Azkaban使用
https://azkaban.github.io/azkaban/docs/latest/#how-to
创建一个流程:
一个流程是一个依赖其他job的job。其他依赖项经常会运行在这个流程job之前。
1 #this is flow bar.job
2 type=command
3 dependencies=test
4 command=echo bar
这个job依赖于之前的test.job
在Azkaban中,type值得是运行的类型,command指的是一条Linux命令,同时Azkaban还支持python,java等直接运行,也就可以是hadoop的shell。
一个流程也可以作为一个节点嵌入到其他job文件中,形成嵌入流
type=flow
flow.name=barAzkaban任务失败重试及重试间隔命令
在.job文件中,添加如下命令:
retries=12
retry.backoff=300000 #代表重试间隔时间------------------------------------------------------------------------------------------------------
一、概述
原生的 Azkaban 支持的plugin类型有以下这些:
- command:Linux shell命令行任务
- gobblin:通用数据采集工具
- hadoopJava:运行hadoopMR任务
- java:原生java任务
- hive:支持执行hiveSQL
- pig:pig脚本任务
- spark:spark任务
- hdfsToTeradata:把数据从hdfs导入Teradata
- teradataToHdfs:把数据从Teradata导入hdfs
其中最简单而且最常用的是command类型,我们在上一篇文章中已经描述了如何编写一个command的job任务。如果使用command类型,效果其实跟在本地执行Linux shell命令一样,这样的话,还不如把shell放到crontable 中运行。所以我们把重点放到Azkaban支持的比较常用的四种类型:java、hadoopJava、hive、spark
二、java类型
1、代码编写:MyJavaJob.java
package com.dataeye.java;
public class MyJavaJob {
public static void main(String[] args) {
System.out.println("#################################");
System.out.println("#### MyJavaJob class exec... ###");
System.out.println("#################################");
}
}
2、打包成jar文件:使用maven或者eclipse导出为jar文件
3、编写job文件:java.job
type=javaprocess
classpath=./lib/*,${azkaban.home}/lib/*
java.class=com.dataeye.java.MyJavaJob
4、组成一个完整的运行包
新建一个目录,在该目录下创建一个lib文件夹,把第二步打包的jar文件放到这里,把job文件放到和lib文件夹同一级的目录下,如下所示:
完整的运行包
5、打包成zip文件
把lib目录和job文件打包成zip文件,如下的java.zip:
zip文件
6、提交运行,过程跟之前文章介绍的步骤一样,不再详述,执行结果如下:
执行结果
从输出日志可以看出,代码已经正常执行。
以上是java类型的任务编写和执行的过程。接下来介绍其他任务编写的时候,只会介绍代码的编写和job的编写,其他过程与上面的一致。
三、hadoopJava类型
1、数据准备
以下内容是运行wordcount任务时需要的输入文件input.txt:
1 Ross male 33 3674
2 Julie male 42 2019
3 Gloria female 45 3567
4 Carol female 36 2813
5 Malcolm male 42 2856
6 Joan female 22 2235
7 Niki female 27 3682
8 Betty female 20 3001
9 Linda male 21 2511
10 Whitney male 35 3075
11 Lily male 27 3645
12 Fred female 39 2202
13 Gary male 28 3925
14 William female 38 2056
15 Charles male 48 2981
16 Michael male 25 2606
17 Karl female 32 2260
18 Barbara male 39 2743
19 Elizabeth female 26 2726
20 Helen female 47 2457
21 Katharine male 45 3638
22 Lee female 43 3050
23 Ann male 35 2874
24 Diana male 37 3929
25 Fiona female 45 2955
26 Bob female 21 3382
27 John male 48 3677
28 Thomas female 22 2784
29 Dean male 38 2266
30 Paul female 31 2679
把input.txt文件拷贝到hdfs的 /data/yann/input 目录下
2、代码准备:
package azkaban.jobtype.examples.java;
import azkaban.jobtype.javautils.AbstractHadoopJob;
import azkaban.utils.Props;
import java.io.IOException;
import java.util.Iterator;
import java.util.StringTokenizer;
import org.apache.hadoop.fs.FileSystem;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.io.IntWritable;
import org.apache.hadoop.io.LongWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapred.FileInputFormat;
import org.apache.hadoop.mapred.FileOutputFormat;
import org.apache.hadoop.mapred.JobConf;
import org.apache.hadoop.mapred.MapReduceBase;
import org.apache.hadoop.mapred.Mapper;
import org.apache.hadoop.mapred.OutputCollector;
import org.apache.hadoop.mapred.Reducer;
import org.apache.hadoop.mapred.Reporter;
import org.apache.hadoop.mapred.TextInputFormat;
import org.apache.hadoop.mapred.TextOutputFormat;
import org.apache.log4j.Logger;
public class WordCount extends AbstractHadoopJob
{
private static final Logger logger = Logger.getLogger(WordCount.class);
private final String inputPath;
private final String outputPath;
private boolean forceOutputOverrite;
public WordCount(String name, Props props)
{
super(name, props);
this.inputPath = props.getString("input.path");
this.outputPath = props.getString("output.path");
this.forceOutputOverrite = props.getBoolean("force.output.overwrite", false);
}
public void run()
throws Exception
{
logger.info(String.format("Starting %s", new Object[] { getClass().getSimpleName() }));
JobConf jobconf = getJobConf();
jobconf.setJarByClass(WordCount.class);
jobconf.setOutputKeyClass(Text.class);
jobconf.setOutputValueClass(IntWritable.class);
jobconf.setMapperClass(Map.class);
jobconf.setReducerClass(Reduce.class);
jobconf.setInputFormat(TextInputFormat.class);
jobconf.setOutputFormat(TextOutputFormat.class);
FileInputFormat.addInputPath(jobconf, new Path(this.inputPath));
FileOutputFormat.setOutputPath(jobconf, new Path(this.outputPath));
if (this.forceOutputOverrite)
{
FileSystem fs = FileOutputFormat.getOutputPath(jobconf).getFileSystem(jobconf);
fs.delete(FileOutputFormat.getOutputPath(jobconf), true);
}
super.run();
}
public static class Map extends MapReduceBase
implements Mapper
{
private static final IntWritable one = new IntWritable(1);
private Text word = new Text();
private long numRecords = 0L;
public void map(LongWritable key, Text value, OutputCollector output, Reporter reporter) throws IOException
{
String line = value.toString();
StringTokenizer tokenizer = new StringTokenizer(line);
while (tokenizer.hasMoreTokens()) {
this.word.set(tokenizer.nextToken());
output.collect(this.word, one);
reporter.incrCounter(Counters.INPUT_WORDS, 1L);
}
if (++this.numRecords % 100L == 0L)
reporter.setStatus("Finished processing " + this.numRecords + " records " + "from the input file");
}
static enum Counters
{
INPUT_WORDS;
}
}
public static class Reduce extends MapReduceBase
implements Reducer
{
public void reduce(Text key, Iterator values, OutputCollector output, Reporter reporter)
throws IOException
{
int sum = 0;
while (values.hasNext()) {
sum += ((IntWritable)values.next()).get();
}
output.collect(key, new IntWritable(sum));
}
}
}
3、编写job文件
wordcount.job文件内容如下:
type=hadoopJava
job.extend=false
job.class=azkaban.jobtype.examples.java.WordCount
classpath=./lib/*,${azkaban.home}/lib/*
force.output.overwrite=true
input.path=/data/yann/input
output.path=/data/yann/output
这样hadoopJava类型的任务已经完成,打包提交到Azkaban中执行即可
四、hive类型
1、编写 hive.sql文件
use azkaban;
INSERT OVERWRITE TABLE
user_table1 PARTITION (day_p='2017-02-08')
SELECT appid,uid,country,province,city
FROM user_table0 where adType=1;
以上是标准的hive的sql脚本,首先切换到azkaban数据库,然后把user_table0 的数据插入到user_table1 表的指定day_p分区。需要先准备好 user_table0 和 user_table1 表结构和数据。
编写完成后,把文件放入 res 文件夹中。
2、编写hive.job文件
type=hive
user.to.proxy=azkaban
classpath=./lib/*,${azkaban.home}/lib/*
azk.hive.action=execute.query
hive.script=res/hive.sql
关键的参数是 hive.script,该参数指定使用的sql脚本在 res目录下的hive.sql文件
五、spark类型
spark任务有两种运行方式,一种是command类型,另一种是spark类型
首先准备好spark任务的代码
package com.dataeye.template.spark
import org.apache.spark.{SparkConf, SparkContext}
import org.apache.spark.sql.{SQLContext}
object WordCount {
def main(args: Array[String]) {
if (args.length < 1) {
System.err.println("Usage:WordCount ")
System.exit(1)
}
System.out.println("get first param ==> " + args(0))
System.out.println("get second param ==> " + args(1))
/** spark 2.0的方式
* val spark = SparkSession.builder().appName("WordCount").getOrCreate()
*/
val sc = new SparkContext(new SparkConf().setAppName("WordCount"))
val spark = new SQLContext(sc)
val file = spark.sparkContext.textFile(args(0))
val wordCounts = file.flatMap(line => line.split(" ")).map(word => (word, 1)).reduceByKey(_ + _)
// 数据collect 到driver端打印
wordCounts.collect().foreach(println _)
}
}
然后准备数据,数据就使用前面hadoopJava中的数据即可。
最后打包成jar文件:spark-template-1.0-SNAPSHOT.jar
1、command类型
command类型的配置方式比较简单,spark.job文件如下:
type=command
command=${spark.home}/bin/spark-submit --master yarn-cluster --class com.dataeye.template.spark.WordCount lib/spark-template-1.0-SNAPSHOT.jar hdfs://de-hdfs/data/yann/info.txt paramtest
2、spark类型
type=spark
master=yarn-cluster
execution-jar=lib/spark-template-1.0-SNAPSHOT.jar
class=com.dataeye.template.spark.WordCount
params=hdfs://de-hdfs/data/yann/info.txt paramtest
以上就是Azkaban支持的几种常用的任务类型。
------------------------------------------------------------------------------------------------------------------------------------------------------
Azkaban安装部署
准备工作
本次安装目录为/usr/local/azkaban
Azkaban Web服务器
azkaban-web-server-2.5.0.tar.gz
Azkaban执行服务器
azkaban-executor-server-2.5.0.tar.gz
Azkaban 的数据库文件
azkaban-sql-script-2.5.0.tar.gz
MySQL
为Azkaban创建一个mysql库:库名azkaban,用户名azkaban,密码azkaban
1)为Azkaban创建一个数据库:
# Exampledatabase creation command, although the db name doesn't need to be 'azkaban'
mysql> CREATEDATABASE azkaban;
2) 为Azkaban创建一个数据库用户:
# Exampledatabase creation command. The user name doesn't need to be 'azkaban'
mysql> CREATEUSER 'username'@'%' IDENTIFIED BY 'password';
3) 为用户赋予Azkaban数据库的增删查改的权限:
# Replace db,username with the ones created by the previous steps.
mysql> GRANT ALLON
安装
将安装文件上传到集群,最好上传到安装 hive、sqoop的机器上,方便命令的执行
新建azkaban目录,用于存放azkaban运行程序
azkaban web服务器安装
解压azkaban-web-server-2.5.0.tar.gz
命令: tar –zxvf azkaban-web-server-2.5.0.tar.gz
azkaban 执行服器安装
解压azkaban-executor-server-2.5.0.tar.gz
命令:tar –zxvf azkaban-executor-server-2.5.0.tar.gz
azkaban脚本导入
解压: azkaban-sql-script-2.5.0.tar.gz
命令:tar –zxvf azkaban-sql-script-2.5.0.tar.gz
将解压后的mysql 脚本,导入到mysql中:
进入mysql
mysql> create database azkaban;
mysql> use azkaban;
Database changed
mysql> source /usr/local/azkaban/azkaban-2.5.0/create-all-sql-2.5.0.sql;
创建SSL配置
参考地址: http://docs.codehaus.org/display/JETTY/How+to+configure+SSL
命令: keytool -keystore keystore -alias jetty -genkey -keyalg RSA
运行此命令后,会提示输入当前生成 keystor的密码及相应信息,输入的密码请劳记,信息如下:
输入keystore密码: 本次安装输入的密码为123456
再次输入新密码:
您的名字与姓氏是什么?
[Unknown]:
您的组织单位名称是什么?
[Unknown]:
您的组织名称是什么?
[Unknown]:
您所在的城市或区域名称是什么?
[Unknown]:
您所在的州或省份名称是什么?
[Unknown]:
该单位的两字母国家代码是什么
[Unknown]: CN
CN=Unknown, OU=Unknown, O=Unknown,L=Unknown, ST=Unknown, C=CN 正确吗?
[否]: y
输入
(如果和 keystore 密码相同,按回车):
再次输入新密码:
完成上述工作后,将在当前目录生成 keystore 证书文件,将keystore 考贝到 azkaban web服务器根目录中.如:cp keystore azkaban-web-2.5.0
配置文件
注:先配置好服务器节点上的时区
1、先生成时区配置文件Asia/Shanghai,用交互式命令 tzselect 即可
2、拷贝该时区文件,覆盖系统本地时区配置
cp /usr/share/zoneinfo/Asia/Shanghai etc/localtime /
azkaban web服务器配置
进入azkaban web服务器安装目录 conf目录
v 修改azkaban.properties文件
命令vi azkaban.properties
内容说明如下:
#Azkaban Personalization Settings
azkaban.name=Test #服务器UI名称,用于服务器上方显示的名字
azkaban.label=My Local Azkaban #描述
azkaban.color=#FF3601 #UI颜色
azkaban.default.servlet.path=/index #
web.resource.dir=web/ #默认根web目录
default.timezone.id=Asia/Shanghai #默认时区,已改为亚洲/上海 默认为美国
#Azkaban UserManager class
user.manager.class=azkaban.user.XmlUserManager #用户权限管理默认类
user.manager.xml.file=conf/azkaban-users.xml #用户配置,具体配置参加下文
#Loader for projects
executor.global.properties=conf/global.properties # global配置文件所在位置
azkaban.project.dir=projects #
database.type=mysql #数据库类型
mysql.port=3306 #端口号
mysql.host=localhost #数据库连接IP
mysql.database=azkaban #数据库实例名
mysql.user= azkaban #数据库用户名
mysql.password= azkaban #数据库密码
mysql.numconnections=100 #最大连接数
# Velocity dev mode
velocity.dev.mode=false
# Jetty服务器属性.
jetty.maxThreads=25 #最大线程数
jetty.ssl.port=8443 #Jetty SSL端口
jetty.port=8081 #Jetty端口
jetty.keystore=keystore #SSL文件名
jetty.password=123456 #SSL文件密码
jetty.keypassword=123456 #Jetty主密码 与 keystore文件相同
jetty.truststore=keystore #SSL文件名
jetty.trustpassword=123456 # SSL文件密码
# 执行服务器属性
executor.port=12321 #执行服务器端口
# 邮件设置
mail.sender= #发送邮箱
mail.host= #发送邮箱smtp地址
mail.user= #发送邮件时显示的名称
mail.password= #邮箱密码
job.failure.email= #任务失败时发送邮件的地址
job.success.email= #任务成功时发送邮件的地址
lockdown.create.projects=false #
cache.directory=cache #缓存目录
v 用户配置
进入azkaban web服务器conf目录,修改azkaban-users.xml
vi azkaban-users.xml 增加 管理员用户
v azkaban 执行服务器executor配置
进入执行服务器安装目录conf,修改azkaban.properties
vi azkaban.properties
#Azkaban
default.timezone.id=Asia/Shanghai #时区
# Azkaban JobTypes 插件配置
azkaban.jobtype.plugin.dir=plugins/jobtypes #jobtype 插件所在位置
#Loader for projects
executor.global.properties=conf/global.properties
azkaban.project.dir=projects
#数据库设置
database.type=mysql #数据库类型(目前只支持mysql)
mysql.port=3306 #数据库端口号
mysql.host=localhost #数据库IP地址
mysql.database=azkaban #数据库实例名
mysql.user=azkaban #数据库用户名
