马氏距离-Mahalanobis Distance+MATLAB实现
一、学习目的
在训练one-shoting learning 的神经网路的时候,由于采用的是欧式距离,欧氏距离虽然很有用,但也有明显的缺点。它将样品的不同属性(即各指标或各变量)之间的差别等同看待,这一点有时不能满足实际要求。所以效果并不明显。经过一番查阅资料发现马氏距离广泛的被应用在人脸识别的损失函数上面,而且较欧拉距离取得了更好的效果。故对马氏距离进行了解和学习,并将其应用Siamese Network的损失函数定义以及特征空间距离的衡量上面。
二、关于马氏距离
马氏距离(Mahalanobis distance)是由印度统计学家马哈拉诺比斯(P. C. Mahalanobis)提出的,表示数据的协方差距离。它是一种有效的计算两个未知样本集的相似度的方法。与欧氏距离不同的是它考虑到各种特性之间的联系(例如:一条关于身高的信息会带来一条关于体重的信息,因为两者是有关联的)并且是尺度无关的(scale-invariant),即独立于测量尺度。对于一个均值为μ,协方差矩阵为Σ的多变量向量,其马氏距离为(x-μ)'Σ^(-1)(x-μ)。如果协方差矩阵为 单位矩阵,那么马氏距离就简化为欧式距离,如果协方差矩阵为 对角阵,则其也可称为正规化的 欧氏距离'.

X与 Y的协方差定义如下,可以看到其形式类似与最小方差的无偏估计量。采用方差的无偏估计量可以使得较小的样本集更好的趋近与总体的方差。

关于马氏距离中S(协方差矩阵)可逆(非奇异)的条件为:样本的个数应该要大于每个样本自身的维度。
标准差和方差一般是用来描述一维数据的,但现实生活中我们常常会遇到含有多维数据的数据集,最简单的是大家上学时免不了要统计多个学科的考试成绩。面对这样的数据集,我们当然可以按照每一维独立的计算其方差,但是通常我们还想了解更多,比如,一个男孩子的猥琐程度跟他受女孩子的欢迎程度是否存在一些联系。协方差就是这样一种用来度量两个随机变量关系的统计量,我们可以仿照方差的定义:
![]()
来度量各个维度偏离其均值的程度,协方差可以这样来定义:
![]()
协方差的结果有什么意义呢?如果结果为正值,则说明两者是正相关的(从协方差可以引出“相关系数”的定义),也就是说一个人越猥琐越受女孩欢迎。如果结果为负值, 就说明两者是负相关,越猥琐女孩子越讨厌。如果为0,则两者之间没有关系,猥琐不猥琐和女孩子喜不喜欢之间不存在线性关系,至于是否存在非线性关系需要考虑到互信息,这里不展开讨论。
从协方差的定义上我们也可以看出一些显而易见的性质,如:
![]()
![]()
三、协方差矩阵
前面提到的猥琐和受欢迎的问题是典型的二维问题,而协方差也只能处理二维问题,那维数多了自然就需要计算多个协方差,比如n维的数据集就需要计算![]() 个协方差,那自然而然我们会想到使用矩阵来组织这些数据。给出协方差矩阵的定义:
个协方差,那自然而然我们会想到使用矩阵来组织这些数据。给出协方差矩阵的定义:
![]()
这个定义还是很容易理解的,我们可以举一个三维的例子,假设数据集有三个维度,则协方差矩阵为:
![clip_image002[20]](http://img.e-com-net.com/image/info8/d14eb95ce1e34a1fa5f77b22441f3736.gif)
可见,协方差矩阵是一个对称的矩阵,而且对角线是各个维度的方差。
四、Matlab协方差实战
必须要明确一点,协方差矩阵计算的是不同维度之间的协方差,而不是不同样本之间的。以下的演示将使用Matlab,为了说明计算原理,不直接调用Matlab的cov函数:
首先,随机生成一个10*3维的整数矩阵作为样本集,10为样本的个数,3为样本的维数。

图 1 使用Matlab生成样本集
根据公式,计算协方差需要计算均值,前面特别强调了,协方差矩阵是计算不同维度之间的协方差,要时刻牢记这一点。样本矩阵的每行是一个样本,每列是一个维度,因此我们要按列计算均值。为了描述方便,我们先将三个维度的数据分别赋值:
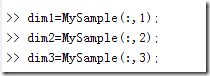
图 2 将三个维度的数据分别赋值
计算dim1与dim2,dim1与dim3,dim2与dim3的协方差:

图 3 计算三个协方差
协方差矩阵的对角线上的元素就是各个维度的方差,下面我们依次计算这些方差:
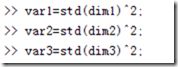
图 4 计算对角线上的方差
这样,我们就得到了计算协方差矩阵所需要的所有数据,可以调用Matlab的cov函数直接得到协方差矩阵:

图 5 使用Matlab的cov函数直接计算样本的协方差矩阵
计算的结果,和之前的数据填入矩阵后的结果完全相同。
五、总结
理解协方差矩阵的关键就在于牢记它的计算是不同维度之间的协方差,而不是不同样本之间。拿到一个样本矩阵,最先要明确的就是一行是一个样本还是一个维度,心中明确整个计算过程就会顺流而下,这么一来就不会迷茫了。