Spark源码解读之SparkContext剖析
最近一直在研究Spark,也自己练习做了几个项目,对于Spark这个框架特别的喜爱,尤其是其一站式的大数据解决方案,而且也对Spark MLlib中的机器学习算法很感兴趣,也学习过一段时间。但是在自己空闲下来回想,对于Spark的理解自己仅仅只是停留在表层,如果只是使用API来编写Spark程序,那么无疑将Spark与其他普通的框架混为一谈,发挥不了其作用,根本谈不上说熟悉Spark。因此,想花一段时间来研究Spark的内核架构与源码,常听大牛们说学习技术不仅要知道它怎么使用,更要知其所以然。那么,抱着这种心态来开启Spark的内核与源码的剖析之旅吧!
转发请标明原文地址:原文链接
上篇文章Spark内核架构流程深度剖析一文中我们剖析了Spark核心架构以及job提交执行的流程。这篇文章将会从源码的角度出发探究其内部的实现细节,首先从SparkContext的创建以及它执行的任务开始。
和以前一样,依旧使用图解的方式来剖析,下面是SparContext创建的流程图:
在一个Spark应用程序中必定先创建SparkContext对象,在讲SparkContext对象之前,还有一个对象值得一提,在创建了SparkConf之后,会利用它来创建一个对象SparkEnv,那么这个对象的作用是什么呢?官方给出的解释是Holds all the runtime environment objects for a running Spark instance (either master or worker),也就是拥有一个运行时Spark实例(mater,worker)的所有运行时环境的对象,这些环境变量主要包括下面内容:
class SparkEnv (
val executorId: String,
val actorSystem: ActorSystem,
val serializer: Serializer,
val closureSerializer: Serializer,
val cacheManager: CacheManager, //用于存储中间计算结果
val mapOutputTracker: MapOutputTracker, //用来缓存MapStatus信息,并提供从MapOutputMaster获取信息的功能
val shuffleManager: ShuffleManager, //路由维护表
val broadcastManager: BroadcastManager, //广播
val blockTransferService: BlockTransferService,
val blockManager: BlockManager, //块管理
val securityManager: SecurityManager, //安全管理
val httpFileServer: HttpFileServer, //文件存储目录
val sparkFilesDir: String, //文件存储目录
val metricsSystem: MetricsSystem, //测量
val shuffleMemoryManager: ShuffleMemoryManager,
val outputCommitCoordinator: OutputCommitCoordinator,
val conf: SparkConf //配置文件
)也就是说这个对象持有集群所有节点的运行时的环境配置,对于SparkEnv 的介绍就到这里,有兴趣的读者可以详细阅读相关源码。下面我们进入今天的重点SparkContext。
在SparkContext这个类中有这样一段代码:
/**
* 1、创建TaskSchedulerImpl
* 2、创建了底层调度器SparkDeploySchedulerBackend
* 3、使用TaskSchedulerImpl.initial方法初始化了底层的调度池
*/
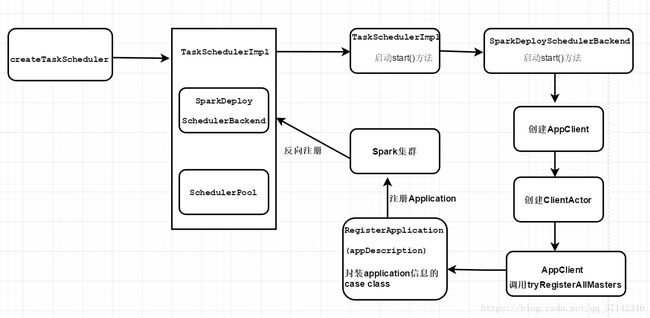
private[spark] var (schedulerBackend, taskScheduler) = SparkContext.createTaskScheduler(this, master)我们都知道在scala中,没有在任何方法或者代码块中代码在调用主构造函数的时候都会执行,而上面这段代码没有在任何方法或者代码块中,那么在执行val sc=new SparkContext(conf)代码的时候会调用上面的代码createTaskScheduler方法来创建TaskScheduler接口的实现类TaskSchedulerImpl。在这个方法中实际上一些匹配规则来匹配我们提交的模式,比如local模式提交作业,如下图所示:
我们今天重点来研究standalone模式提交作业的工作流程,因此在这个方法中我们重点来看这段代码:
/**
* 这种方式就是spark常用的standalone模式
*/
case SPARK_REGEX(sparkUrl) =>
val scheduler = new TaskSchedulerImpl(sc)
val masterUrls = sparkUrl.split(",").map("spark://" + _)
//创建TaskSchedulerImpl完成,创建底层SparkDeploySchedulerBackend
val backend = new SparkDeploySchedulerBackend(scheduler, sc, masterUrls)
//初始化TaskSchedulerImpl
scheduler.initialize(backend)
(backend, scheduler)首先会创建TaskSchedulerImpl。
TaskSchedulerImpl的主要作用是什么呢?在它内部完成了什么工作呢?
