构建分布式微博好友推荐系统【实战开发】
对于社交系统与电商网站,推荐系统占有很重要的位置,当数据量越来越大的时候,用户无法确定该选择什么商品,因此在电商系统中需要按照兴趣或者相似度给用户推荐相应的商品。相应的,在一个大型社交网络平台中,对于一些用户,我们希望推荐一些知名度较高,活跃度较高或者感兴趣的用户,比如一些明星,歌手,演员等等。在社交网络中,PageRank算法有着广泛的应用,因此,本篇文章主要介绍其原理以及实战进行好友的推荐 ,最后实战项目的全部代码会在GitHub上开源共享。
对于大部分社交系统来说,如果只是简单的获取好友的信息远远不够,我们可以通过获取好友的好友的信息来扩展用户的朋友圈,使得信息量更加丰富,本项目中使用PageRank算法来完成二级邻居,然后按照Rank排序,选择Top5用户实现用户的好友的好友的推荐。
PageRank算法
1.实现原理
PageRank由Google的创始人拉里.佩奇和谢尔.布林于1998年在斯坦福大学发明的这项技术。它是一种根据网页之间相互超链接计算的技术,Google用它来体现网页的相关性和重要性,在 搜索引擎优化操作中经常被用来评估网页优化的成效因素之一。
PageRank主要基于两个重要的假设。
- 被更多的链接指向的页面具有更高的重要性/权威性,即有更高的Rank值。
- 某个页面的Rank会通过它的出链传播给指向的页面。
因此,基于这两个假设,我们可以得到如下结论:如果一篇 文章被越来越多的人引用,那么这篇文章可能就是一篇经典之作,如果这篇文章引用了其他的论文,那么一定程度上这篇被引用的文章也是一篇很好的文章。应用到社交网络中,如果一个好友被更多的人关注,那么说明该好友有很高的知名度和活跃度,那么,我们可以将该好友推荐给用户。
基于这两个假设,PageRank算法的核心为:某个页面新的Rank值由当前所有页面的Rank值除以对应的出链个数再相加得到,即:
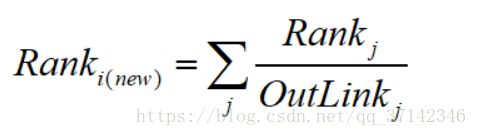
如下图所示,可以更好的表达PageRank算法的思想:

由上图可以看出,每个页面将自己的一部分rank传递给某个页面,我们可以通过计算传递给某个页面的所有rank值的和来计算出它的rank值,当然,不可能是通过一次计算完成,我们刚开始可以给每个页面赋予一个初始rank值,比如1.0,通过迭代计算得到该页面的rank值。迭代计算停止的条件为:1.新的所有页面的Rank值与旧的所有页面的Rank值之间的变化小于一个预先设定的值。第二,迭代计算的次数大于预先设定的值。
2.如何建立模型
PageRank在实际开发中的流程图如下:

使用有向图表示如下:

生成转移矩阵如下:

该转移矩阵非常简单,矩阵的每一列代表该顶点所代表的页面除以对应页面的出链数得到的。
有了转移矩阵,我们可以来定义行向量r,r的第i个分量记录Pagei对应的Rank值,因此一次Rank的 更新可以表示为:

但是在迭代计算中,我们需要考虑如下两大阻力: Dead End和Spider Trap:
- Dead End就是指一个页面只有入链但是没有出链,这时转移矩阵M的一列为零,导致最后结果为零。
- Spider Trap指页面的所有出链都指向自己,这样会使迭代结果中只有自己的页面的Rank值很高。其他页面的Rank值为零。
要克服上面两个问题,我们需要将迭代计算公式做如下转变。我们可以加入一个“随机跳转”机制,即假设每个页面有很小概率拥有一个指向其他页面的链接。表现出来就是:其他页面本来传递给一个页面的Rank值(由Mr计算)需要做一个折扣,作为补偿,可能需要一个页面指向该页面并且传递Rank值给该页面,该跳转的概率为β,因此表达式变为:

