深度之眼-科赛网二分类大赛入门之路
-
比赛简介
比赛网址:https://www.kesci.com/home/competition/5c234c6626ba91002bfdfdd3/content
比赛题目:「二分类算法」提供银行精准营销解决方案
赛题描述:

数据:
训练集:
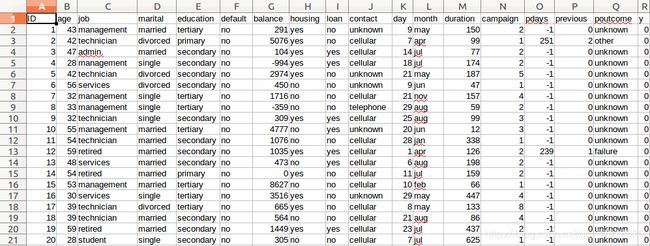
测试集(没有标签y):

字段说明:
| NO | 字段名称 | 数据类型 | 字段描述 |
|---|---|---|---|
| 1 | ID | Int | 客户唯一标识 |
| 2 | age | Int | 客户年龄 |
| 3 | job | String | 客户的职业 |
| 4 | marital | String | 婚姻状况 |
| 5 | education | String | 受教育水平 |
| 6 | default | String | 是否有违约记录 |
| 7 | balance | Int | 每年账户的平均余额 |
| 8 | housing | String | 是否有住房贷款 |
| 9 | loan | String | 是否有个人贷款 |
| 10 | contact | String | 与客户联系的沟通方式 |
| 11 | day | Int | 最后一次联系的时间(几号) |
| 12 | month | String | 最后一次联系的时间(月份) |
| 13 | duration | Int | 最后一次联系的交流时长 |
| 14 | campaign | Int | 在本次活动中,与该客户交流过的次数 |
| 15 | pdays | Int | 距离上次活动最后一次联系该客户,过去了多久(999表示没有联系过) |
| 16 | previous | Int | 在本次活动之前,与该客户交流过的次数 |
| 17 | poutcome | String | 上一次活动的结果 |
| 18 | y | Int | 预测客户是否会订购定期存款业务 |
测评算法:
AUC
-
实验步骤
1.读取数据
import numpy as np
import pandas as pd
# 训练集
train_data = pd.read_csv('./train_set.csv')
train_data.drop(['ID'], inplace=True, axis=1)
# 测试集
test_data = pd.read_csv('./test_set.csv')
test_data.drop(['ID'], inplace=True, axis=1)inplace=True代表不创建新的对象,直接对原始对象进行修改。
2.预处理
通过sklearn的preprocessing模块进行预处理,将数据中所有数据格式为object的列通过LabelEncoder()函数转化为类别category。
# 预处理
from sklearn import preprocessing
for col in train_data.columns[train_data.dtypes=='object']:
LE = preprocessing.LabelEncoder()
LE.fit(train_data[col])
# 将string类型转换成category
train_data[col] = LE.transform(train_data[col])
test_data[col] = LE.transform(test_data[col])3.标准化
通过preprocessing模块的StandardScaler()函数进行数据标准化。
# 标准化
scaler = preprocessing.StandardScaler()
scaler.fit(train_data[['age','balance','duration','campaign','pdays','previous']])
train_data[['age','balance','duration','campaign','pdays','previous']] = scaler.transform(train_data[['age','balance','duration','campaign','pdays','previous']])
test_data[['age','balance','duration','campaign','pdays','previous']] = scaler.transform(test_data[['age','balance','duration','campaign','pdays','previous']])4.切分训练集和验证集
通过model_selection模块的train_test_split()函数切分训练集和验证集,比例为4:1。
# 切分训练集和验证集
from sklearn.model_selection import train_test_split
use_col = list(set(train_data.columns) - set(['y']))
train_X, valid_X, train_y, valid_y = train_test_split(train_data[use_col], train_data['y'], test_size=0.2)5.使用简单模型
(1)LogisticRegression
# Logistic Regression
from sklearn.linear_model import LogisticRegression
from sklearn.metrics import accuracy_score, roc_auc_score
LR = LogisticRegression(solver='liblinear')
LR.fit(train_X, train_y.values.ravel()) # 利用ravel()处理不平衡数据
LR_pred = LR.predict(valid_X)
LR_pred_prob = LR.predict_proba(valid_X)[:, 1]
print("Accuracy:{:.4f}".format(accuracy_score(valid_y, LR_pred)))
print("AUC Score(Train data): {:.4f}".format(roc_auc_score(valid_y, LR_pred_prob)))
LR_test_pred_prob = LR.predict_proba(test_data)[:, 1]
df_test = pd.read_csv('./test_set.csv')
df_test['pred'] = LR_test_pred_prob.tolist()
df_result = df_test.loc[:, ['ID', 'pred']]
df_result.to_csv('LR.csv', index=False)在验证集上的准确率为0.8940,AUC得分为0.8726
(2)KNN
# kNN
from sklearn.neighbors import KNeighborsClassifier
KNN = KNeighborsClassifier()
KNN.fit(train_X, train_y.values.ravel())
KNN_pred = KNN.predict(valid_X)
KNN_pred_prob = KNN.predict_proba(valid_X)[:, 1]
print("Accuracy:{:.4f}".format(accuracy_score(valid_y, KNN_pred)))
print("AUC Score(Train data): {:.4f}".format(roc_auc_score(valid_y, KNN_pred_prob)))
KNN_test_pred_prob = KNN.predict_proba(test_data)[:, 1]
df_test = pd.read_csv('./test_set.csv')
df_test['pred'] = KNN_test_pred_prob.tolist()
df_result = df_test.loc[:, ['ID', 'pred']]
df_result.to_csv('KNN.csv', index=False)在验证集上的准确率为0.8922,AUC得分为0.8119
(3)决策树
# Decision Tree
from sklearn.tree import DecisionTreeClassifier
DT = DecisionTreeClassifier(min_samples_split=40)
DT.fit(train_X, train_y.values.ravel())
DT_pred = DT.predict(valid_X)
DT_pred_prob = DT.predict_proba(valid_X)[:, 1]
print("Accuracy:{:.4f}".format(accuracy_score(valid_y, DT_pred)))
print("AUC Score(Train data): {:.4f}".format(roc_auc_score(valid_y, DT_pred_prob)))
DT_test_pred_prob = DT.predict_proba(test_data)[:, 1]
df_test = pd.read_csv('./test_set.csv')
df_test['pred'] = DT_test_pred_prob.tolist()
df_result = df_test.loc[:, ['ID', 'pred']]
df_result.to_csv('DT.csv', index=False)在验证集上的准确率为0.8924,AUC得分为0.8588
(4)平均得分
# 平均得分
ave_pred = (LR_pred + KNN_pred + DT_pred) / 3
ave_pred_prob = (LR_pred_prob + KNN_pred_prob + DT_pred_prob) / 3
print("AUC Score(Train data): {:.4f}".format(roc_auc_score(valid_y, ave_pred_prob)))
ave_test_pred_prob = (LR_test_pred_prob + KNN_test_pred_prob + DT_test_pred_prob) / 3
df_test = pd.read_csv('./test_set.csv')
df_test['pred'] = ave_test_pred_prob.tolist()
df_result = df_test.loc[:, ['ID', 'pred']]
df_result.to_csv('./average.csv', index=False)AUC得分为0.9123
6.使用GradientBoosting
# Gradient Boosting
from sklearn.ensemble import GradientBoostingClassifier
GB = GradientBoostingClassifier()
GB.fit(train_X, train_y.values.ravel())
GB_pred = GB.predict(valid_X)
GB_pred_prob = GB.predict_proba(valid_X)[:, 1]
print("Accuracy:{:.4f}".format(accuracy_score(valid_y, GB_pred)))
print("AUC Score(Train data): {:.4f}".format(roc_auc_score(valid_y, GB_pred_prob)))在验证集上的准确率为0.9038,AUC得分为0.9221,明显比简单模型效果更好。
7.网格搜索最优参数
搜索最优参数时,使用整个训练集:
full_train_X = train_data.iloc[:, train_data.columns!='y']
full_train_y = train_data.iloc[:, train_data.columns=='y']首先同时搜索学习率learning_rate和迭代次数n_estimators:
# 网格搜索最优参数
from sklearn.model_selection import GridSearchCV
# 搜索学习率learning_rate和迭代次数n_estimators
param_search1 = {'learning_rate': [0.01, 0.1, 1.],
'n_estimators': list(range(10, 100, 10))+list(range(100,1001,100))}
grid1 = GridSearchCV(estimator=GradientBoostingClassifier(),
param_grid=param_search1,
scoring='roc_auc',
iid=False,
cv=3)
grid1.fit(full_train_X, full_train_y.values.ravel())
grid1.best_params_,grid1.best_score_得到最优学习率和最优迭代次数,以及对应的AUC得分为:
({'learning_rate': 0.1, 'n_estimators': 500}, 0.9286749844960692)
然后同时搜索最大深度max_depth和最小样本数min_samples_split和叶子节点最小样本数min_samples_leaf,使用第一步得到的最优学习率和最优迭代次数:
# 搜索最大深度max_depth和最小样本数min_samples_split和叶子节点最小样本数min_samples_leaf
param_search2 = {'max_depth': list(range(3, 14, 2)),
'min_samples_split': list(range(100, 1001, 200)),
'min_samples_leaf': list(range(50, 101, 10))}
grid2 = GridSearchCV(estimator=GradientBoostingClassifier(learning_rate=grid1.best_params_['learning_rate'],
n_estimators=grid1.best_params_['n_estimators']),
param_grid=param_search2,
scoring='roc_auc',
iid=False,
cv=3)
grid2.fit(full_train_X, full_train_y.values.ravel())
grid2.best_params_,grid2.best_score_得到最优的最大深度,叶子节点最小样本数,最小样本数和对应的AUC得分为:
({'max_depth': 5, 'min_samples_leaf': 90, 'min_samples_split': 300},
0.9302954874270872)
8.生成预测
使用网格搜索得到的五个参数,对整个训练集进行拟合之后,对测试集数据进行预测,得到预测结果的csv文件。
# 生成预测
from sklearn.ensemble import GradientBoostingClassifier
GB = GradientBoostingClassifier(learning_rate=0.1,
n_estimators=500,
max_depth=5,
min_samples_leaf=90,
min_samples_split=300)
GB.fit(full_train_X, full_train_y.values.ravel())
GB_pred = GB.predict(test_data)
GB_pred_prob = GB.predict_proba(valid_X)[:, 1]
GB_test_pred_prob = GB.predict_proba(test_data)[:, 1]
df_test = pd.read_csv('./test_set.csv')
df_test['pred'] = GB_test_pred_prob.tolist()
df_result = df_test.loc[:, ['ID', 'pred']]
df_result.to_csv('./GB.csv', index=False)9.查看得分

离前十0.9402差了一个百分点。