数据挖掘经典算法:FP-Growth算法(高效发现频繁项集)
本篇文章介绍一中与上一章Apriori算法功能类似的一种算法——FP-Growth,该算法速度更快、大多情况下效果更好,但是不能用于发现关联规则。以下都是通过机器学习实战与本人的实践过后的总结。
FP-Growth算法,基于Apriori构建,但在完成相同任务时采用了不同的技术,其只需要对数据集进行两次扫描,而Apriori算法对于每个潜在的频繁项集都会扫描数据集判定给定模式是否频繁,因此其比Apriori算法快。FP算法需要将数据集存储在一个特定的称作FP树的结构之后发现频繁项集或者频繁项对。两次扫描步骤如下:
-
构建FP树
-
从FP树挖掘频繁项集
FP-Growth算法使用一种叫做FP树的数据结构,这种数据结构能更好的处理复杂的数据存储问题,相比Apriori算法实现起来就比较复杂,某些数据集上性能也可能下降,FP表示频繁模式,一颗FP树看起来与计算机科学中的其它树结构相似,但是它是使用链接(link)来连接相似元素,被连接的元素看起来就像链表一样,如下图所示:

相同的元素之间通过link来连接,同搜索树不同的是,一个元素项可以在一棵FP树中出现多次。FP树会存储项集的出现频率,而每个项集会以路径的方式存储在树中。存在相似元素的集合会共享树的一部分。只有当集合之间完全不同时,树才会分叉。树节点上给出集合中的单个元素及其在序列中的出现次数,路径会给出该序列的出现次数。相似项之间的链接即节点链接,用于快速发现相似项的位置。
(就我个人实践后而言,FP-Growth算法难点在于将(FP树的数据结构、FP树的创建、条件模式基查找、创建条件FP树)等几个重要的步骤结合起来使用可能有点复杂,理解起来也容易混乱,但是就每一个步骤而言是很容易理解的,我在每一个步骤中也有相关的注释,千万不要被稍多的代码吓到。)下面就每个分成块的内容实现代码进行介绍:
FP树的数据结构:
由于FP树需要存储的内容比较复杂且节点间的关联性比较大,所以这里采用类来封装这些属性,每一个树的节点使用类来保存。
# 树节点用类来封装所有属性(以便解决复杂的数据存储问题)
class treeNode:
def __init__(self, nameValue, numOccur, parentNode):
self.name = nameValue # 元素名
self.count = numOccur # 该路径下该元素次数
self.nodeLink = None # 用来指向它的相同元素位置不同的节点的位置
self.parent = parentNode # 获取父节点,该功能方便后面查找前缀路径(条件模式基)
self.children = {} # 该节点的子节点
def inc(self, numOccur):
self.count += numOccur
# 画树便于直观的观察和调试(实际代码意义不大,但很重要)
def disp(self, ind=1):
print(' ' * ind, self.name, ' ', self.count)
for child in self.children.values():
child.disp(ind + 1)
# 检验以下树的创建
rootNode = treeNode('pyramid',9,None) # 创建根节点
rootNode.children['eye'] = treeNode('eye',13,None) # 创建子节点
rootNode.children['phoenix'] = treeNode('phoenix',3,None)
rootNode.children['eye'].children['mm'] = treeNode('mm',6,None) # 创建子节点的子节点
rootNode.disp() # 画出树图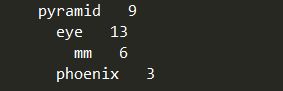
比较简单的实现,后面树的建立都需要调用该类来创建相关的数据结构,且节点之间也需要设置它的属性来连接。
FP树的创建:
其实FP树还需要一个头指针表来指向给定类型的第一个示例,然后再从指向的节点指向下一个节点,头指针表就是一个指向入口后面可以用来快速查找前缀路径等作用,如下图所示:

在对事务记录过滤和排序之后,就可以构建FP树了。从空集,向其中不断添加频繁项集。过滤、排序后的事务依次添加到树中,如果树中巳存在现有元素,则增加现有元素的值;如果现有元素不存在,则向树添加一个分枝。

前两个函数仅为创建测试数据,提供测试样例。
# 创建测试数据
def loadSimpDat():
simpDat = [['r', 'z', 'h', 'j', 'p'],
['z', 'y', 'x', 'w', 'v', 'u', 't', 's'],
['z'],
['r', 'x', 'n', 'o', 's'],
['y', 'r', 'x', 'z', 'q', 't', 'p'],
['y', 'z', 'x', 'e', 'q', 's', 't', 'm']]
return simpDat
# 将记录数据转换为frozenset的字典并初始化为1,才能后续的树构造
def createInitSet(dataSet):
retDict = {}
for trans in dataSet:
retDict[frozenset(trans)] = 1
return retDict
# 创建树的主要封装函数
def createTree(dataSet, minSup=1): # 从数据集创建FP-tree但不挖掘
headerTable = {}
# 遍历两次数据集
# 第一次遍历数据集 计算所有元素的频率,返回字典样式
for trans in dataSet:
for item in trans:
headerTable[item] = headerTable.get(item, 0) + dataSet[trans] # get方法类似于[item],直接取值,但是由于第一次取值为空,我们需要返回0,最为当前值,否则出错
for k in list(headerTable.keys()): # 循环所有的键,去除小于阈值的键值对
if headerTable[k] < minSup: # py3字典在遍历的时候不能更改,所以需要list(a.keys())
del (headerTable[k])
freqItemSet = set(list(headerTable.keys()))
if len(freqItemSet) == 0:
return None, None # 如果没有满足最小minSup的元素则退出
for k in headerTable: # 后面试试在前面的for中就构建好!!!
headerTable[k] = [headerTable[k], None] # 重新构造 headerTable (计数值,指向第一个元素项的指针)
retTree = treeNode('Null Set', 1, None) # 构建最初的空值树
# 第二次遍历数据集 构建FP树(只考虑第一次判定的频繁项
for tranSet, count in dataSet.items():
localD = {}
for item in tranSet: # 为每条筛选后不为0的记录排序
if item in freqItemSet: # 如果所有频繁项中有该值
localD[item] = headerTable[item][0]
if len(localD) > 0:
# print(localD) #{'z': 5, 'r': 3}
# 排序主要步骤:通过sorted方法排序,排序的值key=items获得字典的值的第二个值(即元素个数),reverse=True表示降序排序,最后通过列表中只保存元素,不保留个数
orderedItems = [v[0] for v in sorted(localD.items(), key=lambda p: p[1], reverse=True)] # ['z','r']
updateTree(orderedItems, retTree, headerTable, count) # 使用有序的频繁项集填充树
return retTree, headerTable # 返回树和头表
# 将每条有序项集添加到树中
def updateTree(items, inTree, headerTable, count):
if items[0] in inTree.children: # 递归时都先判断当前画树的值是否在树的子节点上,如果在则不需要画,只需增加count值
inTree.children[items[0]].inc(count) # 给该子节点增加count值(通过类的函数inc)
else:
# 如果不在则需要画新的树节点 并且(由于新画了节点,所以需要将相同的该元素节点指向它,若是第一次则用头表指向它)
inTree.children[items[0]] = treeNode(items[0], count, inTree) # 画树只需要调用类的子函数treeNode即可
# 更新头表
if headerTable[items[0]][1] == None: # 若头表中该值没有连接过则
headerTable[items[0]][1] = inTree.children[items[0]] # 创建link连接,将头表该元素字典的列表的第二个元素记录为该树节点
else: # 若有link连接则更新
updateHeader(headerTable[items[0]][1], inTree.children[items[0]]) # 传入(原来头表指向的节点,新画的节点)
if len(items) > 1: # 当还有元素时,则继续调用updateTree更新FP树
updateTree(items[1::], inTree.children[items[0]], headerTable, count)
# 更新头表
def updateHeader(nodeToTest, targetNode): # 这个版本不使用递归
while (nodeToTest.nodeLink != None): # 不要使用递归来遍历链表!!
nodeToTest = nodeToTest.nodeLink
nodeToTest.nodeLink = targetNode
simpDat = loadSimpDat() # 前面两个函数仅为创建数据集用来测试
initSet = createInitSet(simpDat)
myFPtree,myHeaderTable = createTree(initSet,3) # FP树 头表
myFPtree.disp() # 画出FP树
print(myHeaderTable)获得的FP树 和 头表如下:
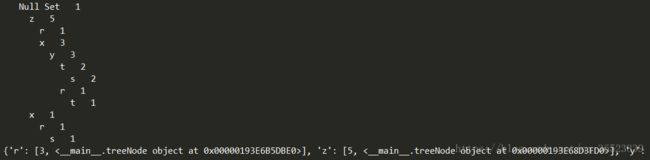
树的创建同样很简单,updateTree为生长树的函数这也是FP-Growth中‘Growth’生长一词的含义。
条件模式基查找:
创建了FP树后从该树种数据挖掘频繁项集的步骤如下:
-
从FP树种获得条件模式基
-
利用条件模式基创建FP条件树
-
重复迭代1、2步骤,直到树包含一个元素项为止
如何抽取条件模式基呢?首先从上面发现的已经保存在头指针表中的单个频繁元素项开始。对于每个元素项获得其对应的条件模式基。条件模式基是以所查找元素项为结尾的路径集合,每一条路径其实都是一条前缀路径。简而言之,一条前缀路径是介于所查找元素项与树根节点之间的所有内容。

前缀路径将被用来构建条件FP树,但是这里先讨论如何查找前缀路径。1:可以通过穷举式搜索, 直到获得所有的频繁项位置。2:利用先前的头指针表,头指针表包含相同类型元素链表的起始指针。一旦到达每个元素项,就可以上溯这棵树直到根节点。
很显然2是一种更高效、更简单的方法,所以这里采用2这种方法来进行前缀路径的获取,头表中的每个元素的每条路径都回溯完后便是完整的条件模式基了。下面介绍该方法:
# 获取一条前缀路径
def ascendTree(leafNode, prefixPath): # 从末节点回溯到根节点
if leafNode.parent != None: # 由于前面画节点的时候,保存了上一个节点为下一个节点的父节点
prefixPath.append(leafNode.name)
ascendTree(leafNode.parent, prefixPath) # 回溯到根节点
# 获取条件模式基(前缀路径集合)
def findPrefixPath(basePat, treeNode): # treeNode comes from header table
condPats = {}
while treeNode != None:
prefixPath = []
ascendTree(treeNode, prefixPath)
if len(prefixPath) > 1:
condPats[frozenset(prefixPath[1:])] = treeNode.count
treeNode = treeNode.nodeLink # 获取下一个前缀路径的最后一个节点
return condPats #{每条前缀路径:最后一个元素的计数值}
# 某元素的条件模式基获取
print(findPrefixPath('x',myHeaderTable['x'][1]))
print(findPrefixPath('r',myHeaderTable['r'][1]))可以将结果与上面的图相比较看看是否正确(由于代码原因所以每次运行可能结果不同):
![]()
获得了关于'x','r''的条件模式基,此段代码调用了前面获得的头指针表来上溯,此两段函数内容较少,也比较简单,但操作确实很骚的,可以对比着FP树结合节点数据结构来形象的理解。
创建条件FP树:
# 创建条件树 第一个参数意义不大 最小阈值 {}集合 []列表
def mineTree(inTree, headerTable, minSup, preFix, freqItemList):
# 错误代码说明:p是:('r', [3, <__main__.treeNode object at 0x000002251A5F4BA8>]) p[1]是:[3, <__main__.treeNode object at 0x000002251A5F4BA8>]
# 所以还需要对p[1]取[0],得到key=3,用计数值排序而不是树结构排序
bigL = [v[0] for v in sorted(headerTable.items(), key=lambda p: p[1][0])] # 头表排序,只取键'r'
for basePat in bigL: # 从头表的底部开始 ['r', 's', 't', 'y', 'x', 'z']
newFreqSet = preFix.copy()
newFreqSet.add(basePat) # 添加频繁元素到上一次的集合中
# print(newFreqSet)
freqItemList.append(newFreqSet) # 这个列表用来保存所有的频繁项集
condPattBases = findPrefixPath(basePat, headerTable[basePat][1]) # 找到条件模式基(即前缀路径集合)
# 用该元素的条件模式基来创建该元素条件FP树
myCondTree, myHead = createTree(condPattBases, minSup) # 返回 条件FP树、头表
if myHead != None: # 继续挖掘FP树
mineTree(myCondTree, myHead, minSup, newFreqSet, freqItemList)
# 创建条件FP树,并获得频繁项集
freqItems = []
mineTree(myFPtree,myHeaderTable,3,set([]),freqItems)
print(freqItems)最后这个函数虽然代码量少,但是却包含了所有的内容,所以需要仔细的理解,主要用的是前面构建FP树时的头表信息,以及每个节点保存的信息。用头表获得每个元素的条件模式基,然后再用条件模式基来创建条件FP树。每次运行都是用freqItems列表来保存下
![]()
由于使用的集合所以结果的每个元素时随机的,如果像更好的观察数据的添加,可以将set([])变为列表[],然后使用append,可以更好的查看元素的添加过程。
![]()
好了以上便是FP-Growth算法的全部内容,特点:每一步的运算相对较简单,但是将整个代码过程结合起来有点复杂,这也是该算法的一个缺点,尤其值最后一个函数代码量少却包含了太多的东西。
频繁项集的应用比较广法,比如购物交易、医学诊断、大气研究等等,本文最后在引入一个书上的实际示例:一个数据集包含一百万多条信息,每条信息为一个人读的文章的编号,我们需要找出哪些文章集合是被超过100000人看过的(那么这些文章集合便是要找的频繁项集)。
实际示例:
样例数据(每个人读的不一样):

主要调用上述的代码,以及加载本地的数据集:
# 实际数据操作(每个人阅读的文章编号集合)
parsedDat = [line.split() for line in open('kosarak.dat').readlines()] # 每一个数字代表一篇新闻的编号
initSet = createInitSet(parsedDat)
myFPtree,myHeaderTab = createTree(initSet,100000) # 构建FP树,头表
myFreqList = []
mineTree(myFPtree,myHeaderTab,100000,set([]),myFreqList)
print(myFreqList) # 有多少新闻集合被超过100000人看过![]()
一共9条记录,FP-Growth算法真的比Apriori快太多了不止两个数量级,亲自用相同的数据测试过。
参考书籍:《机器学习实战》