java常用字节流总结
前言:
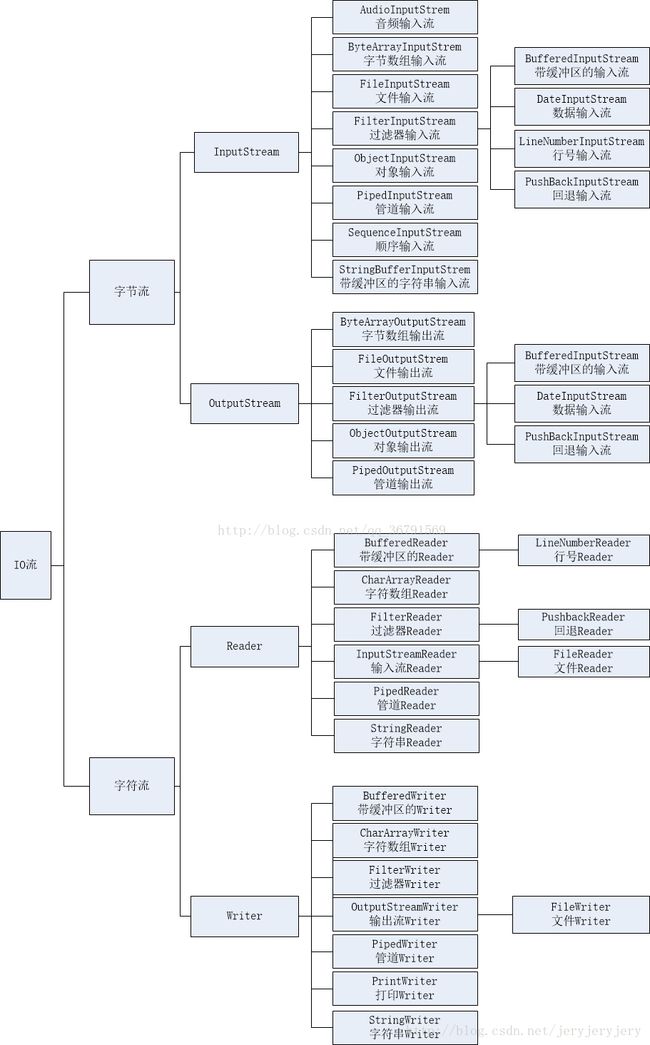
流的浅显总结(总结了常用的流的操作和一些关键点):
之前我对流的概念理解很片面,认为所谓输入输出流,都是面对程序和文件的概念
但是,我发现其实比较片面,而且疏漏点很多,其实也有程序和非本程序范围内的内存之间,最终不是都结束于文件和外存,在对已经加载到了内存中的数据的读和写也占了很大的一部分。
如若不全,更多详细方法:请查找JDK文档。
首先请参考于:
什么是native method:
wikeqi的博客CSDN
http://blog.csdn.net/wike163/article/details/6635321
还有对于Input和Output中的概念,是对于程序来讲的,我们应该从程序的角度来看,我们从外部数据读取到程序中,为input;我们将程序中的数据输出到外部,为output。
InputStream
ByteArrayInputStream
ByteArrayInputStream把字节数组中的字节以流的形式读出
还是相对于程序来讲的: 从 字节数组 à程序(内存中的数据)
ByteArrayOutputStream把内存中的数据读到字节数组中,而ByteArrayInputStream又把字节数组中的字节以流的形式读出,实现了对同一个字节数组的操作.
ByteArrayInputStream相对于ByteArrayOutputStream的(可以将程序中的数据读到自己内置的大小任意的缓冲区中,再写到一个Byte数组中)功能,显得比较鸡肋,在JDK介绍文档中介绍的都比较少(将字节数组中的数据,读到流中的缓冲区中,再反馈给程序)该缓冲区中包含从流中读取的字节。内部计数器跟踪read方法要提供的下一个字节。关闭ByteArrayInputStream无效(ByteArrayOutputStream相同)此类中的方法,在关闭此流之后,仍可以被调用,而不会产生IOException。
public ByteArrayInputStream(byte[] buf)
参数:
buf - 输入缓冲区。
public ByteArrayInputStream(byte[] buf,
int offset,
int length)
参数:
buf - 输入缓冲区。
offset - 缓冲区中要读取的第一个字节的偏移量。
length - 从缓冲区中读取的最大字节数。
用途:
/*
在网络中读取数据包,用于数据包是定长的,我们可以先分配一个够大的byte数组,例如: byte[] buffer = new byte[1024];
然后再通过网络编程中的操作:
*/
Socket s = …
DataInputStream dis = new DataInputStream(s.getInputStream());
// 先将所有的数据存到buffer中
dis.read(buffer);
// 把刚才的部分视为输入流
ByteArrayInputStream bais = new ByteArrayInputStream(buffer);
DataInputStream dis_2 = new DataInputStream(bais);
现在就可以使用dis_2的各种read方法,读取制定的字节
比如: dis_2.readByte();
and so on
上面的示例两次包转,看起来多次一举,但是中间使用了ByteArrayInputStream的好处是关掉了流依然存在。
import java.io.ByteArrayInputStream;
import java.io.InputStream;
import java.io.ByteArrayInputStream;
import java.io.InputStream;
public class ByteArrayInputStreamDemo {
public static void main(String[] args)throws Exception{
Data data = new Data();
byte[] temp = data.getData();
InputStream inputStream = new ByteArrayInputStream(temp);
byte[] arr =new byte[temp.length];
inputStream.read(arr);
System.out.println(new String(arr));
}
}
class Data{
byte[] data = "abc".getBytes();
public byte[] getData() {
returndata;
}
}FileInputStream
三个核心方法,也就是Override(重写)了抽象类InputStream的read方法。intread() 方法,即:
1. publicint read() throws IOException
代码实现中很简单,一个try中调用本地native的read0()方法,直接从文件输入流中读取一个字节。IoTrace.fileReadEnd(),字面意思是防止文件没有关闭读的通道,导致读文件失败,一直开着读的通道,会造成内存泄露。
/* 从此输入流中读取一个数据字节 */
public int read() throws IOException {
Object traceContext = IoTrace.fileReadBegin(path);
int b = 0;
try {
b = read0();
} finally {
IoTrace.fileReadEnd(traceContext, b == -1 ? 0 : 1);
}
return b;
}2. int read(byte b[]) 方法,即
public int read(byte b[]) throws IOException
代码实现也是比较简单的,也是一个try中调用本地native的readBytes()方法,直接从文件输入流中读取最多b.length个字节到byte数组b中。
/* 从此输入流中读取多个字节到byte数组中。 */
public int read(byte b[]) throws IOException {
Object traceContext = IoTrace.fileReadBegin(path);
int bytesRead = 0;
try {
bytesRead = readBytes(b, 0, b.length);
} finally {
IoTrace.fileReadEnd(traceContext, bytesRead == -1 ? 0 : bytesRead);
}
return bytesRead;
}3. int read(byte b[], int off, int len) 方法,即
public int read(byte b[], int off, int len) throwsIOException
代码实现和 int read(byte b[])方法一样,直接从文件输入流中读取最多len个字节到byte数组b中。
/* 从此输入流中读取最多len个字节到byte数组中。 */
public int read(byte b[], int off, int len) throws IOException {
Object traceContext = IoTrace.fileReadBegin(path);
int bytesRead = 0;
try {
bytesRead = readBytes(b, off, len);
} finally {
IoTrace.fileReadEnd(traceContext, bytesRead == -1 ? 0 : bytesRead);
}
return bytesRead;
}值得一提的native方法:
上面核心方法中为什么实现简单,因为工作量都在native方法里面,即JVM里面实现了。native倒是不少一一列举吧:
native void open(String name) // 打开文件,为了下一步读取文件内容
native int read0() // 从文件输入流中读取一个字节
native int readBytes(byte b[], int off, int len) //从文件输入流中读取,从off句柄开始的len个字节,并存储至b字节数组内。
native void close0() // 关闭该文件输入流及涉及的资源,比如说如果该文件输入流的FileChannel对被获取后,需要对FileChannel进行close。FileInputStream和FileOutputStream的应用(后不再贴):
第一层文本文档copy:
packageday7.bytestream;
importjava.io.FileInputStream;
importjava.io.FileNotFoundException;
importjava.io.FileOutputStream;
importjava.io.IOException;
/**
* 这里的路径没有写绝对路径使用的是相对路径
* 这里的test.txt文档自动生成在我的teacher_yang目录下
* 和src是同级的
* 补充:在windows中.txt .doc等扩展名只是标志这个文件是什么类型的软件产生的
* 但是其实这个扩展名是无关重要的,只是提示你用什么软件打开,一定能正常显示
* 只是可能不同软件使用的编码方式不同,会导致文件出错,但是纠其本质,文件都
* 是一串二进制的数字存储的。
* @author半步疯子
*
* 这个程序还有很多缺陷,就是这个程序进行程序拷贝的时候,是你的源文件有多大
* 它就会去形成多大的临界缓冲区,假如我们这个文件过大的话,就会导致我们的内
* 存占用过大,造成电脑死机等等问题。
* (但是我们也得明白:缓冲区的大小越大,必然拷贝搬运文件的速度就越快
* 但是缓冲区的大小最大就是需要拷贝文件的大小,再大的话拷贝的速度也不会再
* 提升了)
*/
public classFileCopy1 {
public static voidmain(String[] args) {
FileInputStreamfis = null;