它的主要作用是:
- 底层通过操作一个SchedulerBackend,来调度各种不同种类的cluster(比如standalone,yarn,mesos),来调度task
- 它也可以使用本地模式来启动一个task使用LocalBackend或者设置isLocal属性为true
- 它也负责一些通过的逻辑,比如任务的调度顺序(FIFO etc…),启动推测的task执行等等
- 客户端应该首先调用initialize()和start()方法,然后通过runTasks()方法来提交task set
在创建完TaskSchedulerImpl之后,它会创建对象SparkDeploySchedulerBackend。
它的作用是控制TaskSchedulerImpl,实际上是负责Master的注册,Executor的反向注册,Task任务发送到Executor。因此这个类也是至关重要的。它内部的具体信息稍后会讲到,我们接着启动流程。
在SparkDeploySchedulerBackend创建完成之后,就会调用TaskSchedulerImpl的initialize方法来初始化TaskSchedulerImpl和SparkDeploySchedulerBackend,源码如下:
/**
* TaskScheduler初始化,会创建一个调度池,这个调度池有不同的优先级调度策略,比如FIFO等
* @param backend
*/
def initialize(backend: SchedulerBackend) {
//初始化SparkDeploySchedulerBackend
this.backend = backend
// temporarily set rootPool name to empty
rootPool = new Pool("", schedulingMode, 0, 0)
schedulableBuilder = {
//不同的调度策略
schedulingMode match {
case SchedulingMode.FIFO =>
new FIFOSchedulableBuilder(rootPool)
case SchedulingMode.FAIR =>
new FairSchedulableBuilder(rootPool, conf)
}
}
schedulableBuilder.buildPools()
}在除了初始化上面这两个对象之外,它还会创建一个调度池,比如FIFO,FAIR等等,用于任务调度策略。
到这里整个createTaskScheduler方法中的代码就全部执行完毕。
可以看到,在createTaskScheduler方法的standalone模式下会做三件事情:
- 创建TaskSchedulerImpl
- 创建底层SparkDeploySchedulerBackend
- 初始化TaskSchedulerImpl,SparkDeploySchedulerBackend,创建调度池
接着它会调用TaskSchedulerImpl类中的start方法进行启动:
private[spark] var (schedulerBackend, taskScheduler) =
SparkContext.createTaskScheduler(this, master)
private val heartbeatReceiver = env.actorSystem.actorOf(
Props(new HeartbeatReceiver(this, taskScheduler)), "HeartbeatReceiver")
@volatile private[spark] var dagScheduler: DAGScheduler = _
try {
/**
* 创建DAGScheduler
*/
dagScheduler = new DAGScheduler(this)
} catch {
case e: Exception => {
try {
stop()
} finally {
throw new SparkException("Error while constructing DAGScheduler", e)
}
}
}
// start TaskScheduler after taskScheduler sets DAGScheduler reference in DAGScheduler's
// constructor
taskScheduler.start()在这中间它还会创建DAGScheduler,这个对象也是非常重要的,在稍后会详细介绍,在start方法内部会调用SparkDeploySchedulerBackend的start方法:
override def start() {
backend.start()
if (!isLocal && conf.getBoolean("spark.speculation", false)) {
logInfo("Starting speculative execution thread")
import sc.env.actorSystem.dispatcher
sc.env.actorSystem.scheduler.schedule(SPECULATION_INTERVAL milliseconds,
SPECULATION_INTERVAL milliseconds) {
Utils.tryOrExit { checkSpeculatableTasks() }
}
}
}在SparkDeploySchedulerBackend的start方法的内部:
override def start() {
super.start()
// The endpoint for executors to talk to us
val driverUrl = AkkaUtils.address(
AkkaUtils.protocol(actorSystem),
SparkEnv.driverActorSystemName,
conf.get("spark.driver.host"),
conf.get("spark.driver.port"),
CoarseGrainedSchedulerBackend.ACTOR_NAME)
val args = Seq(
"--driver-url", driverUrl,
"--executor-id", "{{EXECUTOR_ID}}",
"--hostname", "{{HOSTNAME}}",
