记java重构python版bert-serving-client
背景
项目需要把bert-serving-client由python用java实现,因为java比python快一些,于是就开始了尝试
先上bert-as-service的github地址:https://github.com/hanxiao/bert-as-service
其中client的init.py文件地址:https://github.com/hanxiao/bert-as-service/blob/master/client/bert_serving/client/__init__.py
主要实现其中encode、fetch、fetchAll和encodeAsync
导包
bertClient主要用到zeroMq和json,前者用来提供和服务端的连接,后者格式化传输数据。两者pom依赖如下
org.zeromq
jeromq
0.5.1
org.zeromq
jeromq
0.5.2-SNAPSHOT
com.google.code.gson
gson
2.8.2
org.json
json
20180813
构造方法
python中有默认参数,java里没有,于是我采取属性的默认值+方法重载来实现默认参数。最后java版的构造函数如下:
private void init() throws Exception {
mContext = new ZContext();
String url = "tcp://" + mIp + ":";
mIdentity = UUID.randomUUID().toString();
mSendSocket = mContext.createSocket(SocketType.PUSH);
mSendSocket.setLinger(0);
mSendSocket.connect(url + mPort);
mRecvSocket = mContext.createSocket(SocketType.SUB);
mRecvSocket.setLinger(0);
mRecvSocket.subscribe(mIdentity.getBytes(CHARSET_NAME));
mRecvSocket.connect(url + mPortOut);
}对应python版的构造函数:
def __init__(self, ip='localhost', port=5555, port_out=5556,
output_fmt='ndarray', show_server_config=False,
identity=None, check_version=True, check_length=True,
check_token_info=True, ignore_all_checks=False,
timeout=-1):
self.context = zmq.Context()
self.sender = self.context.socket(zmq.PUSH)
self.sender.setsockopt(zmq.LINGER, 0)
self.identity = identity or str(uuid.uuid4()).encode('ascii')
self.sender.connect('tcp://%s:%d' % (ip, port))
self.receiver = self.context.socket(zmq.SUB)
self.receiver.setsockopt(zmq.LINGER, 0)
self.receiver.setsockopt(zmq.SUBSCRIBE, self.identity)
self.receiver.connect('tcp://%s:%d' % (ip, port_out))
....
....
收发数据
收发数据对应python版里的_send()和_recv()函数,两者代码如下
def _send(self, msg, msg_len=0):
self.request_id += 1
self.sender.send_multipart([self.identity, msg, b'%d' % self.request_id, b'%d' % msg_len])
self.pending_request.add(self.request_id)
return self.request_id
def _recv(self, wait_for_req_id=None):
try:
while True:
# a request has been returned and found in pending_response
if wait_for_req_id in self.pending_response:
response = self.pending_response.pop(wait_for_req_id)
return _Response(wait_for_req_id, response)
# receive a response
response = self.receiver.recv_multipart()
request_id = int(response[-1])
# if not wait for particular response then simply return
if not wait_for_req_id or (wait_for_req_id == request_id):
self.pending_request.remove(request_id)
return _Response(request_id, response)
elif wait_for_req_id != request_id:
self.pending_response[request_id] = response
# wait for the next response
except Exception as e:
raise e
finally:
if wait_for_req_id in self.pending_request:
self.pending_request.remove(wait_for_req_id)
_send()函数里主要调用了发送套接字的send_multipart()函数,把identity、msg、request_id和msg_len作为列表发送过去,java里没有直接对应send_multipart()的方法,可以用sendMore()和send()代替
同样,_recv()函数里主要调用了接收套接字的recv_multipart()函数,java中也没有直接对应的方法,可以用recvMore()代替,最后可以写出java版代码如下
public long send(String message) {
return send(message, 0);
}
public long send(String message, int messageLen) {
return send(new String[]{message}, messageLen);
}
public long send(String[] message, int messageLen) {
mRequestId++;
Gson gson = new Gson();
sendMultiPart(new String[]{mIdentity, gson.toJson(message), mRequestId + "", messageLen + ""});
mPendingRequest.add(mRequestId);
return mRequestId;
}
private void sendMultiPart(String[] msgParts) {
try {
int i;
for (i = 0; i < msgParts.length - 1; i++) {
mSendSocket.sendMore(msgParts[i].getBytes(CHARSET_NAME));
}
mSendSocket.send(msgParts[i].getBytes(CHARSET_NAME), 0);
} catch (Exception e) {
e.printStackTrace();
}
}
public Map recv() {
return recv(null);
}
public Map recv(Long waitForReqId) {
try {
while (true) {
if (waitForReqId != null && mPendingResponse.containsKey(waitForReqId)) {
List response = mPendingResponse.get(waitForReqId);
HashMap resultMap = new HashMap();
resultMap.put(KEY_ID, waitForReqId);
resultMap.put(KEY_CONTENT, response);
return resultMap;
}
List response = recvMutipart(0);
if (response == null || response.size() == 0) {
return null;
}
long requestId = Utils.byte2Long(response.get(response.size() - 1));
if (waitForReqId == null || waitForReqId == requestId) {
mPendingRequest.remove(requestId);
HashMap resultMap = new HashMap();
resultMap.put(KEY_ID, requestId);
if (response != null) {
resultMap.put(KEY_CONTENT, response);
}
return resultMap;
} else if (waitForReqId != requestId) {
mPendingResponse.put(requestId, response);
}
}
} catch (Exception e) {
e.printStackTrace();
} finally {
if (waitForReqId != null && mPendingRequest.contains(waitForReqId)) {
mPendingRequest.remove(waitForReqId);
}
}
return null;
}
private List recvMutipart(int flag) {
ArrayList result = new ArrayList();
byte[] item = mRecvSocket.recv(flag);
if (item != null) {
result.add(item);
}
while (mRecvSocket.hasReceiveMore()) {
item = mRecvSocket.recv(flag);
if (item != null) {
result.add(item);
}
}
return result;
}
注意send()方法中,发送消息时,一定要用gson把消息字符串转换成json格式,否则服务端会报错,客户端收不到数据
自定义的sendMultiPart()方法中,把字符串编码成字节数组时用的编码格式是utf-8,用了自定义常量显示
在接收回复时,根据python版的代码可知,每一个回复的最后一部分是发送消息时对应的请求id,可以采取措施把byte[]数组转换成Long,具体代码如下
public static long byte2Long(byte[] bytes) {
if (bytes == null) {
return -1L;
}