FileOutputStreamfos = null;
try {
//源文件
fis= new FileInputStream("test.txt");
//目标文件
fos = newFileOutputStream("test1.txt");
//得到源文件的长度
intlen = fis.available();
//构造一个和源文件大小相同的buffer(临界区)
byte[]buffer =new byte[len];
//将源文件的数据读到程序中(buffer临界区内)
fis.read(buffer);
//将临界区buffer中的数据写到目标文件中去
fos.write(buffer);
} catch(FileNotFoundException e) {
//文件可能找不到的情况
e.printStackTrace();
}catch(IOException e) {
//输入输出异常
e.printStackTrace();
}finally {
if(fis!=null) {
try {
fis.close();
}catch (IOException e) {
e.printStackTrace();
}
}
if(fos!=null) {
try {
fos.close();
}catch (IOException e) {
e.printStackTrace();
}
}
}
}
}
第二层自定义缓冲区,拷贝大文件:
packageday7.bytestream;
importjava.io.FileInputStream;
importjava.io.FileNotFoundException;
importjava.io.FileOutputStream;
importjava.io.IOException;
public classFileCopy2 {
public static voidmain(String[] args) {
FileInputStreamfis = null;
FileOutputStreamfos = null;
try {
fis = newFileInputStream("E:\\安装包\\mysql-5.6.31-winx64.zip");
fos = newFileOutputStream("a.rar");
// 创建一个缓冲区
// 缓冲区越大,copy的速度越快,最快速度为缓冲区大小等于copy文件大小的时候
byte[] buffer =new byte[1024*8];
System.out.println("文件正在复制,请稍后...");
longbegin = System.currentTimeMillis();
while(true) {
/*
* read方法返回的是一个int值
* 表示读入缓冲区(buffer)的字节总数
* 因为各种方面的原因,read到缓冲区中
* 的字节数不一定每次都装满了len长度。
* 如果当前源文件中不存在可以读的字节
* 的时候,read的返回值为-1。
*/
intlen = fis.read(buffer);
if(len<0){
break;
}
fos.write(buffer,0, len);
/*
*fos的flush方法是手动清空buffer(缓冲区,或者临界区)
*在完成copy操作之后,会自动flush
*/
fos.flush();
}
longend = System.currentTimeMillis();
System.out.println("文件复制完成,耗时:"+(end-begin)+"毫秒");
} catch(FileNotFoundException e) {
e.printStackTrace();
} catch(IOException e) {
e.printStackTrace();
} finally {
if(fos!=null) {
try {
fos.close();
}catch (IOException e) {
e.printStackTrace();
}
}
if(fis!=null) {
try {
fis.close();
}catch (IOException e) {
e.printStackTrace();
}
}
}
}
}源码:
/**
* FileInputStream 从文件系统的文件中获取输入字节流。文件取决于主机系统。
* 比如读取图片等的原始字节流。如果读取字符流,考虑使用 FiLeReader。
*/
public class FileInputStream extends InputStream{
/* 文件描述符类---此处用于打开文件的句柄 */
private final FileDescriptor fd;
/* 引用文件的路径 */
private final String path;
/* 文件通道,NIO部分 */
private FileChannel channel = null;
private final Object closeLock = new Object();
private volatile boolean closed = false;
private static final ThreadLocal runningFinalize =
new ThreadLocal<>();
private static boolean isRunningFinalize() {
Boolean val;
if ((val = runningFinalize.get()) != null)
return val.booleanValue();
return false;
}
/* 通过文件路径名来创建FileInputStream */
public FileInputStream(String name) throws FileNotFoundException {
this(name != null ? new File(name) : null);
}
/* 通过文件来创建FileInputStream */
public FileInputStream(File file) throws FileNotFoundException {
String name = (file != null ? file.getPath() : null);
SecurityManager security = System.getSecurityManager();
if (security != null) {
security.checkRead(name);
}
if (name == null) {
throw new NullPointerException();
}
if (file.isInvalid()) {
throw new FileNotFoundException("Invalid file path");
}
fd = new FileDescriptor();
fd.incrementAndGetUseCount();
this.path = name;
open(name);
}
/* 通过文件描述符类来创建FileInputStream */
public FileInputStream(FileDescriptor fdObj) {
SecurityManager security = System.getSecurityManager();
if (fdObj == null) {
throw new NullPointerException();
}
if (security != null) {
security.checkRead(fdObj);
}
fd = fdObj;
path = null;
fd.incrementAndGetUseCount();
}
/* 打开文件,为了下一步读取文件内容。native方法 */
private native void open(String name) throws FileNotFoundException;
/* 从此输入流中读取一个数据字节 */
public int read() throws IOException {
Object traceContext = IoTrace.fileReadBegin(path);
int b = 0;
try {
b = read0();
} finally {
IoTrace.fileReadEnd(traceContext, b == -1 ? 0 : 1);
}
return b;
}
/* 从此输入流中读取一个数据字节。native方法 */
private native int read0() throws IOException;
/* 从此输入流中读取多个字节到byte数组中。native方法 */
private native int readBytes(byte b[], int off, int len) throws IOException;
/* 从此输入流中读取多个字节到byte数组中。 */
public int read(byte b[]) throws IOException {
Object traceContext = IoTrace.fileReadBegin(path);
int bytesRead = 0;
try {
bytesRead = readBytes(b, 0, b.length);
} finally {
IoTrace.fileReadEnd(traceContext, bytesRead == -1 ? 0 : bytesRead);
}
return bytesRead;
}
/* 从此输入流中读取最多len个字节到byte数组中。 */
public int read(byte b[], int off, int len) throws IOException {
Object traceContext = IoTrace.fileReadBegin(path);
int bytesRead = 0;
try {
bytesRead = readBytes(b, off, len);
} finally {
IoTrace.fileReadEnd(traceContext, bytesRead == -1 ? 0 : bytesRead);
