01-基于TensorFlow的自定数据的三分类案例
一、前言:
由于笔者前段时间学习TensorFlow一直以看书为重心,并没有很好的把学习到的知识转变为具体的应用中来,并且前一段时间,为了准备期末考试,很多内容都没有得到很好的记忆,为了贯穿相关知识,所以本系列博文将以实际案例为导向,结合自身所学知识和具体的应用来熟悉TensorFlow的运行机理和函数原理。本篇为第一篇,主要应用点是由机器学习拓展到深度学习中比较重要的一环,即从机器学习中的Logistic分类器拓展到深度学习softmax分类器,也就是把二分类任务拓展到多分类任务的实践。其中还穿插介绍TensorFlow的相关基础知识点。希望在接下来的实践中能最大限度的把自身所学和实践结合起来,给自己一个满意的答卷。
另外,笔者处于焦灼的学习阶段,有什么问题请指正。
二、任务目标
使用softmat分类器进行三分类的任务,具体实现内容如下:
1. 产生自变量x,其有三个特征值,一个因变量y,y的取值有1,2,3,并转化为One-Hot编码
2. 给定任意一函数 y=θ0+θ1*X1+θ2*X2+θ3*X3,这里使用函数(f(X1,X2,X3)=3+7X1-4X2-X3 )作为判别标准,当f(X1,X2,X3)<0的时候,y的值取1,当0<=f(X1,X2,X3)<=5的时候,y的值取2,当f(X1,X2,X3)>5的时候,y的值取3.
3. 指定不同的设备运行不同的节点
4. 模型的保存和加载,以致于能在程序中断之后可以通过重载来从保存的节点进行下一次的训练
5. tensorboard可视化界面的启用来梳理网络的构成
三、任务主要内容
1. 模拟数据构成
#设置产生500条样本
n=500
#设置x为数据输入,其形状为500×3 的array
x_data=np.random.uniform(low=-5,high=5,size=(n,3))
#计算公式化的数据y输出
y_data=np.dot(x_data,np.array([[7],[-4],[-1]]))
#y_data[y_data>=0 and y_data<=5]=1
y_data[y_data>5]=2
y_data[y_data<0]=0
y_data[y_data%1!=0]=1
#这里将y_data的array数据修改为one-hot编码,编码后通过toarray的方法返回一个one-hot类型的数组
y_data=OneHotEncoder(sparse=True).fit_transform(y_data).toarray().
2. 模型构建过程
#x,y定义为占位符,作为模型的输入接口
#根据所构建的数据集来定义占位符的shape为(None,3)
x=tf.placeholder(tf.float32,[None,3],'x_ph')
y=tf.placeholder(tf.float32,[None,3],'y_ph')
#权重和偏执项的节点构建
w=tf.Variable(tf.ones([3,3]),dtype=tf.float32,name='w')
b=tf.Variable(tf.ones([3]),dtype=tf.float32,name='b').
3. 使用tf.nn.softmax 得到一个3分类的概率值
probability=tf.nn.softmax(tf.matmul(x,w)+b).
4. 计算损失函数并设置最小化损失函数的方式
#构建交叉熵损失函数
loss=tf.reduce_mean(-tf.reduce_sum(y*tf.log(probability),axis=1))
#loss=tf.nn.softmax_cross_entropy_with_logits(labels=y_hat,logits=y_pre,name='loss')
#设置学习率
learn_rate=0.01
#使用一般梯度下降方法的优化器
optimizer=tf.train.GradientDescentOptimizer(learning_rate=learn_rate)
train=optimizer.minimize(loss,name='train').
5. 计算准确率
#tf.argmax(probability,axis=1) 按行取概率最大的数的列索引信息
#tf.argmax(y_data,axis=1) 实际按行取最大的数的列索引信息
#tf.equal 用于判断左右两边的列索引信息是否相同,相同则分类正确
equal=tf.equal(tf.argmax(probability,axis=1),tf.argmax(y,axis=1))
#取均值计算正确率
correct=tf.reduce_mean(tf.cast(equal,tf.float32)).
6. 创建Session()前的准备
#建立初始化变量init
init=tf.global_variables_initializer()
#创建easy_print方法
def easy_print(p_epoch,p_train_epochs,p_loss,p_accuracy):
print("迭代次数:{}/{}, 损失值:{},训练集上的准确率:{}".format(p_epoch,p_train_epochs,p_loss,p_accuracy))
#定义总迭代次数
training_epochs=5000
#定义小批量梯度下降的值为10,即使用10条数据迭代一次权重项和偏置参数
batch_size=int(n/10).
7. 创建Session()会话,训练模型
with tf.Session(config=tf.ConfigProto(log_device_placement=True,allow_soft_placement=True)) as sess:
#变量初始化
sess.run(init)
print(sess.run(loss,feed_dict={x:x_data[1:10],y:y_data[1:10]}))
#迭代训练
for epoch in range(training_epochs):
#打乱数据集的顺序,返回数据集的索引信息
#使得每次迭代使用的数据不一致,提高数据的复用
p_loss=0
p_correct=0
index=np.random.permutation(n)
for i in range(batch_size):
#获取训练集索引信息
train_index=index[i*10:(i+1)*10]
#feed传入参数,并进行模型训练
sess.run(train,feed_dict={x:x_data[train_index],y:y_data[train_index]})
#获取损失值,这里计算的是每一个epoch下的batch_size次迭代的平均损失值
p_loss+=sess.run(loss,feed_dict={x:x_data[train_index],y:y_data[train_index]})/batch_size
#计算模型的正确率
p_correct+=sess.run(correct,feed_dict={x:x_data[train_index],y:y_data[train_index]})/batch_size
easy_print(epoch,training_epochs,p_loss,p_correct)
result=sess.run([w,b])
print("最终模型参数为:w={},\nb={}".format(result[0],result[1]))
print("模型训练完成")
四、补充内容
1. 模型的保存和重载(这里需要在相应位置添加)
#定义模型的存储对象
saver=tf.train.Saver()
#=================================
if training_epochs%100==0:
saver.save(sess,'softmax-model/model.ckpt')
#=================================
#重新创建一个Session()用于测试重载
with tf.Session() as sess:
saver.restore(sess,'softmax-model/model.ckpt')
print(sess.run([w,b])).
2. tensorboard可视化(同样在对应位置添加代码段)
#记录信息
tf.summary.scalar('w',w)
tf.summary.scalar('x_ph',x)
tf.summary.scalar('y_ph',y)
tf.summary.scalar('b',b)
#==========================================
#merge all summary
merged_summary=tf.summary.merge_all()
#输出文件,并创建writer对象
writer=tf.summary.FileWriter('./w_summary',sess.graph)
#===========================================然后改目录会自动创建一个名为w_summary的目录
目录下面有events.out.tfevents.1531106711.dream-T7610的文件
然后在终端启用tensorboard
tensorboard --logdir=w_summary然后在浏览器中输入localhost:6006
会显示如下页面
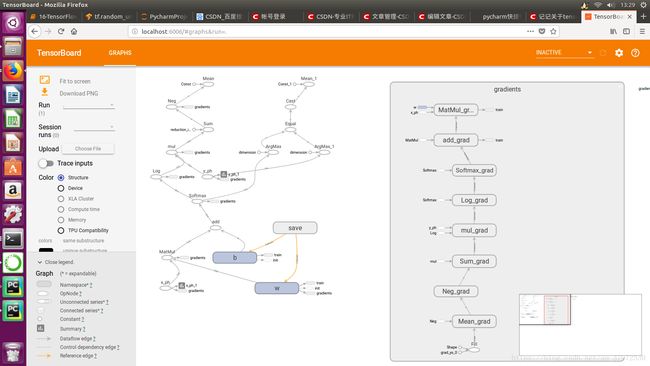
.
3. 指定CPU或者GPU运行
#指定节点运行在设备上
with tf.device('/cpu:0'):
#这里定义节点信息
'''
......
'''这里具体的内容就不贴上去了,在以后的编写过程中会有更加详细的信息。
这里的代码其实并不是特别精简与完善,因为很多库的使用不是特别的熟练,还需要多加练习。如果有更加好的意见和建议希望拿出来一起学习与分享。
tips:这里做的三分类实际上是做的线性分类任务,精确度相对没有特别高,如果需要高的精确度的分类信息,读者可以尝试增加隐层的层数,另外选择合适的激活函数以提供非线性的因素等内容。