逻辑回归python实现
1.问题
使用线性回归怎么解决分类问题?这就是逻辑回归要做的事情,并且逻辑回归可以计算出概率
2.模型以及求解(线性)
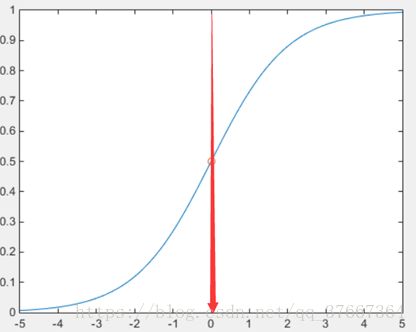
给出一组m个样本数据,每个样本数据有n个特征,并且带有标记0或者1,代表属于哪一类,为了把输入的参数代入到预测函数后始终是一个0到1之间的数,这样我们可以把0,1看做两个类别, 引入sigmod函数 1/(1+e^-t) 这个函数的函数值始终是在0到1之间
让sigmoid函数中的t等于:xi代表某个样本,θ是一组参数
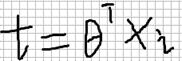
其中θ就是我们需要训练得到的参数
那么代价函数是什么呢?
当实际的y=1,而给出的预测值是0时,代价函数需要付出很大 的代价
当实际的y=0,而给出的预测值是1时,代价函数同样需要付出很大的代价
这样,给出以下的代价函数:画出图形后很容易看出下面的函数具有我们需要的特性
y = 1, -log(p)
y= 0, -log(1-p)
其中,p是预测得到的y的值,也就是 sigmod(θ*Xi)
综合上面这两个式子,我们写成一个那么cost = y * -log(p) + (1-y)* -log(1-p)
那么J(θ) = -1/m * E yi * log(sigmod(θ*xi)) + (1-yi) * log(1-sigmod(θ*xi))
容易求得:
![]()
其中yi就是代表第i个样本的实际y值,而xi代表第i个样本的数据(包含多个特征),i从1到m,E为求和符号
注:求解θ参数只能使用梯度下降这种方法
梯度的更新:
l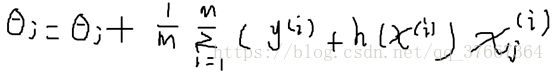
具体求解过程使用梯度下降已经在线性回归中讲过,不再赘述
3.非线性
上面做法是找到一条直线划分类别,如果线性不可分同样可以引入多项式解决这个问题,如果出现过拟合可以使用正则项
4.多分类问题
- one vs rest(一对多):比如有a,b,c3类,把a看做1类,其余的看做一类,把b看做一类,其余的看做一类....这样可以分别训练出三个模型出来,就可以解决多分类模型,如果有n个类别,训练出n个模型,特点:耗时少,但是效果不如one vs one
- one vs one(一对一): 比如有a,b,c3类,把(a,b),(a,c),(b,c)分别做逻辑回归,如果有n个类别就需要(n个中选2个/排列组合C(n,2))个模型,特点:耗时多,但效果更好
5.应用
CTR预估/推荐系统的learning to rank/各种分类场景
6.算法实现
# coding: utf-8
import numpy as np
import math
from sklearn import datasets
from collections import Counter
infinity = float(-2**31)
'''
2018-8-5
逻辑回归的实现
'''
def sigmodFormatrix(Xb,thetas):
params = - Xb.dot(thetas)
r = np.zeros(params.shape[0])#返回一个np数组
for i in range(len(r)):
r[i] = 1 /(1 + math.exp(params[i]))
return r
def sigmodFormatrix2(Xb,thetas):
params = - Xb.dot(thetas)
r = np.zeros(params.shape[0])#返回一个np数组
for i in range(len(r)):
r[i] = 1 /(1 + math.exp(params[i]))
if r[i] >=0.5:
r[i] = 1
else:
r[i] = 0
return r
def sigmod(Xi,thetas):
params = - np.sum(Xi * thetas)
r = 1 /(1 + math.exp(params))
return r
class LinearLogsiticRegression(object):
thetas = None
m = 0
#训练
def fit(self,X,y,alpha = 0.01,accuracy = 0.00001):
#插入第一列为1,构成xb矩阵
self.thetas = np.full(X.shape[1]+1,0.5)
self.m = X.shape[0]
a = np.full((self.m,1),1)
Xb = np.column_stack((a,X))
dimension = X.shape[1]+1
#梯度下降迭代
count = 1
while True:
oldJ = self.costFunc(Xb, y)
#注意预测函数中使用的参数是未更新的
c = sigmodFormatrix(Xb, self.thetas)-y
for j in range(dimension):
self.thetas[j] = self.thetas[j] -alpha * np.sum(c * Xb[:,j])
newJ = self.costFunc(Xb, y)
if newJ == oldJ or math.fabs(newJ - oldJ) < accuracy:
print("代价函数迭代到最小值,退出!")
print("收敛到:",newJ)
break
print("迭代第",count,"次!")
print("代价函数上一次的差:",(newJ - oldJ))
count += 1
#预测
def costFunc(self,Xb,y):
sum = 0.0
for i in range(self.m):
yPre = sigmod(Xb[i,], self.thetas)
#print("yPre:",yPre)
if yPre ==1 or yPre == 0:
return infinity
sum += y[i]*math.log(yPre)+(1 - y[i])*math.log(1-yPre)
return -1/self.m * sum
def predict(self,X):
a = np.full((len(X),1),1)
Xb = np.column_stack((a,X))
return sigmodFormatrix2(Xb, self.thetas)
def score(self,X_test,y_test):
y_predict = myLogstic.predict(X_test)
re = (y_test==y_predict)
re1 = Counter(re)
a = re1[True] / (re1[True]+re1[False])
return a
#if __name__=="main":
from sklearn.model_selection import train_test_split
iris = datasets.load_iris()
X= iris['data']
y = iris['target']
X = X[y!=2]
y=y[y!=2]
X_train,X_test, y_train, y_test = train_test_split(X,y)
myLogstic = LinearLogsiticRegression()
myLogstic.fit(X_train, y_train)
y_predict = myLogstic.predict(X_test)
print("参数:",myLogstic.thetas)
print("测试数据准确度:",myLogstic.score(X_test, y_test))
print("训练数据准确度:",myLogstic.score(X_train, y_train))
'''
2.sklean中的逻辑回归
'''
from sklearn.linear_model import LogisticRegression
print("sklern中的逻辑回归:")
logr = LogisticRegression()
logr.fit(X_train,y_train)
print("准确度:",logr.score(X_test,y_test))