}
return bytesRead;
}
public native long skip(long n) throws IOException;
/* 返回下一次对此输入流调用的方法可以不受阻塞地从此输入流读取(或跳过)的估计剩余字节数。 */
public native int available() throws IOException;
/* 关闭此文件输入流并释放与此流有关的所有系统资源。 */
public void close() throws IOException {
synchronized (closeLock) {
if (closed) {
return;
}
closed = true;
}
if (channel != null) {
fd.decrementAndGetUseCount();
channel.close();
}
int useCount = fd.decrementAndGetUseCount();
if ((useCount <= 0) || !isRunningFinalize()) {
close0();
}
}
public final FileDescriptor getFD() throws IOException {
if (fd != null) return fd;
throw new IOException();
}
/* 获取此文件输入流的唯一FileChannel对象 */
publicFileChannel getChannel() {
synchronized(this) {
if(channel == null) {
channel = FileChannelImpl.open(fd, path, true, false, this);
fd.incrementAndGetUseCount();
}
returnchannel;
}
}
privatestaticnativevoidinitIDs();
privatenativevoidclose0() throwsIOException;
static{
initIDs();
}
protected void finalize() throws IOException {
if((fd != null) && (fd != FileDescriptor.in)) {
runningFinalize.set(Boolean.TRUE);
try{
close();
} finally{
runningFinalize.set(Boolean.FALSE);
}
}
}
}
FilterInputStream
FilterInputStream被protected修饰,不能创建对象。
只能使用其子类
|
FilterInputStream |
此类中的InputStream,在构造的时候,都必须放入其它的InputStream,相当于包装的作用,包装之后,显示出来的特性各不相同。
BufferedInputStream
BufferedInputStream |
BufferedInputStream |
例如:
将FileInputStream包装起来
相当于将FileInputStream装到一个缓冲区Buffer中
(FileInput直接读取,相当于一个一个字节读取,将File放到Buffer中相当于将水滴放到桶中去)
提高了字节流读取的速度:
BufferedInputStreamin = new BufferedInputStream(new FileInputStream(“Test”));
对于BufferedInputStream和 BufferedOutputStream的代码贴(后面不再贴):
packageday7.bytestream;
importjava.io.BufferedInputStream;
importjava.io.BufferedOutputStream;
importjava.io.FileInputStream;
importjava.io.FileNotFoundException;
importjava.io.FileOutputStream;
importjava.io.IOException;
public classFileCopy3 {
public static voidmain(String[] args) {
FileInputStreamfis = null;
FileOutputStreamfos = null;
//给input和 output也创建一个缓冲区
//read和write操作就直接对它们的缓冲区进行操作
BufferedInputStreambis = null;
BufferedOutputStreambos = null;
try {
fis = newFileInputStream("E:\\安装包\\mysql-5.6.31-winx64.zip");
fos = newFileOutputStream("a.rar");
bis = newBufferedInputStream(fis);
bos = newBufferedOutputStream(fos);
// 创建一个缓冲区
// 缓冲区越大,copy的速度越快,最快速度为缓冲区大小等于copy文件大小的时候
byte[] buffer =new byte[1024*8];
System.out.println("文件正在复制,请稍后...");
longbegin = System.currentTimeMillis();
while(true) {
/*
* read方法返回的是一个int值
* 表示读入缓冲区(buffer)的字节总数
* 因为各种方面的原因,read到缓冲区中
* 的字节数不一定每次都装满了len长度。
* 如果当前源文件中不存在可以读的字节
* 的时候,read的返回值为-1。
*/
intlen = bis.read(buffer);
if(len<0){
break;
}
bos.write(buffer,0, len);
}
longend = System.currentTimeMillis();
System.out.println("文件复制完成,耗时:"+(end-begin)+"毫秒");
} catch(FileNotFoundException e) {
e.printStackTrace();
} catch(IOException e) {
e.printStackTrace();
} finally {
//关闭的顺序必须先关闭in和out的缓冲区再关闭in和out
if(bos!=null) {
try {
bos.close();
}catch (IOException e) {
e.printStackTrace();
}
}
if(bis!=null) {
try {
bis.close();
}catch (IOException e) {
e.printStackTrace();
}
}
if(fos!=null) {
try {
fos.close();
}catch (IOException e) {
e.printStackTrace();
}
}
if(fis!=null) {
try {
fis.close();
}catch (IOException e) {
e.printStackTrace();
}
}
}
}
}DataInputStream
DataInputStream(InputStream in)
使用指定的底层 InputStream 创建一个DataInputStream。
DataInputStream实现了DataInput接口
DataInputStream能以一种与机器无关(当前操作系统等)的方式,直接从地从字节输入流读取JAVA基本类型和String类型的数据,常用于网络传输等(网络传输数据要求与平台无关)
(此地贴:DataOutputStream不再贴)
import java.io.*;
public class DataStreamDemo {
public static void main(String[] args)throws Exception {
FileOutputStream fos = new FileOutputStream("xxx.data");
DataOutputStream dos = new DataOutputStream(fos);
dos.writeInt(100);
dos.writeUTF("DataOutputStream Test");
dos.close();
FileInputStream fis = new FileInputStream("xxx.data");
DataInputStream dis = new DataInputStream(fis);
System.out.println("int:" + dis.readInt());
System.out.println("UTF:" + dis.readUTF());
dis.close();
}
}运行结果:产生一个xxx.data文件(此时已经不是文本文件,此时编码为JAVA虚拟机通用格式,即UTF-8),控制台输出结果为:
int:100
UTF:DataOutputStreamTest
当要求输入输出流必须遵循平台无关时,可以使用这个类
PipedInputStream
PipedOutputStream和PipedInputStream分别是管道输出流和管道输入流。
它们的作用是让多线程可以通过管道进行线程间的通讯。在使用管道通信时,必须将PipedOutputStream和PipedInputStream配套使用。
使用管道通信时,大致的流程是:我们在线程A中向PipedOutputStream中写入数据,这些数据会自动的发送到与PipedOutputStream对应的PipedInputStream中,进而存储在PipedInputStream的缓冲中;此时,线程B通过读取PipedInputStream中的数据。就可以实现,线程A和线程B的通信。
PipedInputStream 源码分析(基于jdk1.7.40)
package java.io;