mysql.password= azkaban #数据库密码
mysql.numconnections=100 #最大连接数
# 执行服务器配置
executor.maxThreads=50 #最大线程数
executor.port=12321 #端口号(如修改,请与web服务中一致)
executor.flow.threads=30 #线程数
启动
web服务器
在azkaban web服务器目录下执行启动命令
bin/azkaban-web-start.sh
注:在web服务器根目录运行
或者启动到后台
nohup bin/azkaban-web-start.sh 1>/tmp/azstd.out 2>/tmp/azerr.out &
执行服务器
在执行服务器目录下执行启动命令
bin/azkaban-executor-start.sh
注:只能要执行服务器根目录运行
启动完成后,在浏览器(建议使用谷歌浏览器)中输入https://服务器IP地址:8443 ,即可访问azkaban服务了.在登录中输入刚才新的户用名及密码,点击 login.
Azkaban Demo
Command类型单一job示例
1、创建job描述文件
vi command.job
#command.job
type=command
command=echo 'hello'
2、将job资源文件打包成zip文件
zip command.job
3、通过azkaban的web管理平台创建project并上传job压缩包
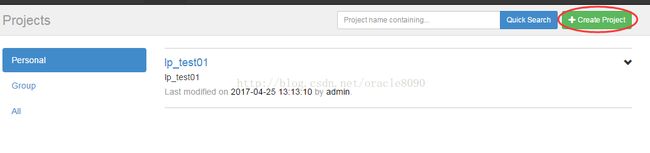
首先创建project
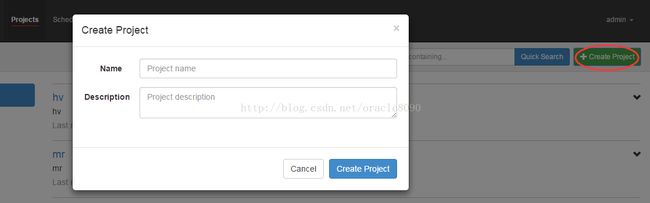
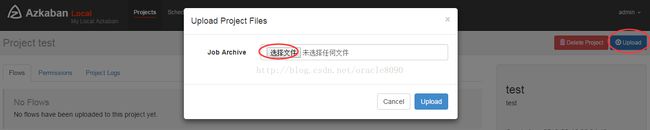
上传zip包
4、启动执行该job

Command类型多job工作流flow
1、创建有依赖关系的多个job描述
第一个job:one.job
# one.job
type=command
command=echo one
第二个job:two.job依赖one.job
# two.job
type=command
dependencies= one
command=echo two
2、将所有job资源文件打到一个zip包中

3、在azkaban的web管理界面创建工程并上传zip包
4、启动工作流flow
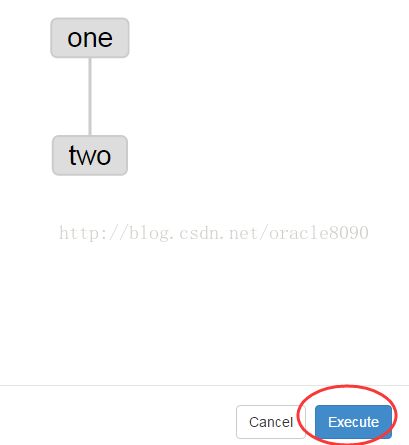
5、

-------------------------------------------------------------------------------------------------------------------------------------------------------------
1.配置邮件请在azkaban-web-server中进行配置:如下图:
/opt/azkaban/azkaban/azkaban-web-server/build/install/azkaban-web-server/conf

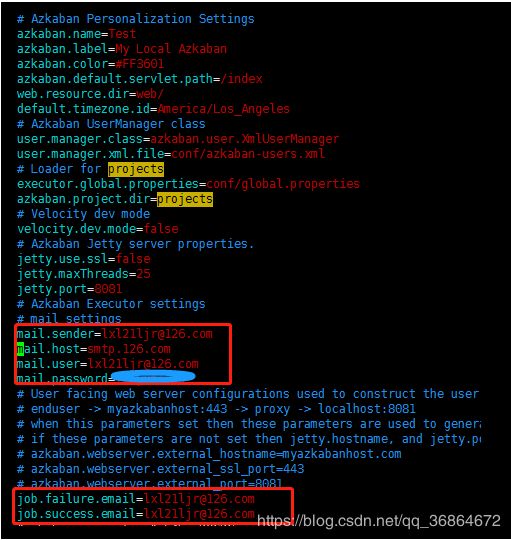
注意:
邮件服务器和接受邮件对像使用了QQ邮箱。azkaban可能不支持QQ邮箱。
解决办法:改成其它邮箱,我改成了126.com的邮箱。
2.测试:
在web UI 页面执行个job,成功则发邮件,如下:
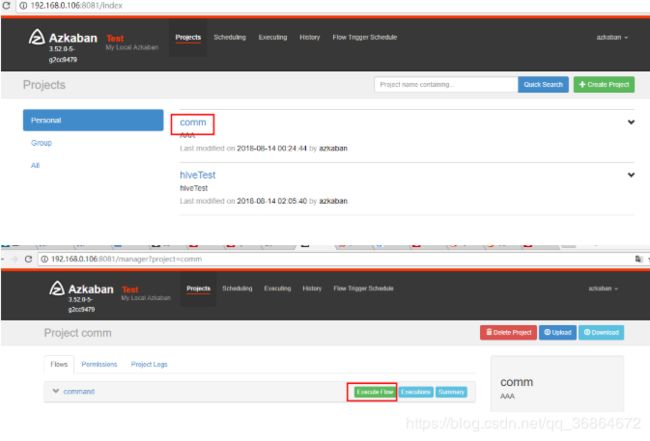
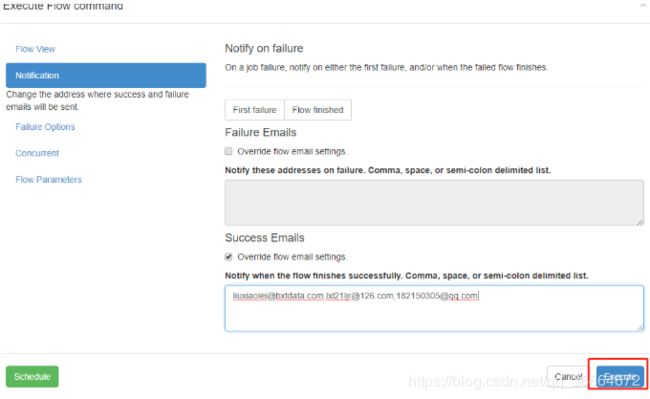
看结果,我输入了三个邮箱,而且此job也执行成功,看看三个邮箱都收到了。
除了在web UI 中直接配置也可以在job里进行配置。
azkaban配置邮件内容log链接
步骤:
1.打开azkaban server服务器conf下的azkaban.properties文件
2.在jetty参数配置处,添加jetty.hostname=localhost
其中:localhost:为azkaban 的server服务器,当前服务器的ip地址
3.重启azkanba 执行器和server服务器 验证邮件发送即可。