很高,模型包含了一系列新的非同一般的特征用来提升模型的表现和缩短训练时间在section 3介绍。
- 即使有12万张带标签的训练图,模型的大小仍然让模型存在过拟合的问题,我们采取了几个肥肠有效的方法来防止过将在section 4介绍。
- 我们最终的网络包含5个卷积层,3个全连接层,去掉任何一个卷积层都会导致效果变差。
- 最后受制于GPU的内存,只要GPU变强,我们的模型就会变得更强。
2 The Dataset
ImageNet 是一个超过1500万张带标签的高分辨率图像的数据集,这些图片归属于22,000多个类别。作为 PASCAL 视觉目标挑战赛的一部分,一年一度的 ImageNet 大型视觉识别挑战赛(ILSVRC)从2010年开始举办。ILSVRC 使用 ImageNet 的一个子集,分为1000种类别,每种类别中都有大约1000张图像。总之,大约有120万张训练图像,50,000张验证图像和150,000张测试图像。
ILSVRC-2010是ILSVRC这个系列赛唯一一个给了测试集标签的版本,所以我们大部分实验都在这个版本上进行,在section 6上我们汇报了在该数据集上的结果。在 ImageNet 上,观察两个误差率:top-1 和 top-5 ,top-1就是直接看模型预测出来的和真实标签不同的百分比,其中 top-5 误差率是指测试图像上正确标签不属于被模型认为是最有可能的五个标签的百分比。
ImageNet包含各种分辨率的图像,而我们的系统要求不变的输入维度。因此,我们将图像进行下采样到固定的256×256分辨率。给定一个矩形图像,我们首先缩放图像短边,使其长度减少为256,然后然后从结果图像(resulting image)中裁剪中心的256×256大小的图像块。除了在训练集上对像素减去平均活跃度(mean activity)外,我们不对图像做任何其它的预处理。因此我们在原始的RGB像素值(中心的)上训练我们的网络。
这里有两个我不是很清楚的概念,result image是指处理的张图像,还是指有一张可以对照的图像,mean activity 翻译成平均活跃度,度娘了一下,发现应该有两种均值。
- 一种是image mean,是对R,G,B三个通道都求均值然后各通道再减去这个均值
- 第二种是pixel mean,直接全图减去全部像素的均值
这里应该是取第一种。
3 The Architecture
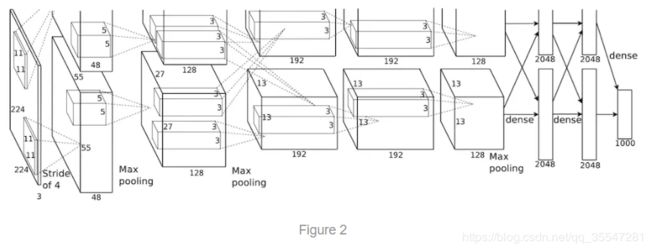
网络的结构长成上面这张图这样,从上面的图我们可以看出有两个卷积的操作,一个在上面,一个在下面,其实想表达的是在实际操作中,一个GPU运行图中上面部分的层,而另一个GPU运行图下面部分的层。两个GPU只在特定的层进行交流。(从图上看,我猜是在FC处共享参数),网络的输入是150,528维(224 * 224 * 3,这里就有点迷,明明图像预处理是弄成 256 * 256 * 3 ,这里怎么就成了224了),网络剩下层的神经元数目分别是253,440 -> 186,624 -> 64,896 -> 64,896 -> 43,264 -> 4096 -> 4096 -> 1000。
3.1 ReLU Nonlinearity
首先把在摘要遗留下来的Non-saturating neurons的问题解释一下:
saturating这个概念来自saturating arithmetic 这个数学计算的专有名词,saturating arithmetic其实是一个算法,这个算法的要求是将输入的值全部变成某个最大值和最小值之间。通俗地讲,就是把一个数x,扔进一个函数f()中,但是这个f(x)要在[a,b]这两个最小最大值中。
- Saturating neurons:就是说这个神经元,要求把input映射到一个特定的区间中,这样的函数有sigmoid():input -> [0,1],tanh():input -> [-1,1]
- Non-saturating neurons:就是说这个神经元,没有把input映射到一个特定的区间中,这样的函数有本文提到的ReLU():input -> max(0,input),leaky ReLU():input -> max(k*input,input)
为什么要使用Non-saturating neurons(ReLU(),leaky ReLU())?