public class PipedInputStream extends InputStream {
// “管道输出流”是否关闭的标记
booleanclosedByWriter = false;
// “管道输入流”是否关闭的标记
volatileboolean closedByReader = false;
// “管道输入流”与“管道输出流”是否连接的标记
// 它在PipedOutputStream的connect()连接函数中被设置为true
booleanconnected = false;
ThreadreadSide; // 读取“管道”数据的线程
ThreadwriteSide; // 向“管道”写入数据的线程
// “管道”的默认大小
private staticfinal int DEFAULT_PIPE_SIZE = 1024;
protectedstatic final int PIPE_SIZE = DEFAULT_PIPE_SIZE;
// 缓冲区
protected bytebuffer[];
//下一个写入字节的位置。in==out代表满,说明“写入的数据”全部被读取了。
protected intin = -1;
//下一个读取字节的位置。in==out代表满,说明“写入的数据”全部被读取了。
protected intout = 0;
// 构造函数:指定与“管道输入流”关联的“管道输出流”
publicPipedInputStream(PipedOutputStream src) throws IOException {
this(src,DEFAULT_PIPE_SIZE);
}
// 构造函数:指定与“管道输入流”关联的“管道输出流”,以及“缓冲区大小”
public PipedInputStream(PipedOutputStreamsrc, int pipeSize)
throwsIOException {
initPipe(pipeSize);
connect(src);
}
// 构造函数:默认缓冲区大小是1024字节
publicPipedInputStream() {
initPipe(DEFAULT_PIPE_SIZE);
}
// 构造函数:指定缓冲区大小是pipeSize
publicPipedInputStream(int pipeSize) {
initPipe(pipeSize);
}
// 初始化“管道”:新建缓冲区大小
private voidinitPipe(int pipeSize) {
if(pipeSize <= 0) {
thrownew IllegalArgumentException("Pipe Size <= 0");
}
buffer =new byte[pipeSize];
}
// 将“管道输入流”和“管道输出流”绑定。
// 实际上,这里调用的是PipedOutputStream的connect()函数
public voidconnect(PipedOutputStream src) throws IOException {
src.connect(this);
}
// 接收int类型的数据b。
// 它只会在PipedOutputStream的write(int b)中会被调用
protectedsynchronized void receive(int b) throws IOException {
// 检查管道状态
checkStateForReceive();
// 获取“写入管道”的线程
writeSide =Thread.currentThread();
// 若“写入管道”的数据正好全部被读取完,则等待。
if (in ==out)
awaitSpace();
if (in <0) {
in = 0;
out =0;
}
// 将b保存到缓冲区
buffer[in++] = (byte)(b & 0xFF);
if (in>= buffer.length) {
in = 0;
}
}
// 接收字节数组b。
synchronizedvoid receive(byte b[], int off, int len) throws IOException {
// 检查管道状态
checkStateForReceive();
// 获取“写入管道”的线程
writeSide =Thread.currentThread();
int bytesToTransfer = len;
while(bytesToTransfer > 0) {
// 若“写入管道”的数据正好全部被读取完,则等待。
if (in== out)
awaitSpace();
intnextTransferAmount = 0;
// 如果“管道中被读取的数据,少于写入管道的数据”;
// 则设置nextTransferAmount=“buffer.length- in”
if (out< in) {
nextTransferAmount = buffer.length - in;
} elseif (in < out) { // 如果“管道中被读取的数据,大于/等于写入管道的数据”,则执行后面的操作
// 若in==-1(即管道的写入数据等于被读取数据),此时nextTransferAmount = buffer.length - in;
// 否则,nextTransferAmount= out - in;
if(in == -1) {
in = out = 0;
nextTransferAmount = buffer.length - in;
}else {
nextTransferAmount = out - in;
}
}
if(nextTransferAmount > bytesToTransfer)
nextTransferAmount = bytesToTransfer;
//assert断言的作用是,若nextTransferAmount <= 0,则终止程序。
assert(nextTransferAmount > 0);
// 将数据写入到缓冲中
System.arraycopy(b, off, buffer, in, nextTransferAmount);
bytesToTransfer -= nextTransferAmount;
off +=nextTransferAmount;
in +=nextTransferAmount;
if (in>= buffer.length) {
in= 0;
}
}
}
// 检查管道状态
private voidcheckStateForReceive() throws IOException {
if(!connected) {
thrownew IOException("Pipe not connected");
} else if(closedByWriter || closedByReader) {
thrownew IOException("Pipe closed");
} else if(readSide != null && !readSide.isAlive()) {
thrownew IOException("Read end dead");
}
}
// 等待。
// 若“写入管道”的数据正好全部被读取完(例如,管道缓冲满),则执行awaitSpace()操作;
// 它的目的是让“读取管道的线程”管道产生读取数据请求,从而才能继续的向“管道”中写入数据。
private voidawaitSpace() throws IOException {
// 如果“管道中被读取的数据,等于写入管道的数据”时,
// 则每隔1000ms检查“管道状态”,并唤醒管道操作:若有“读取管道数据线程被阻塞”,则唤醒该线程。
while (in== out) {
checkStateForReceive();
/*full: kick any waiting readers */
notifyAll();
try {
wait(1000);
} catch(InterruptedException ex) {
throw new java.io.InterruptedIOException();
}
}
}
// 当PipedOutputStream被关闭时,被调用
synchronizedvoid receivedLast() {
closedByWriter = true;
notifyAll();
}
// 从管道(的缓冲)中读取一个字节,并将其转换成int类型
publicsynchronized int read() throwsIOException {
if(!connected) {
thrownew IOException("Pipe not connected");
} else if(closedByReader) {
thrownew IOException("Pipe closed");
} else if(writeSide != null && !writeSide.isAlive()
&& !closedByWriter && (in < 0)) {
thrownew IOException("Write end dead");
}
readSide =Thread.currentThread();
int trials= 2;
while (in< 0) {
if (closedByWriter){
/*closed by writer, return EOF */
return -1;
}
if((writeSide != null) && (!writeSide.isAlive()) && (--trials< 0)) {
throw new IOException("Pipe broken");
}
/*might be a writer waiting */
notifyAll();
try {
wait(1000);
} catch(InterruptedException ex) {
throw new java.io.InterruptedIOException();
}
}
int ret =buffer[out++] & 0xFF;
if (out>= buffer.length) {
out =0;
}
if (in ==out) {
/* nowempty */
in =-1;