"--cores", "{{CORES}}",
"--app-id", "{{APP_ID}}",
"--worker-url", "{{WORKER_URL}}")
val extraJavaOpts = sc.conf.getOption("spark.executor.extraJavaOptions")
.map(Utils.splitCommandString).getOrElse(Seq.empty)
val classPathEntries = sc.conf.getOption("spark.executor.extraClassPath")
.map(_.split(java.io.File.pathSeparator).toSeq).getOrElse(Nil)
val libraryPathEntries = sc.conf.getOption("spark.executor.extraLibraryPath")
.map(_.split(java.io.File.pathSeparator).toSeq).getOrElse(Nil)
// When testing, expose the parent class path to the child. This is processed by
// compute-classpath.{cmd,sh} and makes all needed jars available to child processes
// when the assembly is built with the "*-provided" profiles enabled.
val testingClassPath =
if (sys.props.contains("spark.testing")) {
sys.props("java.class.path").split(java.io.File.pathSeparator).toSeq
} else {
Nil
}
// Start executors with a few necessary configs for registering with the scheduler
val sparkJavaOpts = Utils.sparkJavaOpts(conf, SparkConf.isExecutorStartupConf)
val javaOpts = sparkJavaOpts ++ extraJavaOpts
val command = Command("org.apache.spark.executor.CoarseGrainedExecutorBackend",
args, sc.executorEnvs, classPathEntries ++ testingClassPath, libraryPathEntries, javaOpts)
val appUIAddress = sc.ui.map(_.appUIAddress).getOrElse("")
/**
* application应用程序的一些详细描述信息,包括这个application最大需要的cpu core,每个slaves需要的内存大小
*/
val appDesc = new ApplicationDescription(sc.appName, maxCores, sc.executorMemory, command,
appUIAddress, sc.eventLogDir, sc.eventLogCodec)
//创建AppClient
client = new AppClient(sc.env.actorSystem, masters, appDesc, this, conf)
client.start()
waitForRegistration()
}可以看出实际上最为核心的组件是底层的SparkDeploySchedulerBackend,它初始化一系列配置信息,还会将application的详细信息封装成一个类ApplicationDescription,然后创建AppClient,然后将application的信息注册到Master上,下面来看它内部的详细源码。
它会创建ApplicationDescription对象,这个对象是应用程序的一系列配置信息,包括集群的CPU核数,每个节点的分配内存,集群的最大核数等信息:
private[spark] class ApplicationDescription(
val name: String,
val maxCores: Option[Int],
val memoryPerSlave: Int,
val command: Command,
var appUiUrl: String,
val eventLogDir: Option[URI] = None,
// short name of compression codec used when writing event logs, if any (e.g. lzf)
val eventLogCodec: Option[String] = None)接着会利用ApplicationDescription创建一个AppClient对象,实际上AppClient是 一个接口,它主要负责接收一个master-url的参数和ApplicationDescription,和集群事件监听器和各种事件发生时的监听器。
对象创建完毕之后,会调用AppClient对象的start方法:
def start() {
// Just launch an actor; it will call back into the listener.
//akka模型,相当于一个线程
actor = actorSystem.actorOf(Props(new ClientActor))
}
def stop() {
if (actor != null) {
try {
val timeout = AkkaUtils.askTimeout(conf)
val future = actor.ask(StopAppClient)(timeout)
Await.result(future, timeout)
} catch {
case e: TimeoutException =>
logInfo("Stop request to Master timed out; it may already be shut down.")
}
actor = null
}
}
}注意这块代码actor = actorSystem.actorOf(Props(new ClientActor)),它还会创建ClientActor对象,它是AppClient的内部类,这个内部类的部分源码如下,它主要实现了Actor 模型:
/**
* 内部类
*/
class ClientActor extends Actor with ActorLogReceive with Logging {
var master: ActorSelection = null
var alreadyDisconnected = false // To avoid calling listener.disconnected() multiple times
var alreadyDead = false // To avoid calling listener.dead() multiple times
var registrationRetryTimer: Option[Cancellable] = None在这个内部类中有两个重要的方法用来向master注册信息:
def tryRegisterAllMasters() {
for (masterAkkaUrl <- masterAkkaUrls) {
logInfo("Connecting to master " + masterAkkaUrl + "...")
val actor = context.actorSelection(masterAkkaUrl)
//将ApplicationDescription封装在case class中发送到master中去注册
actor ! RegisterApplication(appDescription)
}
}
def registerWithMaster() {
tryRegisterAllMasters()
import context.dispatcher
var retries = 0
registrationRetryTimer = Some {
context.system.scheduler.schedule(REGISTRATION_TIMEOUT, REGISTRATION_TIMEOUT) {
Utils.tryOrExit {
retries += 1
if (registered) {
registrationRetryTimer.foreach(_.cancel())
} else if (retries >= REGISTRATION_RETRIES) {
markDead("All masters are unresponsive! Giving up.")
} else {
tryRegisterAllMasters()
}
}
}
}
}核心代码块是下面的代码:
//将ApplicationDescription封装在case class中发送到master中去注册
actor ! RegisterApplication(appDescription)RegisterApplication实际上封装了ApplicationDescription信息的case class,然后将这些application的信息发送给master。(注意上面是代码scala的akka模型发送消息的方式,不理解的读者可以查阅相关资料)
case class RegisterApplication(appDescription: ApplicationDescription)
extends DeployMessage至此最为关键的TaskSchedulerImpl以及相关组件的创建,初始化我们已经详细介绍完毕,接下里看另外两个创建SparkContext时的重要组件DAGScheduler和SparkUI。
对于DAGScheduler官方详细的解释如下:
DAGScheduler是一个面向stage调度的高调度层次的工具,它会根据stage的每一个job会计算出一个DAG(有向无环图)。并且追踪每个RDD和stage的输出是否被物化(写入磁盘或者内存等地方),并且来寻找一个最优的调度策略来运行这个job,然后会提交stage封装在TaskSet到底层的TaskSchedulerImpl中将他们运行在集群上。除了处理stage的DAG的构建,这个类还负责每个运行task的最佳位置(RDD的本地性),基于当前的缓存状态,将这些提交到底层 的TaskChedulerImpl。此外,它还会因为shuffle输出的文件丢失而操作失败,在这种情况下旧的stage可能会被重新提交。如果提交失败不是由于shuffle文件丢失导致的,那么这种情况下会被TaskScheduler来处理,它会每隔很小的时间间隔重新提交每一个task,到一定情况下会取消整个stage。
DAGScheduler核心就是构建DAG,关于DAGScheduler更加详细的信息读者可自行阅读相关源码。
对于SparkUI,只是简单提一下,不做过多解释,它实际上是启动一个jettty服务器,创建了一个web应用,启动了4040端口:
private[spark] object SparkUI {
val DEFAULT_PORT = 4040
val STATIC_RESOURCE_DIR = "org/apache/spark/ui/static"
def getUIPort(conf: SparkConf): Int = {
conf.getInt("spark.ui.port", SparkUI.DEFAULT_PORT)
}注意事项:本篇文章解读的源码是Spark1.3.0的源码(至于为什么选择1.3,机缘巧合φ(>ω<*) )
至此,关于SparkContext的剖析到这里就接近尾声了,阅读源码的目的不仅仅是更加了解Spark的内部结构,更可以给我们日常编写程序时可以更快定位bug以及优化程序。更为重要的还可以提高我们的编码的技能以及思维。在阅读源码的技巧上我会多多努力,当然,要想了解spark的内部架构不仅仅是通过阅读一篇博客可以搞懂,如果想要深入读者可以自行阅读源码。如果本篇文章有任何不对的地方,还望不吝赐教,谢谢阅读!!!