- In terms of training time with gradient descent, these saturating nonlinearities are much slower than the non-saturating nonlinearity f(x) = max(0,x).
- 考虑到梯度下降的训练时间,这些饱和的非线性比非饱和非线性f(x) = max(0,x)更慢。
更详细的解释可以观看视频https://www.bilibili.com/video/av16180690/
下面一张图可以更形象地说明问题
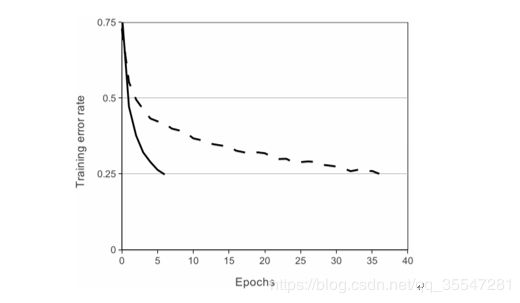
使用ReLU的四层卷积神经网络在CIFAR-10数据集上达到25%的训练误差比使用tanh神经元的等价网络(虚线)快六倍。为了使训练尽可能快,每个网络的学习率是独立选择的。其中没有使用任何正则化。网络结构会直接影响训练的效果,从图中可以看出ReLU的学习速度一致比使用Saturating neurons的快。
这一段还提到一嘴使用非线性函数 f ( x ) = ∣ t a n h ( x ) ∣ f(x) = |tanh(x)| f(x)=∣tanh(x)∣的对比,大致的意思就是这个函数结合归一化以及局部均值池化在Caltech-101数据集上表现很好,在Caltech-101数据集上主要作用是防止过拟合,但是在我们这个原本数据集上,更加注重训练的速度,更快的学习速率对大型模型在大型数据集上的性能有很大的影响。
3.2 Training on Multiple GPUs
这一部分和摘要说的差不多,就是那个图上部分用一个GPU算,下部分用另一个GPU算。
3.3 Local Response Normalization
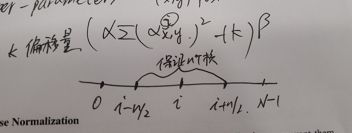
这部分讲的是 局部响应归一化 的这个正则化的方法。首先给出它的公式:
b x , y i = a x , y i / ( k + α ∑ j = max ( 0 , i − n 2 ) min ( N − 1 , i + n 2 ) ( a x , y j ) 2 ) β b_{x, y}^{i}=a_{x, y}^{i} /\left(k+\alpha \sum_{j=\max \left(0, i-\frac{n}{2}\right)}^{\min \left(N-1, i+\frac{n}{2}\right)}\left(a_{x, y}^{j}\right)^{2}\right)^{\beta} bx,yi=ax,yi/(k+α∑j=max(0,i−2n)min(N−1,i+2n)(ax,yj)2)β
( x , y ) (x,y) (x,y)是神经元(kernel)所在的位置
a x , y i a_{x, y}^{i} ax,yi是 ( x , y ) (x,y) (x,y)这个位置下经过第 i i i个神经元运算后的结果。
k k k我称为偏移量
α \alpha α我称为放缩的比列系数
β \beta β同理也是一个影响归一化的超参数
中间 ∑ \sum ∑的部分可以理解成这样:
保证取相邻的n个神经元(核)来做归一化
局部归一化的作用是分别减少了top-1 1.4%,top-5 1.2%的错误率。我们也在CIFAR-10数据集上验证了这个方案的有效性:没有归一化的四层CNN取得了13%的错误率,而使用归一化取得了11%的错误率。
3.4 Overlapping Pooling
通俗地讲,重叠池化和普通池化不同的地方就是,重叠池化的步长比核的长和宽都要小,这样就会导致下一步的池化的像素点和上一步的池化的像素点有重叠,故称为重叠池化。
CNN中的池化层使用相同的映射函数来总结出神经元相邻组的输出,总结的内容可以是均值,最大值等。一般而言,相邻池化单元的区域是不重叠的。更确切的说,池化层可看作由池化单元网格组成,网格间距为s个像素,这里的s就是step,每个网格归纳池化单元中心位置z × z大小的邻居。如果设置s = z,我们会得到通常在CNN中采用的传统局部池化。如果设置s < z,我们会得到重叠池化。这就是我们网络中使用的方法,设置s = 2,z = 3。这个方案与非重叠方案s = 2, z = 2相比,分别降低了top-1 0.4%,top-5 0.3%的错误率,两者的输出维度是相等的。我们在训练过程发现,采用重叠池化的模型更难以过拟合。