}
return ret;
}
// 从管道(的缓冲)中读取数据,并将其存入到数组b中
publicsynchronized int read(byte b[], int off, int len) throws IOException {
if (b ==null) {
thrownew NullPointerException();
} else if(off < 0 || len < 0 || len > b.length - off) {
thrownew IndexOutOfBoundsException();
} else if(len == 0) {
return0;
}
/* possiblywait on the first character */
int c =read();
if (c <0) {
return-1;
}
b[off] =(byte) c;
int rlen =1;
while ((in>= 0) && (len > 1)) {
intavailable;
if (in> out) {
available = Math.min((buffer.length - out), (in - out));
} else{
available = buffer.length - out;
}
// Abyte is read beforehand outside the loop
if(available > (len - 1)) {
available = len - 1;
}
System.arraycopy(buffer, out, b, off + rlen, available);
out +=available;
rlen += available;
len -=available;
if (out>= buffer.length) {
out= 0;
}
if (in== out) {
/*now empty */
in= -1;
}
}
returnrlen;
}
// 返回不受阻塞地从此输入流中读取的字节数。
publicsynchronized int available() throws IOException {
if(in <0)
return0;
else if(in== out)
returnbuffer.length;
else if (in> out)
return in - out;
else
returnin + buffer.length - out;
}
// 关闭管道输入流
public voidclose() throws IOException {
closedByReader = true;
synchronized (this) {
in =-1;
}
}
}接收者线程
packageio;
importjava.io.IOException;
importjava.io.PipedInputStream;
@SuppressWarnings("all")
/**
* 接收者线程
*/
public classReceiver extends Thread {
//管道输入流对象。
//它和“管道输出流(PipedOutputStream)”对象绑定,
//从而可以接收“管道输出流”的数据,再让用户读取。
privatePipedInputStreamin = newPipedInputStream();
//获得“管道输入流”对象
publicPipedInputStream getInputStream(){
returnin;
}
@Override
public voidrun(){
readMessageOnce() ;
//readMessageContinued();
}
//从“管道输入流”中读取1次数据
public voidreadMessageOnce(){
//虽然buf的大小是2048个字节,但最多只会从“管道输入流”中读取1024个字节。
//因为,“管道输入流”的缓冲区大小默认只有1024个字节。
byte[]buf = newbyte[2048];
try {
intlen = in.read(buf);
System.out.println(newString(buf,0,len));
in.close();
} catch(IOExceptione) {
e.printStackTrace();
}
}
//从“管道输入流”读取>1024个字节时,就停止读取
public voidreadMessageContinued() {
int total=0;
while(true) {
byte[]buf = newbyte[1024];
try {
intlen = in.read(buf);
total +=len;
System.out.println(newString(buf,0,len));
//若读取的字节总数>1024,则退出循环。
if (total> 1024)
break;
} catch(IOExceptione) {
e.printStackTrace();
}
}
try {
in.close();
} catch(IOExceptione) {
e.printStackTrace();
}
}
}发送者线程
packageio;
importjava.io.IOException;
importjava.io.PipedOutputStream;
@SuppressWarnings("all")
/**
* 发送者线程
*/
public classSender extends Thread {
//管道输出流对象。
//它和“管道输入流(PipedInputStream)”对象绑定,
//从而可以将数据发送给“管道输入流”的数据,然后用户可以从“管道输入流”读取数据。
privatePipedOutputStreamout = newPipedOutputStream();
//获得“管道输出流”对象
publicPipedOutputStream getOutputStream(){
returnout;
}
@Override
public voidrun(){
writeShortMessage();
//writeLongMessage();
}
//向“管道输出流”中写入一则较简短的消息:"thisis a short message"
private voidwriteShortMessage() {
String strInfo = "thisis a short message" ;
try {
out.write(strInfo.getBytes());
out.close();
} catch(IOExceptione) {
e.printStackTrace();
}
}
// 向“管道输出流”中写入一则较长的消息
private voidwriteLongMessage() {
StringBuilder sb = newStringBuilder();
//通过for循环写入1020个字节
for (inti=0;i<102; i++)
sb.append("0123456789");
//再写入26个字节。
sb.append("abcdefghijklmnopqrstuvwxyz");
//str的总长度是1020+26=1046个字节
String str = sb.toString();
try {
//将1046个字节写入到“管道输出流”中
out.write(str.getBytes());
out.close();
} catch(IOExceptione) {
e.printStackTrace();
}
}
}管道输入流和管道输出流的交互程序
package io;
importjava.io.PipedInputStream;
importjava.io.PipedOutputStream;
importjava.io.IOException;
@SuppressWarnings("all")
/**
* 管道输入流和管道输出流的交互程序
*/
public class PipedStreamTest {
public static void main(String[] args) {
Sender t1 = new Sender();
Receiver t2 = newReceiver();
PipedOutputStream out =t1.getOutputStream();
PipedInputStream in = t2.getInputStream();
try {
//管道连接。下面2句话的本质是一样。
//out.connect(in);
in.connect(out);
/**
* Thread类的START方法:
* 使该线程开始执行;Java虚拟机调用该线程的 run方法。
* 结果是两个线程并发地运行;当前线程(从调用返回给 start方法)和另一个线程 (执行其 run方法)。
* 多次启动一个线程是非法的。特别是当线程已经结束执行后,不能再重新启动。
*/
t1.start();
t2.start();
} catch (IOExceptione) {
e.printStackTrace();
}
}
}SequenceInputStream
构造方法摘要 |
|
SequenceInputStream |
|
|
|
构造方法摘要 |
|
SequenceInputStream |
|
结果: a.txt aaa b.txt bbb ab.txt aaabbb |
|
ObjectInputStream
ObjectInputStream确保从流创建的图形中所有对象的类型与Java虚拟机中显示的类相匹配。使用标准机制按需加载类。
只有支持java.io.Serializable或java.io.Externalizable接口的对象才能从流读取。
OutputStream
ByteArrayOutputStream
ByteArrayOutputStream把内存中的数据读到字节数组中
还是相对于程序来讲的: 从 程序(内存中的数据) à字节数组
ByteArrayOutputStream把内存中的数据读到字节数组中,而ByteArrayInputStream又把字节数组中的字节以流的形式读出,实现了对同一个字节数组的操作.
此类实现了一个输出流,其中的数据被写入一个byte数组。缓冲区会随着数据的不断写入而自动增长。可使用toByteArray()和toString()获取数据。
关闭ByteArrayOutputStream无效。此类中的方法在关闭此流之后仍可以被调用,而不会产生任何IOException。
ByteArrayOutputStream是OutputStream的直接子类,它实现了一个输出流,其中的数据被写入到一个byte数组。缓冲区会随着数据的不断写入而自动增长。
从byte数组中读取内容转化为输入流(从字节数组中读取byte[] arr)
个人理解:ByteArrayOutputStream是用来缓存数据的,和我们通常理解的outputStream不同,通常的outputStream是从程序写到外部。这里的ByteArrayOutputStream更像是一个缓冲区,通过InputStream将外部的文件读取到程序中之后,再将数据通过一个个字节的方式读到ByteArrayOutputStream中去,再通过调用该对象中的toString方法或者toByteArray的方法返回字符串或者字符数组的形式获取到其中的数据。
所以这里的ByteArrayOutputStream常用于存储数据以用于一次写入。
构造方法摘要 |
|
ByteArrayOutputStream |
|
ByteArrayOutputStream |
|
public class ByteArrayOutputStreamDemo {
public static void main(String[] args) throws Exception {
FileInputStream fis = new FileInputStream("test");
BufferedInputStream bis =new BufferedInputStream(fis);
ByteArrayOutputStream baos =new ByteArrayOutputStream();
int c = bis.read(); // 读取bis中的下一个字节
while(c != -1) {
baos.write(c);
c = bis.read();
}
bis.close();
byte[]arr = baos.toByteArray();
String s = new String(arr);
System.out.println(s);
}
}
FileOutputStream
三个核心方法,也就是Override(重写)了抽象类OutputStream的write方法。
1.void write(int b)方法,即:
public void write(intb) throws IOException
代码实现中很简单,一个try中调用本地native的write()方法,直接 将指定的字节b写入文件输出流。IoTrace.fileReadEnd()的意思和上面 FileInputStream意思一致。
/* 将指定的字节b写入到该文件输入流 */
public void write(int b) throws IOException {
Object traceContext = IoTrace.fileWriteBegin(path);
int bytesWritten = 0;
try {
write(b, append);
bytesWritten = 1;
} finally {
IoTrace.fileWriteEnd(traceContext, bytesWritten);
}
}2.void write(byteb[]) 方法,即:
public void write(byteb[]) throws IOException
代码实现也是比较简单的,也是一个try中调用本地native的writeBytes()方法,直接将指定的字节数组写入该文件输入流。
/* 将指定的字节数组b写入该文件输入流 */
public void write(byte b[]) throws IOException {
Object traceContext = IoTrace.fileWriteBegin(path);
int bytesWritten = 0;
try {
writeBytes(b, 0, b.length, append);
bytesWritten = b.length;
} finally {
IoTrace.fileWriteEnd(traceContext, bytesWritten);
}
}3.voidwrite(byte b[], int off, int len) 方法,即:
publicvoid write(byte b[], int off, int len) throws IOException
代码实现和 void write(byte b[]) 方法 一样,直接将指定的字节数组写入该文件输入流。
/* 将指定len长度的字节数组b写入该文件输入流 */
public void write(byte b[], int off, int len) throws IOException {
Object traceContext = IoTrace.fileWriteBegin(path);
int bytesWritten = 0;
try {
writeBytes(b, off, len, append);
bytesWritten = len;
} finally {
IoTrace.fileWriteEnd(traceContext, bytesWritten);
}
}值得一提的native方法:
上面核心方法中为什么实现简单,因为工作量都在native方法里面,即JVM里面实现了。native倒是不少一一列举吧:
nativevoid open(String name) // 打开文件,为了下一步读取文件内容
native void write(int b, boolean append) //直接将指定的字节b写入文件输出流
native native void writeBytes(byte b[], int off, int len, booleanappend) //直接将指定的字节数组写入该文件输入流。
native void close0() // 关闭该文件输入流及涉及的资源,比如说如果该文件输入流的FileChannel对被获取后,需要对FileChannel进行close。
源码:
/**
* 文件输入流是用于将数据写入文件或者文件描述符类
* 比如写入图片等的原始字节流。如果写入字符流,考虑使用 FiLeWriter。
*/
publicclassSFileOutputStream extendsOutputStream{
/* 文件描述符类---此处用于打开文件的句柄 */
private final FileDescriptor fd;
/* 引用文件的路径 */
private final String path;
/* 如果为 true,则将字节写入文件末尾处,而不是写入文件开始处 */
private final boolean append;
/* 关联的FileChannel类,懒加载 */
private FileChannel channel;
private final Object closeLock = new Object();
private volatile boolean closed = false;
private static final ThreadLocal runningFinalize =
new ThreadLocal<>();
private static boolean isRunningFinalize() {
Boolean val;
if ((val = runningFinalize.get()) != null)
return val.booleanValue();
return false;
}
/* 通过文件名创建文件输入流 */
public FileOutputStream(String name) throws FileNotFoundException {
this(name != null ? new File(name) : null, false);
}
/* 通过文件名创建文件输入流,并确定文件写入起始处模式 */
public FileOutputStream(String name, boolean append)
throws FileNotFoundException
{
this(name != null ? new File(name) : null, append);
}
/* 通过文件创建文件输入流,默认写入文件的开始处 */
public FileOutputStream(File file) throws FileNotFoundException {
this(file, false);
}
/* 通过文件创建文件输入流,并确定文件写入起始处 */
public FileOutputStream(File file, boolean append)
throws FileNotFoundException
{
String name = (file != null ? file.getPath() : null);
SecurityManager security = System.getSecurityManager();
if (security != null) {
security.checkWrite(name);
}
if (name == null) {
throw new NullPointerException();
}
if (file.isInvalid()) {
throw new FileNotFoundException("Invalid file path");
}
this.fd = new FileDescriptor();
this.append = append;
this.path = name;
fd.incrementAndGetUseCount();
open(name, append);
}
/* 通过文件描述符类创建文件输入流 */
public FileOutputStream(FileDescriptor fdObj) {
SecurityManager security = System.getSecurityManager();
if (fdObj == null) {
throw new NullPointerException();
}
if (security != null) {
security.checkWrite(fdObj);
}
this.fd = fdObj;
this.path = null;
this.append = false;
fd.incrementAndGetUseCount();
}
/* 打开文件,并确定文件写入起始处模式 */
private native void open(String name, boolean append)
throws FileNotFoundException;
/* 将指定的字节b写入到该文件输入流,并指定文件写入起始处模式 */
private native void write(int b, boolean append) throws IOException;
/* 将指定的字节b写入到该文件输入流 */
public void write(int b) throws IOException {
Object traceContext = IoTrace.fileWriteBegin(path);
int bytesWritten = 0;
try {
write(b, append);
bytesWritten = 1;
} finally {
IoTrace.fileWriteEnd(traceContext, bytesWritten);
}
}
/* 将指定的字节数组写入该文件输入流,并指定文件写入起始处模式 */
private native void writeBytes(byte b[], int off, int len, boolean append)
throws IOException;
/* 将指定的字节数组b写入该文件输入流 */
public void write(byte b[]) throws IOException {
Object traceContext = IoTrace.fileWriteBegin(path);
int bytesWritten = 0;
try {
writeBytes(b, 0, b.length, append);
bytesWritten = b.length;
} finally {
IoTrace.fileWriteEnd(traceContext, bytesWritten);
}
}
/* 将指定len长度的字节数组b写入该文件输入流 */
public void write(byte b[], int off, int len) throws IOException {
Object traceContext = IoTrace.fileWriteBegin(path);
int bytesWritten = 0;
try {
writeBytes(b, off, len, append);
bytesWritten = len;
} finally {
IoTrace.fileWriteEnd(traceContext, bytesWritten);
}
}
/* 关闭此文件输出流并释放与此流有关的所有系统资源 */
publicvoidclose() throwsIOException {
synchronized(closeLock) {
if(closed) {
return;
}
closed = true;
}
if(channel != null) {
fd.decrementAndGetUseCount();
channel.close();
}
intuseCount = fd.decrementAndGetUseCount();
if((useCount <= 0) || !isRunningFinalize()) {
close0();
}
}
public final FileDescriptor getFD() throws IOException {
if(fd != null) returnfd;
thrownewIOException();
}
publicFile Channel getChannel() {
synchronized(this) {
if(channel == null) {
channel = FileChannelImpl.open(fd, path, false, true, append, this);
fd.incrementAndGetUseCount();
}
returnchannel;
}
}
protected void finalize() throws IOException {
if(fd != null) {
if(fd == FileDescriptor.out || fd == FileDescriptor.err) {
flush();
} else{
runningFinalize.set(Boolean.TRUE);
try{
close();
} finally{
runningFinalize.set(Boolean.FALSE);
}
}
}
}
private native void close0() throws IOException;
private static native void initIDs();
static{
initIDs();
}
}
FilterOutputStream
FilterOutputStream未被protected修饰可以创建对象(这里和FilterInputStream)形成对比。
构造方法摘要 |
|
FilterOutputStream |
|
此类中的OutputStream,在构造的时候,都必须放入其它的OutputStream,相当于包装的作用,包装之后,显示出来的特性各不相同。
BufferedOutputStream
例如:
将FileInputStream包装起来
相当于将FileInputStream装到一个缓冲区Buffer中
(FileInput直接读取,相当于一个一个字节读取,将File放到Buffer中相当于将水滴放到桶中去)
提高了字节流读取的速度:
BufferedOutputStreamin = new BufferedOutputStream(new FileOutputStream(“Test”));
PrintStream
PrintStream 是打印输出流,它继承于FilterOutputStream。
PrintStream 是用来装饰其它输出流。它能为其他输出流添加了功能,使它们能够方便地打印各种数据值表示形式。
与其他输出流不同,PrintStream永远不会抛出 IOException;它产生的IOException会被自身的函数所捕获并设置错误标记, 用户可以通过checkError() 返回错误标记,从而查看PrintStream内部是否产生了IOException。
另外,PrintStream 提供了自动flush 和 字符集设置功能。所谓自动flush,就是往PrintStream写入的数据会立刻调用flush()函数。
关键字段:
boolean autoFlush = false; // 是否自动flush
boolean trouble = false; // 执行过程中是否产生异常
Formatter formatter; // 用于格式化的对象
BufferedWriter textOut; // 用于包装OutputStreamWriter的缓冲字符输出流
OutputStreamWriter charOut; // 用于包装当前PrintStream、代表其字符输出流的ows引用、进而用BufferedWriter包装 1. 是那个私有的构造方法:
PrintStream(BooleanautoFlush,OutputStream out)、他的作用就是调用父类FilterInputStream的构造方法将传入的底层的OutPutStream实现类赋给FilterInputStream中对底层字节输入流的引用out、使得PrintStream对传入流的包装对用户透明化、同时将第一个参数autoFlush的值传递给PrintStream自身的全局变量autoFlush、用来标识此流是否具有自动刷新功能。
2. 是那个私有的初始化方法:
init(OutputStreamWriter osw)、这个方法是做了两层包装、
(1):将自身、也就是当前的PrintStream按照默认或者指定的编码转换成OutputStreamWriter(这个类是将字节输出流转换成字符输出流、转换的时候可以使用指定的编码转换)
(2):因为OutputStreamWriter读取字节的效率比较低、所以用BufferedWriter(字符缓冲输出流)将OutputStreamWriter再包装一层(提高效率)。上面两个关键点就决定了PrintStream的功能与特点、可以自动刷新、可以指定输出时的编码(本质是通过OutputStreamWriter转换时指定的)可以打印各种java类型的数据(本质也是将字节转换成字符之后、借用BufferedWriter写入到输出流中)、所以:我们可以将PrintStream中的方法分成两类、一类是打印字节的方法write(byte b)、writer(byte[] b, int off, int len)这两个方法是直接调用传入的底层字节输出流来实现、其他分成一类、这一类是将数据转换成字符数组、字符串之后借用BufferedWriter的包装输出到底层字节输出流中。
代码示例:
package io;
importjava.io.PrintStream;
public class PrintStreamDemo {
public static void main(String[] args) throws Exception{
PrintStream ps =new PrintStream("test");
ps.print(true+"\n");
ps.println("String hello");
Person p = new Person();
ps.println(p);
}
}
class Person {
private int id = 1633140111;
private Stringno = "123456789";
public int getId() {
returnid;
}
public void setId(intid) {
this.id =id;
}
public String getNo() {
returnno;
}
public void setNo(String no) {
this.no =no;
}
}
输出:
true
String hello
io.Person@70dea4e // person的地址
DataOutputStream
DataOutputStream实现了DataInput/DataOutput接口
DataOutputStream能以一种与机器无关(当前操作系统等)的方式,直接从地从字节输出流输出JAVA基本类型和String类型的数据,常用于网络传输等(网络传输数据要求与平台无关)
当要求输入输出流必须遵循平台无关时,可以使用这个类
PipedOutputStream
PipedOutputStream和PipedInputStream分别是管道输出流和管道输入流。
它们的作用是让多线程可以通过管道进行线程间的通讯。在使用管道通信时,必须将PipedOutputStream和PipedInputStream配套使用。
使用管道通信时,大致的流程是:我们在线程A中向PipedOutputStream中写入数据,这些数据会自动的发送到与PipedOutputStream对应的PipedInputStream中,进而存储在PipedInputStream的缓冲中;此时,线程B通过读取PipedInputStream中的数据。就可以实现,线程A和线程B的通信。
PipedOutputStream 源码分析(基于jdk1.7.40)
package java.io;
import java.io.*;
public class PipedOutputStream extends OutputStream {
// 与PipedOutputStream通信的PipedInputStream对象
private PipedInputStream sink;
// 构造函数,指定配对的PipedInputStream
publicPipedOutputStream(PipedInputStream snk) throws IOException {
connect(snk);
}
// 构造函数
public PipedOutputStream() {
}
// 将“管道输出流” 和 “管道输入流”连接。
public synchronized voidconnect(PipedInputStream snk) throws IOException {
if (snk == null) {
throw newNullPointerException();
} else if (sink != null ||snk.connected) {
throw newIOException("Already connected");
}
// 设置“管道输入流”
sink = snk;
// 初始化“管道输入流”的读写位置
// int是PipedInputStream中定义的,代表“管道输入流”的读写位置
snk.in = -1;
// 初始化“管道输出流”的读写位置。
// out是PipedInputStream中定义的,代表“管道输出流”的读写位置
snk.out = 0;
// 设置“管道输入流”和“管道输出流”为已连接状态
// connected是PipedInputStream中定义的,用于表示“管道输入流与管道输出流”是否已经连接
snk.connected = true;
}
// 将int类型b写入“管道输出流”中。
// 将b写入“管道输出流”之后,它会将b传输给“管道输入流”
public void write(int b) throws IOException {
if (sink == null) {
throw newIOException("Pipe not connected");
}
sink.receive(b);
}
// 将字节数组b写入“管道输出流”中。
// 将数组b写入“管道输出流”之后,它会将其传输给“管道输入流”
public void write(byte b[], intoff, int len) throws IOException {
if (sink == null) {
throw newIOException("Pipe not connected");
} else if (b == null) {
throw newNullPointerException();
} else if ((off < 0) ||(off > b.length) || (len < 0) ||
((off + len) >b.length) || ((off + len) < 0)) {
throw new IndexOutOfBoundsException();
} else if (len == 0) {
return;
}
// “管道输入流”接收数据
sink.receive(b, off, len);
}
// 清空“管道输出流”。
// 这里会调用“管道输入流”的notifyAll();
// 目的是让“管道输入流”放弃对当前资源的占有,让其它的等待线程(等待读取管道输出流的线程)读取“管道输出流”的值。
public synchronized void flush()throws IOException {
if (sink != null) {
synchronized (sink) {
sink.notifyAll();
}
}
}
// 关闭“管道输出流”。
// 关闭之后,会调用receivedLast()通知“管道输入流”它已经关闭。
public void close() throws IOException {
if (sink != null) {
sink.receivedLast();
}
}
}ObjectOutputStream
ObjectOutputStream确保从流创建的图形中所有对象的类型与Java虚拟机中显示的类相匹配。使用标准机制按需加载类。
只有支持java.io.Serializable或java.io.Externalizable接口的对象才能从流读取。
package io;
importjava.io.FileNotFoundException;
importjava.io.FileOutputStream;
importjava.io.IOException;
importjava.io.ObjectOutputStream;
importjava.io.Serializable;
public class Test{
public static void main(String[] args) {
ObjectOutputStream objectOutputStream =null;
try {
objectOutputStream = new ObjectOutputStream(new FileOutputStream("C:\\Users\\mzy\\Desktop\\a"));
User user = new User();
user.setNum(2);
objectOutputStream.writeObject(user);
} catch (FileNotFoundExceptione) {
e.printStackTrace();
} catch (IOExceptione) {
e.printStackTrace();
} finally {
if(objectOutputStream !=null){
try {
objectOutputStream.close();
} catch (IOExceptione) {
e.printStackTrace();
}
}
}
}
}
class User implements Serializable{
private static final long serialVersionUID = -8987587467273881932L;
private int num;
public int getNum() {
returnnum;
}
public void setNum(intnum) {
this.num =num;
}
@Override
public String toString() {
return"User [num=" + num +"]";
}
}
转载自(或参考于)
rcoder的博客 CSDN
http://blog.csdn.net/rcoder/article/details/6118313
hutongling的博客 CSDN
http://blog.csdn.net/hutongling/article/details/69944517
一只猫的旅行的博客 博客园
https://www.baidu.com/link?url=4EdU6TdwoHYg8oGDTLWJpUu_NI2BTl8qME6X-tAai1Irxef4UZPkAzmYufR4AIz3EIT4aItXUddSoHKDLPXed_&wd=&eqid=cdf5f8230000c420000000055a38d2b1
别先生的博客 博客园
https://www.cnblogs.com/biehongli/p/6074713.html
简单爱_wxg的博客博客园
https://www.cnblogs.com/wxgblogs/p/5647832.html
caixiexin的博客 CSDN
http://blog.csdn.net/caixiexin/article/details/6719670
skywang12345的博客 博客园
https://www.cnblogs.com/skywang12345/p/io_16.html
AlienStar的博客 CSDN
http://blog.csdn.net/crave_shy/article/details/16991983
xuefeng1009的博客 CSDN
http://blog.csdn.net/xuefeng1009/article/details/6955707
skywang12345的博客 博客园
https://www.cnblogs.com/skywang12345/p/io_04.html