StringBuilder builder = new StringBuilder();
for (int i = 0; i < bytes.length; i++) {
builder.append(bytes[i] - 48);
}
return Long.parseLong(builder.toString());
}比如收到的字节数组是[49, 48],显然对应的请求id是10,那么由上面的byte2Long方法就可以进行转换
encode
收发数据完成之后,就可以着力实现encode、fetch、fetchAll和encodeAsync四个方法了。
encode编码字符串,在调试python版的客户端后发现,encode编码的字符串必须首先转换成字符串数组,比如"szc"要转换成["s", "z", "c"]。根据这一点,以及python版代码,可以写出java版encode()方法和重载方法
public List显然最下面的方法是最终的方法,先把要编码的字符数组发给服务端,获取这次的requestId,然后判断是否阻塞,否的话,说明没必要等这一次编码返回,阻塞的话,则是多次编码之间要串行执行。然后调用recvNdarray()方法获取编码结果,Python版里返回的是一个namedtuple,对应java里的映射。那么我们就来实现这个recvNdarray()
python版的recv_ndarray()方法如下
def _recv_ndarray(self, wait_for_req_id=None):
request_id, response = self._recv(wait_for_req_id)
arr_info, arr_val = jsonapi.loads(response[1]), response[2]
X = np.frombuffer(_buffer(arr_val), dtype=str(arr_info['dtype']))
return Response(request_id, self.formatter(X.reshape(arr_info['shape'])), arr_info.get('tokens', ''))
首先调用recv()方法获取request_id和response,这也是为什么java版里recv方法返回的是一个映射的原因
然后jsonapi.load()方法其实就是把byte[]数组转换成json字符串,赋值给arr_info;response[2]直接赋给arr_val,然后根据arr_info中dtype的值,把arr_val转换成float数组或列表,最后把request_id、float数组或列表和tokens组成命名元组返回出去。
明白原理后,可以写出Java版代码如下
public Map recvNdarray(Long waitForReqId) {
HashMap recvMap = (HashMap) recv(waitForReqId);
if (recvMap == null || !recvMap.containsKey(KEY_CONTENT)) {
return null;
}
long requestId = Long.parseLong(String.valueOf(recvMap.get(KEY_ID)));
List content = (List) recvMap.get(KEY_CONTENT);
JSONObject jsonObject = new JSONObject(new String(content.get(1)));
String type = jsonObject.getString("dtype");
if (type.contains("float")) {
HashMap retMap = new HashMap();
retMap.put(KEY_ID, requestId);
retMap.put("embedding", Utils.byte2float(content.get(2)));
retMap.put("tokens", jsonObject.optString("tokens", " "));
retMap.put("shape", jsonObject.get("shape"));
return retMap;
}
return null;
} 编码结果存储在embedding里,这里需要把byte数组转换成float数组。服务端返回的byte数组按小端排序,然后根据float4个字节的大小,可以进行byte数组到float数组的转换
public static ArrayList byte2float(byte[] bytes) {
int resultStrLen = bytes.length;
if (resultStrLen % 4 != 0) {
int byteCount = resultStrLen / 4;
int margin = resultStrLen - 4 * byteCount;
if (byteCount > 0) {
bytes = Arrays.copyOfRange(bytes, 0, 4 * byteCount - margin);
}
}
ArrayList resultArray = new ArrayList<>();
for (int i = 0; i < bytes.length; i += 4) {
byte[] newBytesFour = Arrays.copyOfRange(bytes, i, i + 4);
resultArray.add(ByteBuffer.wrap(newBytesFour).order(ByteOrder.LITTLE_ENDIAN).getFloat());
}
return resultArray;
} 先把后面不够4字节的去掉,然后按照4:1的比例进行解码,就可以得到浮点数列表。
这样,encode的主要任务就完成了,然后把映射里embedding(也就是浮点数列表)、shape、token作为列表返回到外部,就可以了。
fetch和fetchAll
然后看一下python里的fetch和fetchAll
def fetch(self, delay=.0):
time.sleep(delay)
while self.pending_request:
yield self._recv_ndarray()
def fetch_all(self, sort=True, concat=False):
if self.pending_request:
tmp = list(self.fetch())
if sort:
tmp = sorted(tmp, key=lambda v: v.id)
tmp = [v.embedding for v in tmp]
if concat:
....
return tmp
可见,fetch里用到了协程,统一已向服务端发送但没有获取结果的请求获取结果,而fetch_all充其量只是做了一个排序。这样的话,既然是为了实现异步,我们可以用java里的多线程来实现,对应代码如下
public void fetch(long delay, final IFetchCallback fetchCallback) {
try {
if (delay > 0L) {
Thread.sleep(delay);
}
mExecutorService.submit(new Runnable() {
@Override
public void run() {
ArrayList> fetchResults = new ArrayList<>();
while (mPendingRequest.size() > 0) {
Map recvMap = recvNdarray();
if (recvMap != null) {
fetchResults.add(recvMap);
}
}
if (fetchCallback != null) {
fetchCallback.onFetchResult(fetchResults);
}
}
});
} catch (Exception e) {
e.printStackTrace();
}
} IFetchCallback是自定义的接口类,用来处理结果
encodeAsync
接下来是异步编码,python版代码如下
def encode_async(self, batch_generator, max_num_batch=None, delay=0.1, **kwargs):
def run():
cnt = 0
for texts in batch_generator:
self.encode(texts, blocking=False, **kwargs)
cnt += 1
if max_num_batch and cnt == max_num_batch:
break
t = threading.Thread(target=run)
t.start()
return self.fetch(delay)用协程+多线程实现异步编码。batch_generator可以看成是一批待编码的字符串,也就是字符串数组,然后启动子线程遍历字符串数组,采用非阻塞方式编码,根据上面的python版encode函数,可以看到其实就是只发送数据,不接收结果,结果在服务端保存。最后调用fetch()方法统一获取编码结果,返回出去。
同样采取线程池的方法实现之
public void encodeAsync(final String[] texts, final boolean blocking, final boolean showTokens
, final long delay, final IEncodeResult encodeCallback, final IFetchCallback fetchCallback) {
try {
mExecutorService.submit(new Runnable() {
@Override
public void run() {
List> encodeResults = new ArrayList<>();
for (int i = 0; i < texts.length; i++) {
List IEncodeCallback也是自定义接口类,负责输出编码结果。
测试
先测试能否编码成正确的浮点数列表。
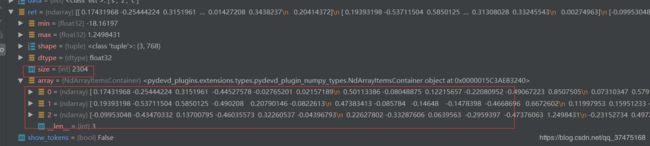
编码相同的字符串“szc”,看一下python版和java版的embedding结果:
python:
java:
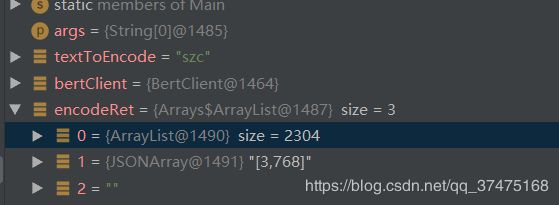

可见,数组大小和内容完全一样,编码功能实现。
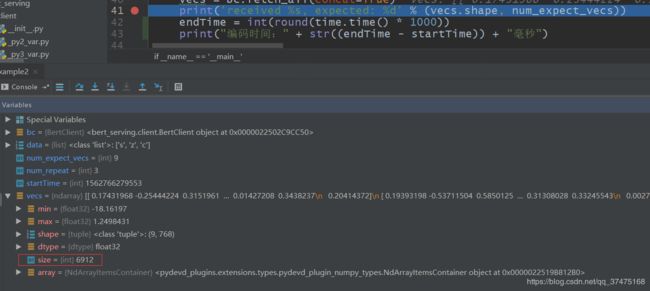
再测试能否正确获取没有获取数据的请求,先把"szc"发三遍,不接收,再fetch_all或fetch,看看数组大小对不对即可
python版
java版
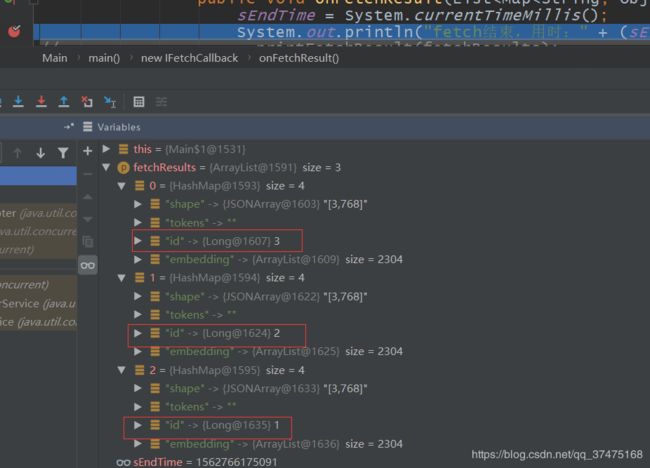
java版返回了三个映射,一个映射里有一个大小为2304的结果列表;而python版直接返回了大小为6912的ndarray,大小对的上,说明异步获取结果也实现了
最后测一下异步编码,同样发三遍szc再fetch,看最后的编码结是否正确
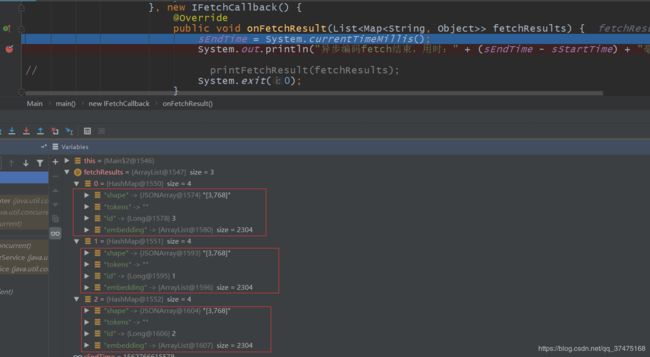
没问题,至此Java重构bertClient就算完成了。
踩过的坑
java.lang.UnsatisfiedLinkError: org.zeromq.ZMQ$Socket.nativeInit()V
不要用jzmq,改成jeromq,参见最上面的依赖
结语
这几天重构的过程中,发现python里很多东西就像耍赖一样,比如默认参数、无类型声明、命名元组等,类型变化防不胜防,但随之而来的是运行速度的下降,或许这就是失之东隅,收之桑榆吧。