其中,N为页面的个数,e为一个N维且各个分量都为1的向量。
Spark PageRank中部分源码如下所示:
def run[VD: ClassTag, ED: ClassTag](
graph: Graph[VD, ED], numIter: Int, resetProb: Double = 0.15): Graph[Double, Double] =
{
// Initialize the PageRank graph with each edge attribute having
// weight 1/outDegree and each vertex with attribute 1.0.
var rankGraph: Graph[Double, Double] = graph
// Associate the degree with each vertex
.outerJoinVertices(graph.outDegrees) { (vid, vdata, deg) => deg.getOrElse(0) }
// Set the weight on the edges based on the degree
.mapTriplets( e => 1.0 / e.srcAttr, TripletFields.Src )
// Set the vertex attributes to the initial pagerank values
.mapVertices( (id, attr) => resetProb )
var iteration = 0
var prevRankGraph: Graph[Double, Double] = null
while (iteration < numIter) {
rankGraph.cache()
// Compute the outgoing rank contributions of each vertex, perform local preaggregation, and
// do the final aggregation at the receiving vertices. Requires a shuffle for aggregation.
val rankUpdates = rankGraph.aggregateMessages[Double](
ctx => ctx.sendToDst(ctx.srcAttr * ctx.attr), _ + _, TripletFields.Src)
// Apply the final rank updates to get the new ranks, using join to preserve ranks of vertices
// that didn't receive a message. Requires a shuffle for broadcasting updated ranks to the
// edge partitions.
prevRankGraph = rankGraph
rankGraph = rankGraph.joinVertices(rankUpdates) {
(id, oldRank, msgSum) => resetProb + (1.0 - resetProb) * msgSum
}.cache()
rankGraph.edges.foreachPartition(x => {}) // also materializes rankGraph.vertices
logInfo(s"PageRank finished iteration $iteration.")
prevRankGraph.vertices.unpersist(false)
prevRankGraph.edges.unpersist(false)
iteration += 1
}
rankGraph
}
项目实战
本项目是通过Spark 的PageRank算法来实现二级邻居来实现好友的推荐。我们需要自己实现二级邻居的计算:
第一次遍历,获取好友的id;
第二次遍历,获取好友的好友的id。
最终获取好友的好友的id的pageRank进行评分,然后按照Rank排序选择top5进行好友推荐。
需要注意:在获取好友的好友的id时有可能id是好友的id,所以必须 先筛选掉。得到的才是二级邻居的好友。
1.数据的处理以及清洗操作
数据集中的数据格式如下:
#userId,friendId,followId
1000080335,1191044977,1191044977
1000080335,1196235387,1195230310
1000080335,1558148043,1195242865
1000080335,1615743184,1196235387
1000080335,1642635773,1223178222
1000080335,1644395354,1230663070
大概有70万条数据,我们需要转换如下格式的数据(中间用空格隔开),而且要对重复的数据进行去重操作:
userId friendId
数据清洗以及转换的核心代码如下所示:
sc.textFile("F:\\spark-2.0.0\\SparkApp\\src\\cn\\just\\shinelon\\GraphX\\PageRank\\userrelation.txt")
.map(line=>{
val elems=line.split(",")
elems(0)+","+elems(1)+" "+elems(2)+","+elems(0)
})
.flatMap(_.split(" "))
.map(str=>{
val x=str.split(",")
val userId=x(0)
val friendId=x(1)
userId+" "+friendId})
.distinct()
// .take(10)
// .foreach(println)
.saveAsTextFile("hdfs://hadoop-senior.shinelon.com:8020/user/shinelon/graphx/relation.txt")
2.计算二级邻居
将数据处理为相应的格式之后,我们需要计算每个用户的二级邻居,将结果以下面的数据格式输出(中间用空格分隔):
friendId1 friendId2 friendId3 ...... friendIdn
计算的核心代码如下所示:
/**
* 根据id得到其好友的id
* 调用graph的aggregateMessages方法收集一级邻居
* @param id
* @param graph
* @return
*/
def getFristNeighborIds(id:Long,graph:Graph[Int,Int]):HashSet[Long]={
//aggregateMessages[Int]发送给每条边的每个顶点Int类型的消息
val firstNeighbor:VertexRDD[Int]=graph.aggregateMessages[Int](triplet=>{
if(triplet.srcId==id){
triplet.sendToDst(1)
}
},
(a,b)=>b+1) //聚合相同顶点接收到的消息
// firstNeighbor.foreach(println)
var fristIds=new HashSet[Long]()
firstNeighbor.collect().foreach(a=>fristIds+=a._1)
fristIds
}
/**
* 通过用户id的集合得到好友的id集合
* @param firstIds
* @param graph
* @return
*/
def getSecondNeighborIds(firstIds:HashSet[Long] , graph:Graph[Int,Int]):HashSet[Long]={
var secondIds=new HashSet[Long]()
firstIds.foreach(id=>{
val secondNeighbors=getFristNeighborIds(id,graph)
secondNeighbors.foreach(secondId=>secondIds+=secondId)
// secondIds.foreach(println)
})
// println("调用了")
// secondIds.foreach(println)
//防止在获取好友的好友的id时为好友的Id,进行筛选操作
val hashSetUtil=new HashSetUtil[Long]
hashSetUtil.removeRepeate(secondIds,firstIds)
}
/**
* 根据用户的id得到好友的好友的信息
* @param id
* @param graph
* @return
*/
def getIds(id:Long,graph:Graph[Int,Int]):HashSet[Long]={
getSecondNeighborIds(getFristNeighborIds(id,graph),graph)
}
3.计算二级邻居的Rank值
下面代码主要是计算二级邻居的PR(PageRank值),并且按照PR值进行排序,最后将结果写入HDFS文件系统:
//构建ids图
val graphxUtil=new GraphxUtil
// val subgraph=graph.subgraph(vpred=(id,attr)=>(id.toLong,attr.toLong)!=null)
val vertices=graphxUtil.getSubGraphxVertices(graph,ids)
val edges=graphxUtil.getSubGraphxEdges(graph,ids)
val subgraph=Graph(vertices,edges)
val firstNeighbor:VertexRDD[Double]=subgraph.pageRank(0.01).vertices
val neighborRank = firstNeighbor.filter(pred=>{
var flag=false
ids.foreach(id=>if(id == pred._1) flag = true)
flag
}).sortBy(x=>x._2,false) //按照rank从大到小排序
.coalesce(1)
.saveAsTextFile("hdfs://hadoop-senior.shinelon.com:8020/user/shinelon/graphx/userrank.txt")
4.取TOP5好友进行推荐
sc.textFile("hdfs://hadoop-senior.shinelon.com:8020/user/shinelon/graphx/userrank.txt").take(5).foreach(println)
以上是系统的核心模块的实现,由于开发仓促,因为没有更好的系统化开发,因此,需要指定用户进行推荐,在这里,使用了硬编码的方式,即将文件路径,用户的ID写入代码中,在实际系统开发中,不允许出现硬编码,我们需要定义常量或者使用配置文件进行配置。基于该系统,我们可以实现这样一个平台:当用户登录的时候,可以获取当前用户的Id,将id从前端传入后端,然后通过参数传入该系统,然后进行好友推荐,最后将推荐的信息发送到前端页面进行展示。
最后,我们使用一个简单的例子来展示推荐结果。这里随机选取了一个用户的Id来进行推荐。
//获取二级邻居的ids
val secondIds=graphNeighborUtil.getIds(1000080335,graph)
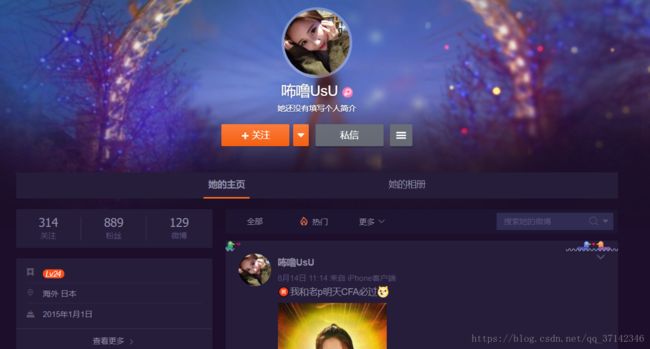
使用编号为1000080335的用户来推荐,在微博中查询可以得出,该用户账户信息如下:
最后推荐结果数据如下所示:
(friendId,rank)
(1618051664,59.89345814196924)
(1191258123,54.934897577144696)
(2656274875,54.37123848880913)
(1496852380,52.85206155862678)
(1761179351,47.46940913885135)
可以简单查看一下推荐的好友账户信息,推荐的第一个好友为头条新闻,该账户拥有上亿的粉丝数,因此可以看出,它的活跃度和社区地位都相当高了,因此可以进行推荐。

推荐的第二个好友的账户信息如下,为明星韩寒,韩寒是一个大明星,大多数人都很喜欢他,因此,也可以进行推荐。

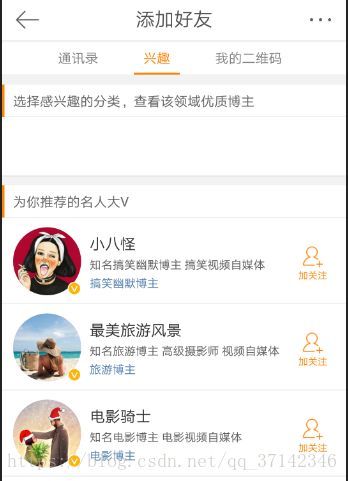
对于后面的几位推荐的好友的信息,感兴趣的读者可以自行去查看,这里就简单展示一下。从推荐结果可以看出,PageRank算法主要向用户推荐一些公众人物,知名度较高的好友,它更倾向于用户的社区地位与知名度。当然 ,还有其他算法,比如通过用户的兴趣进行推荐,也可以通过粉丝的相似度进行推荐,这个我们可以使用协同过滤推荐算法来实现。比如如下微博中的按照用户兴趣进行推荐:
至此,我们通过原理深入,最后实现一个简单的推荐项目来实现PageRank算法,相信大家对于该算法有了一个更加深刻的认识,最后附系统源码下载地址:系统源码下载地址
参考资料:
《Spark核心技术与高级应用》
Spark官方文档
如果你想和我们一起共同学习进步,交流探讨,欢迎加群: