cnn文本分类——运行代码text-classification-cnn-rnn-master路上遇到的坑——自定义数据集
本文章主要是把自己的数据整理成和大神代码相符的数据,然后再使用大神的代码。
运行过程可能有些许地方没写清楚,可参考另一个博主文章 https://blog.csdn.net/weixin_40931845/article/details/83865877#
该博主参考本文章之后写的教程,可能比较清晰。
这几天在做综合实训(如果你看到这个文档,我猜你多半是hzau的学弟或者学妹,当然,假如带队老师还有这个项目。。像我一样,像我一样的看到这个压缩包的代码,遇到同样的问题,orz,),研究内容是文本分类。我选了实训要求的最后一步cnn做分类,其中遇到好多问题,首先参考大神的代码:
网上流传最多的是这个文件:text-classification-cnn-rnn-master,用了cnn和rnn,我只取了cnn,如果时间允许我也会做一下rnn的。
点击下载大神代码
环境:python3.6 tensorflow1.9.0 cuda9 windows10专业版
首先大神的代码运行就出了问题,我一直以为python文件要全部运行才可以,结果仔细看了大神的介绍,需要通过命令行运行的。附运行代码示例(注意更改程序中的文件路径,注:所有截图只是运行结果的部分图):
运行这个开始训练
python run_cnn.py train
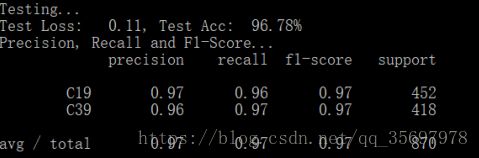
运行这个开始测试
python run_cnn.py test
接下来就是使用自己的语料,这里我们自己用的是复旦的语料,因为小组其他两个成员用的是这个语料做了朴素贝叶斯分类,然后我需要用同样的语料进行验证,更整理自己的语料时候花了很多时间。
生成语料步骤介绍如下:

.sh脚本我这儿运行不了,改了路径之后运行会直接删除文件夹下所有文件,一怒之下自学了脚本语言,改了他的脚本,代码如下,只不过是个拷贝各个分类文件下所有文件到同一个文件夹:
#!/bin/bash
# copy MAXCOUNT files from each directory
MAXCOUNT=6500
for category in $( ls D:/python/text-cnn/helper/txt/train); do
echo item: $category
dir=D:/python/text-cnn/helper/txt/train/$category
newdir=D:/python/text-cnn/helper/txt/2
COUNTER=1
for i in $(ls $dir); do
cp $dir/$i $newdir
if [ $COUNTER -ge $MAXCOUNT ]
then
echo finished
break
fi
let COUNTER=COUNTER+1
done
done
这里我把所有子文件夹文件全部拷贝到2文件夹效果如图:
拷贝前:
拷贝后:
拷贝前各个文件夹文件数目不定,拷贝后到2文件夹,共计9804个文件。震惊!!我好像没用到这个啥6500。。
第二步是改py脚本把各个文件内容合并到一个文件里面,这里我会详细注释,代码如下:
#!D:/python/text-classification-cnn-rnn-master/helper/txt/1
# -*- coding: utf-8 -*-
"""
将文本整合到 train、test、val 三个文件中
"""
import os
def _read_file(filename):
"""读取一个文件并转换为一行"""
with open(filename, 'r',encoding = 'utf-8',errors= 'ignore') as f:
return f.read().replace('\n', '').replace('\t', '').replace('\u3000', '')
def file(dirname):
"""
将多个文件整合并存到3个文件中
d: 原数据目录
文件内容格式: 类别\t内容
"""
f_train = open('D:/python/text-cnn/helper/txt/1/s.train.txt', 'w',encoding = 'utf-8',errors= 'ignore')
f_test = open('D:/python/text-cnn/helper/txt/1/s.test.txt', 'w',encoding = 'utf-8',errors= 'ignore')
f_val = open('D:/python/text-cnn/helper/txt/1/s.val.txt', 'w',encoding = 'utf-8',errors= 'ignore')
for category in os.listdir(dirname): # 分类目录
#cat_dir = os.path.join(dirname,category) #我发现这个得到的路径有问题:D:/python/text-cnn/helper/txt/2\C7-History932.txt有个反斜杠
#cat_dir = os.path.abspath(category) #然后换了这个之后很完美:D:\python\text-cnn\helper\C7-History932.txt都是反斜杠了啊啊啊啊!!但是目录不对!!
#print(dirname) #看一下dirname里面是啥 D:/python/text-cnn/helper/txt/2
#print(category) #看一下category里面是啥 C11-Space0001.txt
cat_dir = dirname + '/'+ category #目录名称无效。: 'D:/python/text-cnn/helper/txt/2/C11-Space0001.txt' 这个怎么不对了哦
#print(cat_dir) #看一下cat_dir里面是啥
#if not os.path.isdir(cat_dir):
# continue
files = os.listdir('D:/python/text-cnn/helper/txt/2') #我要cat_dir有何用,自己写一个路径哦...
#print(files) #让我们来看看这里面到底有什么 :是2文件夹下的所有文件名
count = 0
for cur_file in files:
filename = os.path.join(dirname, cur_file)
content = _read_file(filename)
if count < 5000:
f_train.write(category + '\t' + content + '\n')
elif count < 6500:
f_test.write(category + '\t' + content + '\n')
else:
f_val.write(category + '\t' + content + '\n')
count += 1
print('Finished:', category)
f_train.close()
f_test.close()
f_val.close()
if __name__ == '__main__':
file('D:/python/text-cnn/helper/txt/2')
print(len(open('D:/python/text-cnn/helper/txt/1/s.train.txt', 'r',encoding = 'utf-8',errors= 'ignore').readlines())) #'utf-8' codec can't decode byte 0xd3 in position 0: invalid continuation byte一怒之下删了所有utf-8
print(len(open('D:/python/text-cnn/helper/txt/1/s.test.txt', 'r',encoding = 'utf-8',errors= 'ignore').readlines())) # 'gbk' codec can't decode byte 0xaa in position 134: illegal multibyte sequence删了之后..我也是醉了哦
print(len(open('D:/python/text-cnn/helper/txt/1/s.val.txt', 'r',encoding = 'utf-8',errors= 'ignore').readlines()))
看到这个界面真舒服:
过了几分钟,突然感觉不对劲,计算了一下,9800多个文件,平均一个文件5s,这要运行13个小时啊啊啊啊啊啊啊!!!
那我少选点把。。于是删除了同类里面的文件,这里删除同类文件,我是打算直接删了所有文件,然后在各个分类文件夹下删除文件,重新运行.sh脚本,这个拷贝运行很快的,当然,前提是你的笔记本也是4G运存+16G内存+1050ti,好了不说了,京东白条刚还完,吃了好几个月的土。。算一下大概半小时的量30*60/5=360,大概需要360个文件。这时候超算的作用就出来了,超级计算机并行运算,还是很快的,可能半个小时就能解决这9800个文件,而我需要12个小时甚至更多。
在这里还发现了一个问题,我看到大概只写了几十个文件,然后结果里面是几个G的信息。。有毒啊啊啊啊啊!!!
然后手动复制了9个文件试一下大概5秒钟不到运行完:啥玩意儿??黑人问号脸....:
看来是字符问题,于是乎更改了一下代码,都改成gbk,然后还去掉了erros,出来的没有乱码,不知道之前为什么不能用gbk:


既然运行速度这么快。。那是不是因为之前有乱码,我有个大胆的想法。。咱们再来一次,艾玛我删了所有文件,那再来运行下我的.sh小脚本把,这次咱先不改文件数量。
来看看我们的.sh小可爱运行界面:
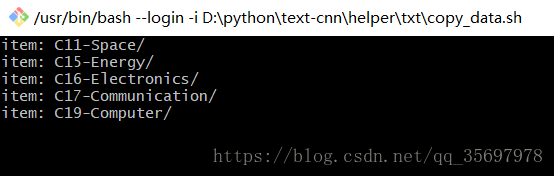
昨天改.sh时候没有写文档啊啊啊啊,其实昨天的更改之路还更有意思,差点给格盘了哦。。。因为.sh是脚本文件,运行之后如果有错误会一闪而过,然后我下载了git用bash命令行来查看错误信息,补一个bash界面:
咦,脚本运行好了,咱们的9804个项目又双叒叕回来了!!!那再来一遍:

看来是某个小文件偷偷在阻止我们运行,之前9个文件能运行时因为里面没有gbk解决不了的,那我们再加上errors:
运行了不到30个文件,又出现问题,已经1个G了!!!!!:

删了刚才的文件,重新运行,只读了一个文件,然而80多M的文件似乎在说我是傻逼:


于是乎,重新运行程序,不到1s中马上停止运行,还是出来了17m,看了下内容。。这,我好像就是傻逼,复制了几十遍吧:

为什么9个文件运行很快呢?我又重新复制了5个文件放进去,看了下运行结果,大概是5*5=25个文件,也就是循环了5次复制同一个文件内容,而9800个文件会循环9800次9800*9800个文件我滴妈呀,难怪会那么慢。。。也就是说我其实9800个文件只需要5秒钟吧。。好了,时间还行,这就来改改代码,改来改去终于成功了,然而得到的是顺序文档,也就是三个最终文档的数据可能完全不一样:
#!D:/python/text-classification-cnn-rnn-master/helper/txt/1
# -*- coding: utf-8 -*-
"""
将文本整合到 train、test、val 三个文件中
"""
import os
def _read_file(filename):
"""读取一个文件并转换为一行"""
with open(filename, 'r',encoding = 'gbk',errors='ignore') as f:
return f.read().replace('\n', '').replace('\t', '').replace('\u3000', '')
def file(dirname):
"""
将多个文件整合并存到3个文件中
d: 原数据目录
文件内容格式: 类别\t内容
"""
f_train = open('D:/python/text-cnn/helper/txt/1/s.train.txt', 'w',encoding = 'gbk')
f_test = open('D:/python/text-cnn/helper/txt/1/s.test.txt', 'w',encoding = 'gbk')
f_val = open('D:/python/text-cnn/helper/txt/1/s.val.txt', 'w',encoding = 'gbk')
#for category in os.listdir(dirname): # 分类目录
# cat_dir = os.path.join(dirname, category) #我发现这个得到的路径有问题:D:/python/text-cnn/helper/txt/2\C7-History932.txt有个反斜杠
#cat_dir = os.path.abspath(category) #然后换了这个之后很完美:D:\python\text-cnn\helper\C7-History932.txt都是反斜杠了啊啊啊啊!!但是目录不对!!
#print(dirname) #看一下dirname里面是啥 D:/python/text-cnn/helper/txt/2
#print(category) #看一下category里面是啥 C11-Space0001.txt
#cat_dir = dirname + '/'+ category #目录名称无效。: 'D:/python/text-cnn/helper/txt/2/C11-Space0001.txt' 这个怎么不对了哦
#print(cat_dir) #看一下cat_dir里面是啥
#if not os.path.isdir(cat_dir):
# continue
#cat_dir.replace('\\','/')
files = os.listdir(dirname)
# print(cat_dir) #让我们来看看这里面到底有什么
count = 0
for cur_file in files:
filename = os.path.join(dirname, cur_file)
#print(filename)
print(cur_file)
content = _read_file(filename)
if count < 5000:
f_train.write(cur_file + '\t' + content + '\n')
elif count < 7600:
f_test.write(cur_file + '\t' + content + '\n')
else:
f_val.write(cur_file + '\t' + content + '\n')
count += 1
print('Finished:', cur_file)
f_train.close()
f_test.close()
f_val.close()
if __name__ == '__main__':
file('D:/python/text-cnn/helper/txt/2')
print(len(open('D:/python/text-cnn/helper/txt/1/s.train.txt', 'r',encoding = 'gbk').readlines())) #'utf-8' codec can't decode byte 0xd3 in position 0: invalid continuation byte一怒之下删了所有utf-8
print(len(open('D:/python/text-cnn/helper/txt/1/s.test.txt', 'r',encoding = 'gbk').readlines())) # 'gbk' codec can't decode byte 0xaa in position 134: illegal multibyte sequence删了之后..我也是醉了哦
print(len(open('D:/python/text-cnn/helper/txt/1/s.val.txt', 'r',encoding = 'gbk').readlines()))
骚操作来了,取个count+1,然后给他取模,把9804个文件平均分到三个文件里,果然成功了:


至此,子集文件搞定,庆祝一下吧,比如出去上个厕所。。看看隔壁的漂亮小姐姐。
上了个厕所回来发现,问题来了,怎么人家的男孩子都有漂亮小姐姐,我怎么没有呢。。。咳咳,错了错了。怎么人家有四个文件,而我只有三个文件怎么办,于是打开他的第四个文件看了看,好家伙,这不正是停用词么,之前还在奇怪问什么这个cnn就不用停用词了,没想到在这里。ok,开始改路径(因为早上嫌文件名太长改了下,这下..emm.....)
改完文件名,先看这个

这个文件没有改文件名的,只有类别需要更改,于是乎,我的20个类别上场了,建议你做的时候先用10个,和源程序的个数一样,否则中间出了问题就不好办了。(尽量选择文件多的文件类别),结果如下,我猜测这是初始化向量表吧。。看不懂:

然后就是
这个。。。好像也不用改路径名,不知道这两个文件到底用来干啥的,结果:

在后面重点来了

然后看了run_cnn.py,好像真的没有用上前面两个的结果..
我怎么感觉多做了两步....
这里需要更改的路径也只有两个,算了不管了,直接运行吧.
有种不祥的预感:
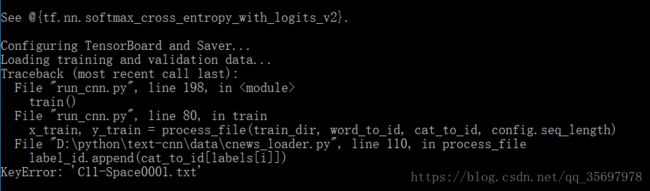
想了想和原数据的区别,原数据按分类名保存文件,而我的是按各个文件名保存,所以是名字错了,那.......改吧。。从头再来。
我查到了剪切字符串代码,把文件名前三个字符减下来,因为前面的文件路径什么的实在是太烦了,用文件夹名字挺好,但是又得去搞定这该死的文件路径啥的。
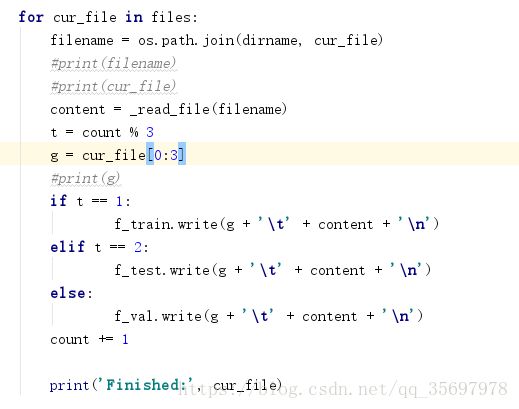
结果如下,出现了C3-但是这个应该不影响吧:

文件搞定,跳转到上面步骤,这次让我来看看自己的教程吧....
loader再改一次以示敬意:

假如这玩意儿存在我的内存里面那他还是有用的,如果不存在,emm.....那我回去再想想...
同样,cnn_module再改以示敬意。
再删一次那个tensorboard/textcnn...
终于回到上一步了:
这有是啥啊啊啊啊啊啊啊啊啊啊啊啊啊!!!!
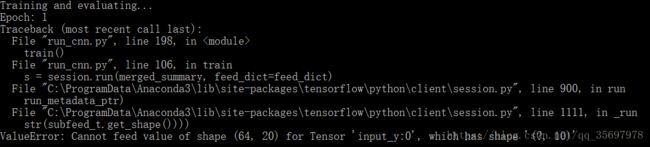
好吧,终于到了改矩阵代码了,这我根本就不会好吧...喵了个咪啊。。。
实在不想改矩阵代码,这玩意儿我暂时没学,还是乖乖回去把个分类改成10个吧,结果这...怎么还有8000多个文件哦。。
重复之前步骤,把train文件里的20个分类删10个,正好把那几个只有两个字符带“-”的删了,重复上面步骤:
成功了:

中间的2 4 6 8 9为嘛没有???
先不管了,再试试测试,运行成功????
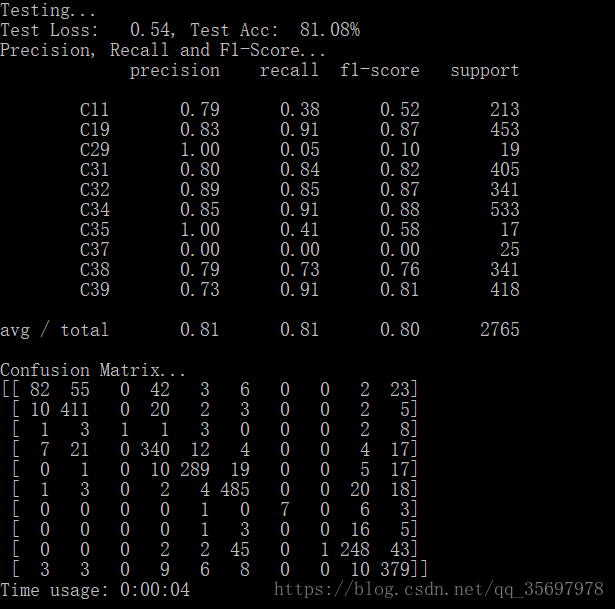
ok就这样,回头再看看rnn的吧,现在有事先不继续做下去了。
7.17补充:
1. 仔细看了代码,cnn_module.py cnn_loader.py 这两个代码是有用的,在run_cnn中调用。
2. 关于类别数目,除了修改cnn_loader里面的矩阵数目,还要修改cnn_module里面的类别数,通过修改这个,完成了2的分类,也就是说,可以完成任意数目的分类了: