tensorflow实战之三:MNIST手写数字识别的优化2-多层感知器
上一章我们用到交叉熵代价函数来优化我们的模型,但是最后的准确率也只有92%,这一节我们会实现一个多层的神经网络其中会用的后面一节的知识。新手的话耐心点看看,会有不少收获偶。
那我们就直接上代码了:
import tensorflow as tf
from tensorflow.examples.tutorials.mnist import input_data
mnist = input_data.read_data_sets("MNIST_data",one_hot=True)老规矩先导入我们的MNIST数据集
#每个批次的大小
batch_size = 100
#计算一共有多少个批次
n_batch = mnist.train.num_examples // batch_size定义每一个批次训练数据集的大小为100(就是每次向神经网络输入100张图片)和批次数目
#定义两个placeholder
x = tf.placeholder(tf.float32,[None,784])
y = tf.placeholder(tf.float32,[None,10])
keep_prob=tf.placeholder(tf.float32)定义我们的图片及标签的容器placeholder ,这里的keep_prob就是指的消除神经网络过拟合的Dropout参数,具体的原理后面会讲到。
#创建一个简单的神经网络
W1 = tf.Variable(tf.truncated_normal([784,300],stddev=0.1))
b1 = tf.Variable(tf.zeros([300])+0.1)
L1 = tf.nn.tanh(tf.matmul(x,W1)+b1)
L1_drop = tf.nn.dropout(L1,keep_prob)
W2 = tf.Variable(tf.truncated_normal([300,500],stddev=0.1))
b2 = tf.Variable(tf.zeros([2000])+0.1)
L2 = tf.nn.tanh(tf.matmul(L1_drop,W2)+b2)
L2_drop = tf.nn.dropout(L2,keep_prob)
W3 = tf.Variable(tf.truncated_normal([500,300],stddev=0.1))
b3 = tf.Variable(tf.zeros([300])+0.1)
L3 = tf.nn.tanh(tf.matmul(L2_drop,W3)+b3)
L3_drop = tf.nn.dropout(L3,keep_prob)
W4 = tf.Variable(tf.truncated_normal([300,10],stddev=0.1))
b4 = tf.Variable(tf.zeros([10])+0.1)
prediction = tf.nn.softmax(tf.matmul(L3_drop,W4)+b4)这里我们一共定义了4层的网络,为了防止过拟合的现象,我们采用了Dropout的策略,也就是tf.nn.dropout,其实就是:每次训练随机的让神经网络的某一层的部分神经元无效,后面我们会具体讲到。我们现在只需要理解该网络由1层变为了4层,提取特征以及识别的能力都得到了大大的加强,那是不是神经网络的层数越多越好呢,答案是否,因为具体的问题要具体分析,对于一个简单的问题,我们并不需要很复杂的网络,这是因为网络层数太多,不仅对于问题本身没有帮助,还会引起过拟合的效应(后面会讲到),另外,
这里的tf.nn.tanh是一种激活函数,上一节我们用到的是tf.nn.softmax,这里我们可以暂时不用区别它们。还有我们没有采用tf.zeros将W1,W2,W3,W4初始化为0,而是采用tf.truncated_normal将权值全部初始化为方差为0.1的正态分布,至于为什么要这么做,简单但理解就是为了防止0梯度发生(具体不是很清楚)
init = tf.global_variables_initializer()
#结果存放在一个布尔型列表中
correct_prediction = tf.equal(tf.argmax(y,1),tf.argmax(prediction,1))#argmax返回一维张量中最大的值所在的位置
#求准确率
accuracy = tf.reduce_mean(tf.cast(correct_prediction,tf.float32))
with tf.Session() as sess:
sess.run(init)
for epoch in range(31):
for batch in range(n_batch):
batch_xs,batch_ys = mnist.train.next_batch(batch_size)
sess.run(train_step,feed_dict={x:batch_xs,y:batch_ys,keep_prob:0.7})
test_acc = sess.run(accuracy,feed_dict={x:mnist.test.images,y:mnist.test.labels,keep_prob:1.0})
train_acc = sess.run(accuracy,feed_dict={x:mnist.train.images,y:mnist.train.labels,keep_prob:1.0})
print("Iter " + str(epoch) + ",Testing Accuracy " + str(test_acc) +",Training Accuracy " + str(train_acc))
后面的代码几乎没什么变化,唯一的变化就是引入了keep_prob参数,我们在执行训练的时候传入keep_prob=0.7,意思就是我们每次训练随机的保留70%的神经元进行训练,
而在测试的时候传入1.0,就是保留所有的神经元进行测试。这就是Dropout的思想,训练的时候随机去掉部分神经元,而测试时候保留所有神经元。
运行结果如下:
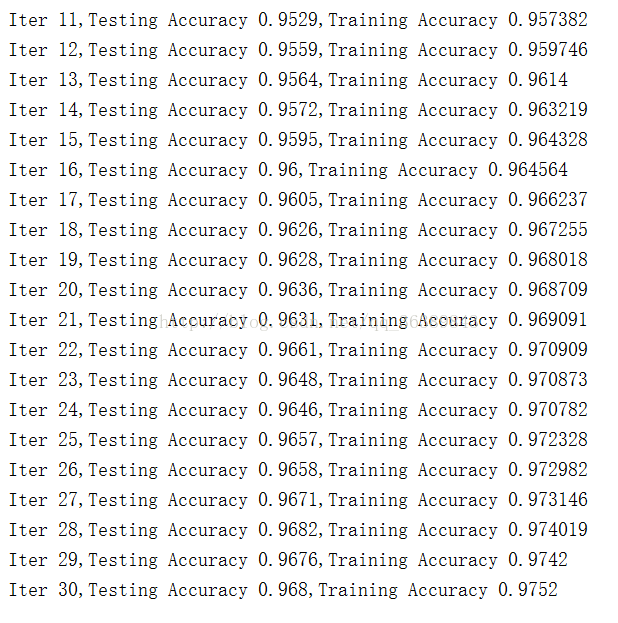
可以发现我们在训练集上到达了97.52%的准确率,测试集上达到了96.8%的准确率,实际上真正有用的数据是96.8%,这个数据比起前面的已经有了不少提高了。这就是多层神经网络的力量。