3.5 Overall Architecture
这里讲得是网络的结构。这里两个GPU是如何运行的解释得不是太清楚,反复听了b站一位UP主的讲解视频https://www.bilibili.com/video/av16167790?from=search&seid=4604468634457556183,我和大家分享一个我认为最为科学的想法。
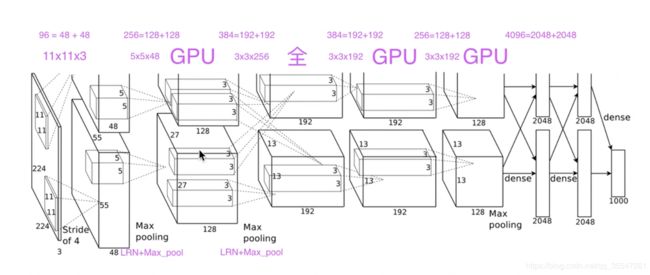
首先输入的是一张2242243(因为是彩色RGB三通道的图)
第一层用的卷积核的大小是11113,卷积核的个数是48+48=96,从这一层开始两个GPU开始分开运行,现在定义处理上半层特征图的叫GPU_A,处理下半层特征图的叫GPU_B,每个GPU负责48个卷积核的运算,上半层GPU_A生成48张特征图,下半层GPU_B生成48张特征图。这一层卷积结束之后,还需要LRN(Local Response Normalization 局部响应归一化)和Max_Pooling(最大池化)
第二层和第一层同理,两个GPU分别处理自己上一层传来的output(那48张特征图),卷积核的大小是5548,然后一共有128+128=256个卷积核,所以两个GPU各自利用自己上一层的output生成128张特征图。这一层的卷积结束之后还需要LRN(Local Response Normalization 局部响应归一化)和Max_Pooling(最大池化)
第三层和前两层不同,这一层两个GPU都要是将两个GPU的上一层的全部输出output作为输入input,所以这一层的卷积核大小是33(128[来自GPU_A]+128[来自GPU_B]),也就是这层的卷积核是33256,而不是像前两层那样只是把自己上一层的输出当成输入,这层一共有192+192=384个卷积核,GPU_A负责前192个卷积核的生成的特征图,GPU_B负责后192个卷积核生成的特征图。
第四层和第五层同第二层。
关键来了,第六层是我想了很久都没有想明白的地方,这里看图是接了一个全连接层(FC),首先将128[来自GPU_A]和128[来自GPU_B]的一共256张特征图拉直成一个超长的向量,连接到一个大小为4096的全连接层中,其中4096个神经元的前2048个神经元由GPU_A运算,后2048个神经元由GPU_B来运算。
第七层和第六层同理。
第八层是再连接到一个大小为1000的全连接层中,用softmax,来算1000种分类的分布。
4 Reducing Overfitting
由于神经网络的结构存在6千万个参数
尽管ILSVRC的1000类使每个训练样本从图像到标签的映射上强加了10比特的约束,但这不足以学习这么多的参数而没有相当大的过拟合。
它使用了两种方式来避免过拟合。
4.1 Data Augmentation
数据增强
第一种数据增强方式包括产生图像平移和水平翻转。我们从256× 256图像上通过随机提取224 × 224的图像块(以及这些图像块的水平翻转)实现了这种方式,然后在这些提取的图像块上进行训练,最终的训练样本是高度相关的。没有这个方案,我们的网络会有大量的过拟合,这会迫使我们使用更小的网络。在测试时,网络会提取5个224 × 224的图像块(四个角上的图像块和中心的图像块)和它们的水平翻转(因此总共10个图像块)进行预测,然后对网络在10个图像块上的softmax层的预测结果进行平均。
第二种数据增强方式包括改变训练图像的RGB通道的强度。具体地,我们在整个ImageNet训练集上对RGB像素值集合(一个pixel有三个值RGB也就是(224 * 224)* 3 这么大的矩阵,224 * 224是行数,3是列数),执行主成分分析(PCA)。对于每幅训练图像,我们这个大矩阵的主成分,大小成正比的对应特征值乘以一个随机变量,随机变量通过均值为0,标准差为0.1的高斯分布得到。因此对于每幅RGB图像像素 I x y = [ I x y R , I x y G , I x y B ] I_{xy}=[I_{xy}^R,I_{xy}^G,I_{xy}^B] Ixy=[IxyR,IxyG,IxyB],我们加上一个特征值和特征向量重组的随机量:
[ p 1 , p 2 , p 3 ] [ α 1 λ 1 , α 2 λ 2 , α 3 λ 3 ] [p_1,p_2,p_3][\alpha_1\lambda_1,\alpha_2\lambda_2,\alpha_3\lambda_3] [p1,p2,p3][α1λ1,α2λ2,α3λ3]
我们知道 [ p 1 , p 2 , p 3 ] [ λ 1 , λ 2 , λ 3 ] [p_1,p_2,p_3][\lambda_1,\lambda_2,\lambda_3] [p1,p2,p3][λ1,λ2,λ3]就是取前三个最大特征值和对应特征向量重组该图片。而 α i \alpha_i αi是前面提到的随机变量,服从 N ( 0 , 1 ) N(0,1) N(0,1),这一过程相当于加深或者减少图片最有特征的部分,比如说一张照片,它最大能让人辨认的地方是里面有一个穿红衣服的小女孩,那 [ p 1 , p 2 , p 3 ] [ λ 1 , λ 2 , λ 3 ] [p_1,p_2,p_3][\lambda_1,\lambda_2,\lambda_3] [p1,p2,p3][λ1,λ2,λ3]还原的就是这个穿红衣服的小女孩,然后加深或者减少这个特征的RGB值,使得照片呈现出高光强或者弱光强情况下的图片。这个方案减少了top 1错误率1%以上。
4.2 Dropout
Dropout,它会以0.5的概率对每个隐层神经元的输出设为0。那些用这种方式“丢弃”的神经元不再进行前向传播并且不参与反向传播。因此每次输入时,神经网络会采样一个不同的架构,但所有架构共享权重。这个技术减少了复杂的神经元互适应,因为一个神经元不能依赖特定的其它神经元的存在。因此,神经元被强迫学习更鲁棒的特征,这让它在与许多不同层的神经元的连接时更为有效。在测试时,我们使用所有的神经元但它们的输出乘以0.5,这是对指数级的dropout网络的预测分布的几何平均一种合理的估计。
5 Details of learning
我们使用随机梯度下降来训练我们的模型,样本的batch size为128,动量为0.9,权重衰减率为0.0005。我们发现少量的权重衰减对于模型的学习是重要的。换句话说,权重衰减不仅仅是一个正则项,而且它减少了模型的训练误差。权重 w w w的更新规则是:
v i + 1 : = 0.9 ⋅ v i − 0.0005 ⋅ ϵ ⋅ w i − ϵ ⋅ ⟨ ∂ L ∂ w ∣ w i ⟩ D i v_{i+1} :=0.9 \cdot v_{i}-0.0005 \cdot \epsilon \cdot w_{i}-\epsilon \cdot\left\langle\frac{\partial L}{\partial w} | w_{i}\right\rangle_{D_{i}} vi+1:=0.9⋅vi−0.0005⋅ϵ⋅wi−ϵ⋅⟨∂w∂L∣wi⟩Di
w i + 1 : = w i + v i + 1 w_{i+1} :=w_{i}+v_{i+1} wi+1:=wi+vi+1
i i i是迭代索引, v v v是动量变量, ϵ ϵ ϵ是学习率, ⟨ ∂ L / ∂ w │ w i ⟩ D i ⟨∂L/∂w│ w_i ⟩_{D_i} ⟨∂L/∂w│wi⟩Di是目标函数对 w w w,在 w i w_i wi上的第 i i i批微分 D i D_i Di的平均。
我们使用均值为0,标准差为0.01的高斯分布对每一层的权重进行初始化。我们在第2,4,5卷积层和全连接隐层将神经元偏置初始化为常量1。这个初始化通过为ReLU提供正输入加速了早期阶段的学习。我们对剩下的层的神经元偏置初始化为0。
我们对所有的层使用相等的学习率,这个是在整个训练过程中我们手动调整得到的。当验证误差在当前的学习率下停止改善时,我们遵循启发式的方法将学习率除以10。学习率初始化为0.01,在训练停止之前降低三次。我们在120万图像的训练数据集上训练神经网络大约90个循环,在两个NVIDIA GTX 580 3GB GPU上花费了五到六天。
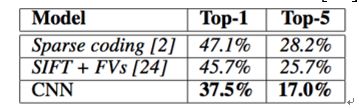
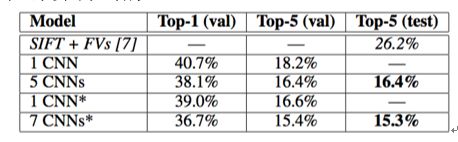
6 Result
第二部分:论文复现(Colab+Keras)
What is Colab?
Colaboratory 是一个 Google 研究项目,旨在帮助传播机器学习培训和研究成果。它是一个 Jupyter 笔记本环境,不需要进行任何设置就可以使用,并且完全在云端运行。Colaboratory 笔记本存储在 Google 云端硬盘中,并且可以共享,就如同您使用 Google 文档或表格一样。Colaboratory 可免费使用。
Colab的使用本人也在摸索当中,因为需要Surf the Internet scientifically,所以不能写在Blog里,想要了解的朋友可以底下评论。
改变Colab的工作路径
首先在你的Google云盘上生产一个文件夹用来存放你的代码
然后在文件夹内新建一个colab的 Jupyter notebook
OK,之后我们打开它,开始我们的代码之旅
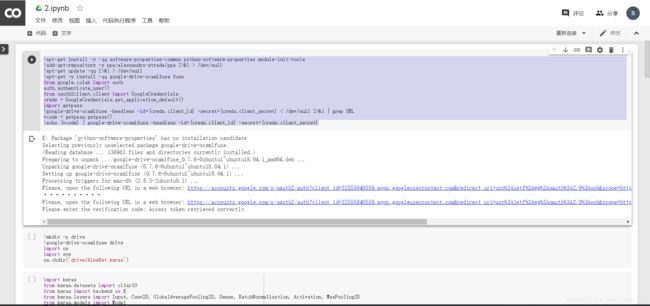
新建一个代码块,输入下面的代码
!apt-get install -y -qq software-properties-common python-software-properties module-init-tools
!add-apt-repository -y ppa:alessandro-strada/ppa 2>&1 > /dev/null
!apt-get update -qq 2>&1 > /dev/null
!apt-get -y install -qq google-drive-ocamlfuse fuse
from google.colab import auth
auth.authenticate_user()
from oauth2client.client import GoogleCredentials
creds = GoogleCredentials.get_application_default()
import getpass
!google-drive-ocamlfuse -headless -id={creds.client_id} -secret={creds.client_secret} < /dev/null 2>&1 | grep URL
vcode = getpass.getpass()
!echo {vcode} | google-drive-ocamlfuse -headless -id={creds.client_id} -secret={creds.client_secret}
两次验证,输入指定的密码,完成验证。
然后新建一个代码块,改变工作路径。
!mkdir -p drive
!google-drive-ocamlfuse drive
import os
import sys
os.chdir('drive/AlexNet keras')
如果你完全严格按照我的步骤os.chdir(‘drive/AlexNet keras’),就和我输一样的代码,如果你的文件名不是起的AlexNet keras,这里改成你自己起的文件名。
Keras AlexNet 代码
1. import 用到的包,设置超参数
import keras
from keras.datasets import cifar10
from keras import backend as K
from keras.layers import Input, Conv2D, GlobalAveragePooling2D, Dense, BatchNormalization, Activation, MaxPooling2D
from keras.models import Model
from keras.layers import concatenate,Dropout,Flatten
from keras import optimizers,regularizers
from keras.preprocessing.image import ImageDataGenerator
from keras.initializers import he_normal
from keras.callbacks import LearningRateScheduler, TensorBoard, ModelCheckpoint
num_classes = 10 #分成多少类
batch_size = 64 # 一个batch用64张图
iterations = 782 #一个epoch用782个batch
epochs = 300 #一共循环300个epoch
DROPOUT=0.5 # 每个神经元以50%的概率失效
CONCAT_AXIS=3
weight_decay=1e-4
DATA_FORMAT='channels_last' # Theano:'channels_first' Tensorflow:'channels_last'
log_filepath = './alexnet' #tensorbroad的文件储存的路径
2. 数据预处理并设置学习率的变换规律
def color_preprocessing(x_train,x_test):
x_train = x_train.astype('float32')
x_test = x_test.astype('float32')
mean = [125.307, 122.95, 113.865]
std = [62.9932, 62.0887, 66.7048]
for i in range(3):
x_train[:,:,:,i] = (x_train[:,:,:,i] - mean[i]) / std[i]
x_test[:,:,:,i] = (x_test[:,:,:,i] - mean[i]) / std[i]
return x_train, x_test
def scheduler(epoch):
if epoch < 100:
return 0.01
if epoch < 200:
return 0.001
return 0.0001
# load data
(x_train, y_train), (x_test, y_test) = cifar10.load_data()
y_train = keras.utils.to_categorical(y_train, num_classes)
y_test = keras.utils.to_categorical(y_test, num_classes)
x_train, x_test = color_preprocessing(x_train, x_test)
3. 搭建网络
按照上面这张图来设置我们的网络
def alexnet(img_input,classes=10):
x = Conv2D(96,(11,11),strides=(4,4),padding='same',
activation='relu',kernel_initializer='uniform')(img_input)# valid
x = MaxPooling2D(pool_size=(3,3),strides=(2,2),padding='same',data_format=DATA_FORMAT)(x)
x = Conv2D(256,(5,5),strides=(1,1),padding='same',
activation='relu',kernel_initializer='uniform')(x)
x = MaxPooling2D(pool_size=(3,3),strides=(2,2),padding='same',data_format=DATA_FORMAT)(x)
x = Conv2D(384,(3,3),strides=(1,1),padding='same',
activation='relu',kernel_initializer='uniform')(x)
x = Conv2D(384,(3,3),strides=(1,1),padding='same',
activation='relu',kernel_initializer='uniform')(x)
x = Conv2D(256,(3,3),strides=(1,1),padding='same',
activation='relu',kernel_initializer='uniform')(x)
x = MaxPooling2D(pool_size=(3,3),strides=(2,2),padding='same',data_format=DATA_FORMAT)(x)
x = Flatten()(x)
x = Dense(4096,activation='relu')(x)
x = Dropout(0.5)(x)
x = Dense(4096,activation='relu')(x)
x = Dropout(0.5)(x)
out = Dense(classes, activation='softmax')(x)
return out
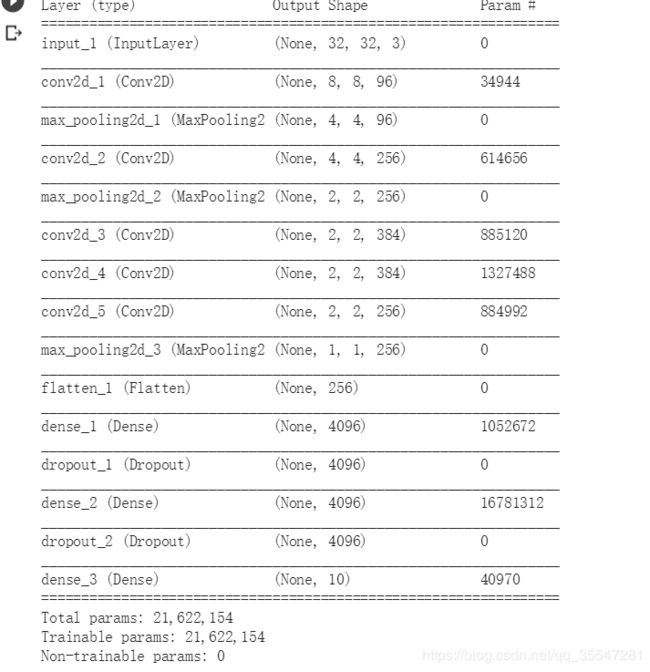
4. 生成模型
img_input=Input(shape=(32,32,3))
output = alexnet(img_input)
model=Model(img_input,output)
model.summary()
再次看下网络结构和参数量
5. 训练模型
梯度下降的方法用了SGD随机梯度下降,并且用了momentum。
数据增强用了注释里的方法
# set optimizer
sgd = optimizers.SGD(lr=.1, momentum=0.9, nesterov=True)
model.compile(loss='categorical_crossentropy', optimizer=sgd, metrics=['accuracy'])
# set callback
tb_cb = TensorBoard(log_dir=log_filepath, histogram_freq=0)
change_lr = LearningRateScheduler(scheduler)
cbks = [change_lr,tb_cb]
# set data augmentation
datagen = ImageDataGenerator(horizontal_flip=True,
width_shift_range=0.125,
height_shift_range=0.125,
fill_mode='constant',cval=0.)
#horizontal_flip=True Randomly flip inputs horizontally. 随机翻转
# width_shift_range=0.125 水平平移,相对总宽度的比例
#height_shift_range=0.125 垂直平移,相对总高度的比例
#fill_mode='constant',cval=0 'constant': kkkkkkkk|abcd|kkkkkkkk (cval=k) 平移完用0来填充
datagen.fit(x_train)
# start training
model.fit_generator(datagen.flow(x_train, y_train,batch_size=batch_size),
steps_per_epoch=iterations,
epochs=epochs,
callbacks=cbks,
validation_data=(x_test, y_test))
model.save('alexnet.h5')
根据我的实战,如果用Colab会出现以下这种情况
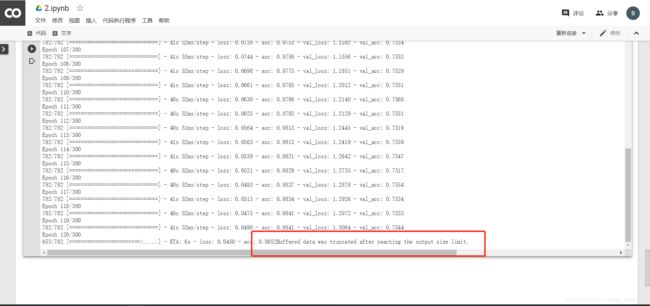
先给出结论,这个报错并不会影响实验的结果,它只是不能在这个页面上显示接下来轮次的loss,acc,val_loss,val_acc,如果想避免这个报错
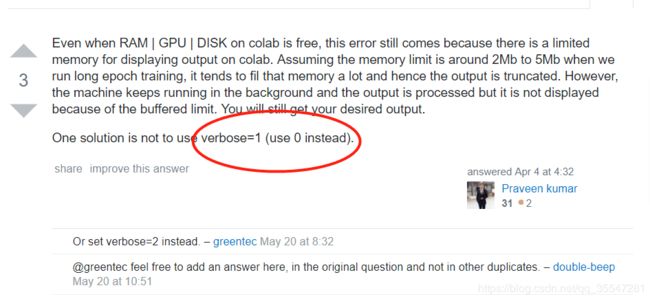
这个verbose,是model.fit_generator()中的参数,加上应该就可以了,但是我没实操过,大家可以试试。
![]()
6.实验结果
经过漫长的训练后,我们怎么康康我们模型的准确率呢,我们可以使用TensorBoard来看,打开我们的alexnet文件夹

下载里面对应的文件
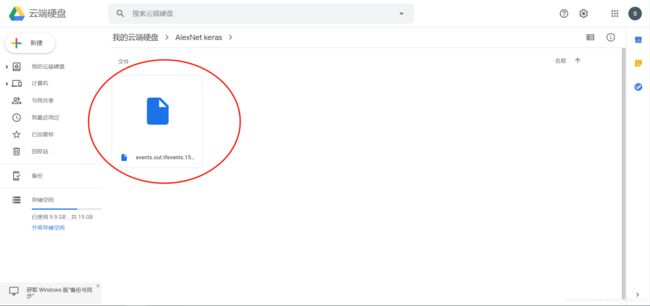
假设我们将文件放到桌面一个log的文件夹
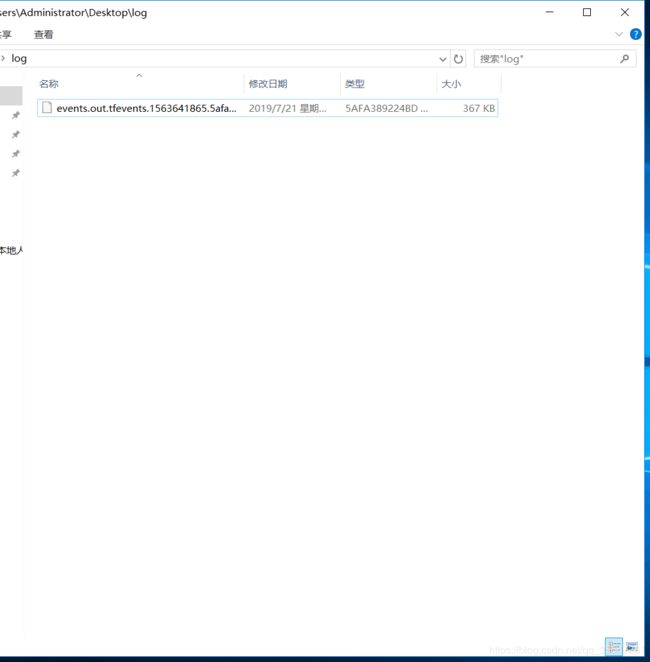
不要在意为什么会有两个,打开就完事儿,输入下面的代码,如果绝对路径不是这个的,右键那个下载文件查看属性,把地址copy出来,代替我给的这个
![]()
在Chrome上输入上面的网址,我这里是http://127.0.0.1:6006
然后就能看到我们的可视化训练过程了
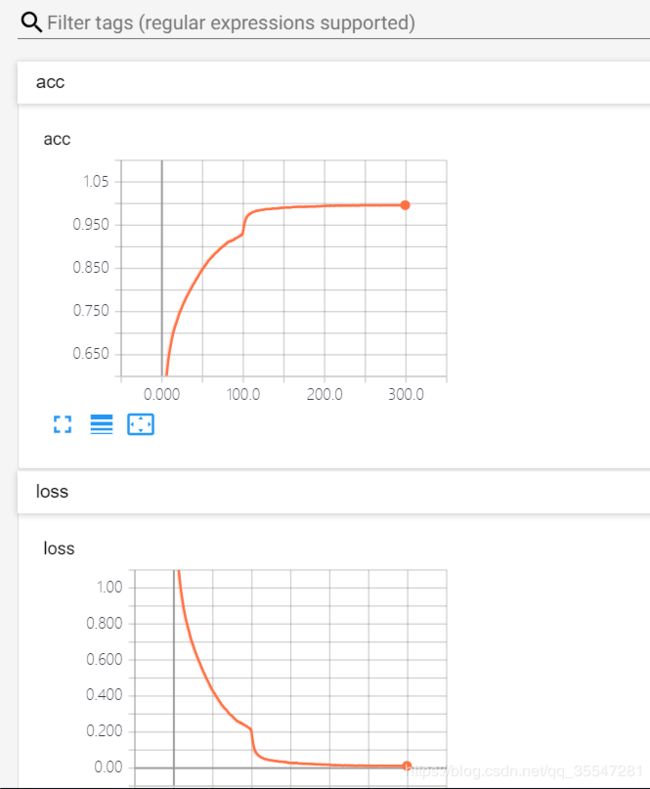
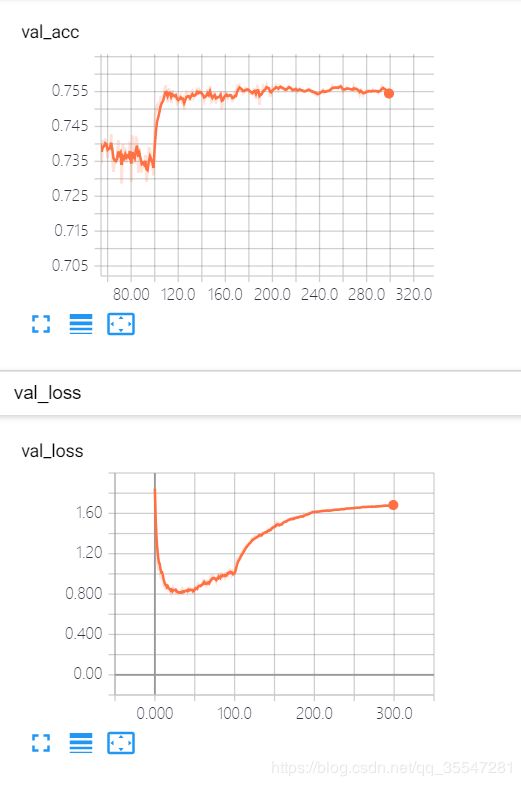
我们可以看到120个epoch的时候就开始过拟合了,我们模型的准确率维持在75.5%左右。
特别特别感谢大佬的这篇文章,让小白的我终于会用keras复现AlexNet
https://blog.csdn.net/bryant_meng/article/details/86527282#commentsedit