Spark源码解读之Worker剖析
在上一篇中我们剖析了Master的工作原理,这节我们接着来剖析Worker的工作员原理,Worker主要包括两部分的工作,启动Executor和启动Driver,然后向Master发送注册启动消息。
下面是Worker的工作流程图:
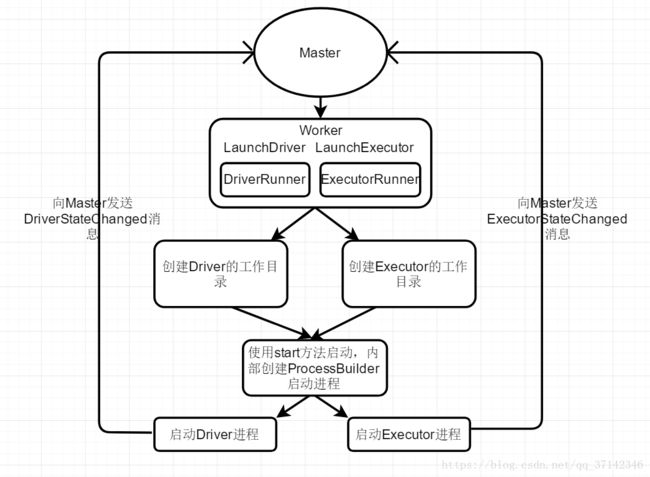
在Application向Master注册之后,Master会发出命令启动Wroker,在Worker节点启动之后,它会调动内部的两个方法LaunchDriver和LaunchExecutor分别启动Driver和Executor,它们的启动过程大致相同,都是先创建一个DriverRunnner或者ExecutorRunner来封装Driver或者Executor的信息来启动Driver或者Executor,先创建它们各自的工作目录,然后会调用内部的start的方法启动,在start方法中会创建ProcessBuilder来启动进程,最后它会等待Driver或者Executor工作完成退出,最后向它们各自所在的Worker节点发送DriverStateChanged消息,接着Worker向Master发送DriverStateChanged消息。
首先来看看Driver启动的LaunchDriver方法的源码:
/**
* 启动Driver
*/
case LaunchDriver(driverId, driverDesc) => {
logInfo(s"Asked to launch driver $driverId")
//将Driver的信息封装在一个线程中启动
val driver = new DriverRunner(
conf,
driverId,
workDir,
sparkHome,
driverDesc.copy(command = Worker.maybeUpdateSSLSettings(driverDesc.command, conf)),
self,
akkaUrl)
//将Driver放入缓存中(HashMap中)
drivers(driverId) = driver
//启动Driver
driver.start()
//使用的CPU核数加上Driver使用的核数
coresUsed += driverDesc.cores
//使用的内存加上Driver的内存
memoryUsed += driverDesc.mem
}
内部的start启动方法:
/** Starts a thread to run and manage the driver. */
def start() = {
//启动一个java线程
new Thread("DriverRunner for " + driverId) {
override def run() {
try {
//创建Driver的工作目录
val driverDir = createWorkingDirectory()
//加载启动Spark需要的jar包
val localJarFilename = downloadUserJar(driverDir)
def substituteVariables(argument: String): String = argument match {
case "{{WORKER_URL}}" => workerUrl
case "{{USER_JAR}}" => localJarFilename
case other => other
}
//创建ProcessBuilder,传入driverDesc和driver需要的内存大小的参数等等
// TODO: If we add ability to submit multiple jars they should also be added here
val builder = CommandUtils.buildProcessBuilder(driverDesc.command, driverDesc.mem,
sparkHome.getAbsolutePath, substituteVariables)
//启动Driver进行成
launchDriver(builder, driverDir, driverDesc.supervise)
}
catch {
case e: Exception => finalException = Some(e)
}
val state =
if (killed) {
DriverState.KILLED
} else if (finalException.isDefined) {
DriverState.ERROR
} else {
finalExitCode match {
case Some(0) => DriverState.FINISHED
case _ => DriverState.FAILED
}
}
finalState = Some(state)
//向Driver所在的Worker发送DriverStateChanged
worker ! DriverStateChanged(driverId, state, finalException)
}
}.start()
}
/***
* 启动Driver进程
* @param builder
* @param baseDir
* @param supervise
*/
private def launchDriver(builder: ProcessBuilder, baseDir: File, supervise: Boolean) {
builder.directory(baseDir)
def initialize(process: Process) = {
//重定向stdout和stderr到文件中(将输出的日志和报错的日志写入磁盘文件中)
// Redirect stdout and stderr to files
val stdout = new File(baseDir, "stdout")
CommandUtils.redirectStream(process.getInputStream, stdout)
val stderr = new File(baseDir, "stderr")
val header = "Launch Command: %s\n%s\n\n".format(
builder.command.mkString("\"", "\" \"", "\""), "=" * 40)
Files.append(header, stderr, UTF_8)
CommandUtils.redirectStream(process.getErrorStream, stderr)
}
runCommandWithRetry(ProcessBuilderLike(builder), initialize, supervise)
}
case DriverStateChanged(driverId, state, exception) => {
state match {
case DriverState.ERROR =>
logWarning(s"Driver $driverId failed with unrecoverable exception: ${exception.get}")
case DriverState.FAILED =>
logWarning(s"Driver $driverId exited with failure")
case DriverState.FINISHED =>
logInfo(s"Driver $driverId exited successfully")
case DriverState.KILLED =>
logInfo(s"Driver $driverId was killed by user")
case _ =>
logDebug(s"Driver $driverId changed state to $state")
}
//在Driver向Worker发来DriverStateChanged之后
//Worker向Driver发送DriverStateChanged消息
master ! DriverStateChanged(driverId, state, exception)
//Driver工作完成之后从缓存中移除该Driver
val driver = drivers.remove(driverId).get
finishedDrivers(driverId) = driver
memoryUsed -= driver.driverDesc.mem
coresUsed -= driver.driverDesc.cores
}
Worker类内部的LaunchExecutor方法源码:
/**
* 启动Executor进程
*/
case LaunchExecutor(masterUrl, appId, execId, appDesc, cores_, memory_) =>
if (masterUrl != activeMasterUrl) {
logWarning("Invalid Master (" + masterUrl + ") attempted to launch executor.")
} else {
try {
logInfo("Asked to launch executor %s/%d for %s".format(appId, execId, appDesc.name))
//创建Executor工作目录
// Create the executor's working directory
val executorDir = new File(workDir, appId + "/" + execId)
if (!executorDir.mkdirs()) {
throw new IOException("Failed to create directory " + executorDir)
}
// Create local dirs for the executor. These are passed to the executor via the
// SPARK_LOCAL_DIRS environment variable, and deleted by the Worker when the
// application finishes.
/**
* 创建executor的本地目录,它们可以通过SPARK_LOCAL_DIRS环境变量来指定,并且在application完成的时候被Worker删除
*/
val appLocalDirs = appDirectories.get(appId).getOrElse {
Utils.getOrCreateLocalRootDirs(conf).map { dir =>
Utils.createDirectory(dir).getAbsolutePath()
}.toSeq
}
appDirectories(appId) = appLocalDirs
//启动Executor线程来启动Executor
val manager = new ExecutorRunner(
appId,
execId,
appDesc.copy(command = Worker.maybeUpdateSSLSettings(appDesc.command, conf)),
cores_,
memory_,
self,
workerId,
host,
webUi.boundPort,
publicAddress,
sparkHome,
executorDir,
akkaUrl,
conf,
appLocalDirs, ExecutorState.LOADING)
executors(appId + "/" + execId) = manager
//启动executor
manager.start()
//CPU核数加上executor使用的核数
coresUsed += cores_
//使用的内存加上executor使用的内存大小
memoryUsed += memory_
//executor向worker发送ExecutorStateChanged的状态改变消息
//worker又向master发送ExecutorStateChanged状态改变的消息
master ! ExecutorStateChanged(appId, execId, manager.state, None, None)
} catch {
case e: Exception => {
logError(s"Failed to launch executor $appId/$execId for ${appDesc.name}.", e)
if (executors.contains(appId + "/" + execId)) {
executors(appId + "/" + execId).kill()
executors -= appId + "/" + execId
}
master ! ExecutorStateChanged(appId, execId, ExecutorState.FAILED,
Some(e.toString), None)
}
}
}
/**
* 启动Executor进程
*/
def start() {
//创建JAVA线程
workerThread = new Thread("ExecutorRunner for " + fullId) {
override def run() { fetchAndRunExecutor() }
}
workerThread.start()
// Shutdown hook that kills actors on shutdown.
shutdownHook = new Thread() {
override def run() {
killProcess(Some("Worker shutting down"))
}
}
Runtime.getRuntime.addShutdownHook(shutdownHook)
}
/**
* Download and run the executor described in our ApplicationDescription
*/
def fetchAndRunExecutor() {
try {
//创建ProcessBuilder
// Launch the process
val builder = CommandUtils.buildProcessBuilder(appDesc.command, memory,
sparkHome.getAbsolutePath, substituteVariables)
val command = builder.command()
logInfo("Launch command: " + command.mkString("\"", "\" \"", "\""))
builder.directory(executorDir)
builder.environment.put("SPARK_LOCAL_DIRS", appLocalDirs.mkString(","))
// In case we are running this from within the Spark Shell, avoid creating a "scala"
// parent process for the executor command
builder.environment.put("SPARK_LAUNCH_WITH_SCALA", "0")
// Add webUI log urls
val baseUrl =
s"http://$publicAddress:$webUiPort/logPage/?appId=$appId&executorId=$execId&logType="
builder.environment.put("SPARK_LOG_URL_STDERR", s"${baseUrl}stderr")
builder.environment.put("SPARK_LOG_URL_STDOUT", s"${baseUrl}stdout")
process = builder.start()
val header = "Spark Executor Command: %s\n%s\n\n".format(
command.mkString("\"", "\" \"", "\""), "=" * 40)
//重定向stdout和stderr到文件中
// Redirect its stdout and stderr to files
val stdout = new File(executorDir, "stdout")
stdoutAppender = FileAppender(process.getInputStream, stdout, conf)
val stderr = new File(executorDir, "stderr")
Files.write(header, stderr, UTF_8)
stderrAppender = FileAppender(process.getErrorStream, stderr, conf)
// Wait for it to exit; executor may exit with code 0 (when driver instructs it to shutdown)
// or with nonzero exit code
//等待executor完成任务退出
val exitCode = process.waitFor()
state = ExecutorState.EXITED
val message = "Command exited with code " + exitCode
//向executor所在的Worker节点发送ExecutorStateChanged消息
worker ! ExecutorStateChanged(appId, execId, state, Some(message), Some(exitCode))
} catch {
case interrupted: InterruptedException => {
logInfo("Runner thread for executor " + fullId + " interrupted")
state = ExecutorState.KILLED
killProcess(None)
}
case e: Exception => {
logError("Error running executor", e)
state = ExecutorState.FAILED
killProcess(Some(e.toString))
}
}
}
至此我们就剖析完了Worker节点的工作流程,如有任何问题,希望不吝赐教!!!