CockroachDB中一个query是如何执行的?
CockroachDB
-
CockroachDB架构:

Postgres wire protocol
client和客户端之间用pgsql的协议通信,用户连接由pgwire包的pgwire.v3conn.serve()维持,它负责读取query,将query发给sql.Executor处理,然后收集结果返回给client。
SQL Executor
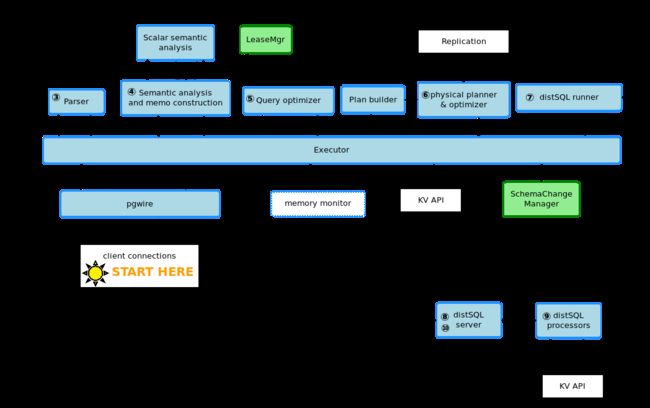
sql.executor的主要工作是1.解析SQL语句,将解析结果发往后面的模块,然后收集结果返回给pgwire.v3conn。2.协调SQL层其他组成部分,如下面的parser等。3.每个连接都有相应的一个sql.session,包含当前连接的事务的状态,参数的设置等信息,executor也负责更新session的信息。4.对失败的事务(底层传回来的错误信息)进行自动retry,对于不能自动retry的事务通过pgwire传回给client retry,即distSQL返回的result为retry error时:
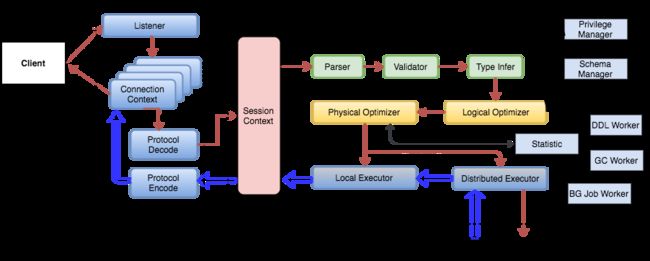
TiDB的SQL层架构也差不多:
-
Parsing,executor的调用的第一个模块,负责将SQL字符串转化为AST树,转化规则使用PGSQL的yacc语法。
-
Logical plan,根据AST树来生成由
planNode组成的logical plan,具体的可以看SQL层的文档,planNode中的负责读取数据的scanNode等有rowFetcher方法,主要是用来将SQL request转化成KV request(比如scanRequest查询的key从哪里到哪里),并负责将收集到的KV结果decode,然后转给之后的planNode。 -
TxnCoornSender,形成的logical plan将发送给Txn sender,这里是一个事务的开始,这个sender会在这个事务中使用的最多的system range里新建一个transaction record,然后不断的异步发送heartbeat来更新record的状态;sender同时也会收集下层传回来的改动过的key或者range,以在commit或者abort事务后异步清理write intent,同时如果有其他事务碰到了这种intent也会在一个heartbeat的时延里来跟txn record确认状态然后进行清理。
txn sender随后将request发送给
DistSender。 -
DistSender,这里可以看成是分布层,主要负责request的分发。request的分发需要读取range元数据信息,range的元数据信息是system range,是两层结构分别是meta1和meta2,有着前缀/0x1和/0x2,因而永远是排在所有的node的range的最前面。meta里的每条KV对都包含一个range的元信息,其中meta1存储的是meta2的元信息,meta2存储的是普通range的元数据,元信息主要包括了该range的最后一个key的值,range的replica分布在哪些node:
Range 0 (located on servers
dcrama1:8000,dcrama2:8000,dcrama3:8000)-
meta1\xff:dcrama1:8000,dcrama2:8000,dcrama3:8000 -
meta2:dcrama1:8000,dcrama2:8000,dcrama3:8000 -
meta2:dcrama4:8000,dcrama5:8000,dcrama6:8000 -
meta2\xff:dcrama7:8000,dcrama8:8000,dcrama9:8000
一条元信息为256K,一个range默认64M,可以管理64M/256K一共2^18条元数据,而meta range一共分为两级(meta1只有一个range),因而一共2^36为4EB的数据一个集群可以管理。
meta range跟普通range一样都是默认三个replica分布在cluster中。
分发request需要从meta range中获得replica所在node,一般有两种方法获得node信息,一种是通过range cache,这是一个LRU LIST,保存了最近最多使用的range元信息,不过这些信息有可能不是最新的,因而当在node没有找到目标range时会返回error到这里重新查找,并在LRU中删除对应range元信息;第二个方法在cache中没有找到或者找到的信息发现不正确后使用,即从meta range所在的node中远程读取数据,则从硬盘中读取meta range的数据来进行查找。
获得各个range的位置信息后,根据位置将request各部分分发给各个node,这里由logical plan形成physical plan,每个node自己的request的流程是怎么与其他node的流程相联系的在这里形成,每个node自己的一系列流程称之为flow,node之间通过gRPC传输数据流,一般来讲node间的gRPC连接在flow执行过程中就建立了,如果timeout之后仍然没有flow通过这个连接发送数据那么该连接就会作废,需要注意的是不是每一个flow都会有一个RPC连接,一般是node间有一个连接,每个flow的数据都在这个连接中传输,按序号进行分类,比如下图:

比如三个node一起做join的physical plan:

这里三个node分别读取两个表的数据,然后根据join using的字段将数据流hash到不同的node,这样该字段相同的部分就会在同一node,从而可以做join操作,node间数据流的传输就是通过gRPC。
physical plan形成后需要确定每个range的lease holder是哪一个node,这里通过lease cache来找到replica的lease holder,同样这个cache的信息依然可能不准确,因而sender会依次将前面找出来的replica所在的所有node都发送request,顺序按照为lease的可能性排列,cache中找出来的排在最前面,顺序发送直到接收到成功应答。
-
Other Node
这里开始事务进行在协调节点之外。
-
Store,request分发到node后需要确定到底该node的哪一个store包含该range,每个node的内存中都cache了每个store的range信息,通过它可以找到对应store,如果没有找到对应的store,说明之前range cache的元信息是错误的,返回错误到这里重新查找元信息。
确定了store以后开始执行分发的flow,一般来讲flow最开始都是读取数据或者write数据,read或者write在更下层进行,这层提供了一个loop使用方法
intentResolver来处理部分下层因为intent冲突返回的retry error,一般是write碰到了timestamp在前的write intent,loop会一直轮询intent的状态是否从pending变为commit或者abort(有些文档说以后可能会加事务等待队列而不是通过轮询,有些文档说已经实现该功能,所以说很操蛋),状态改变后在继续该事务,其他一些不能处理的retry error比如write碰到了刚提交的intent的timestamp较大的情况,则将error一层层向上返回到executor由它控制根据error类型选择push timestamp或者改变priority来retry事务。 -
Raft,不管flow最开始是read还是write,都需要经过raft。crdb对raft进行了一些改进,主要的是:1.增加了lease holder的概念,并且与tidb不同的是,crdb的lease跟leader是分离的,甚至可以不再同一个node(不过为了减少时延,总是会把lease和leader选在一起)。如果在请求到来时当前没有lease,则该replica就会申请成为lease,过程与leader选举一样,如果group已有lease,则返回一个error并将已知的lease holder同时返回。lease的持续时间存储在一个system table中,每个lease都会定时的heartbeat该table以更新持续时间。通过lease,read可以不再走raft流程,而是就地解决。2.lease的heartbeat不再是每个group都有一个heartbeat,而是node间维持一个heartbeat,这两个node间的group都使用这个连接;此外write的request的可以组成batch来传给follower,然后异步的等待ack,而不是每传一个request就要等follower返回;此外leader的append log跟发送给follower log可以并行执行。3.采用lazy initialization,只有有写入事件时才会激活lease选举,长期没有write会让raft group进入quiet状态,不再进行lease选举。lease在这一层维护一个timestamp cache,记录所有该replica的读操作的timestamp,当有写操作在这一lease时,会检查其timestamp是否小于cache里的,如果小于则会push写操作的timestamp并返回error到executor那里,retry事务。
当lease转变的时候,新的lease生成的timestamp cache可能会因为时钟偏差而小于以前的cache,所以在旧lease过期前的一段时间(timeout-timeoffset),lease将不能读和写。
现在我们回到lease开始处理request时,它会检查当前是否有其他事务正在使用这个lease,如果正在执行的事务跟该事务key的范围重叠,则会将后来的事务的request的放在
commandQueue里,等待之前的操作完成。当轮到该事务request进行时,分为读和写两种类型,读的话直接就在lease将request转化为rocksdb的操作比如puts,gets等,执行完成返回后更新timestamp cache,读在raft中的操作就执行完了;写的话则需要走一遍raft流程,首先检查timestamp cache,看是否有冲突,没有冲突则调用
replica.tryAddWriteCmd,这个方法会开始走raft流程,并一直阻塞直到lease的log被apply之后(并不是log commit之后),write的raft流程优化前面讲过,主要是大量request的可以并行发往follower,并且lease和follower的log可以并行append,当group中有多数的follower已经append log后,lease会commit log,并开始apply log。 -
MVCC Wrapper,这里主要是给rocksdb的get,put等操作加了一个wrapper,用来检测查询的key范围内是否有intent存在,根据intent所在的KV对的timestamp来判断intent造成的冲突是哪一种,如果不影响的则继续进行read或者write,如果有影响的则返回对应错误类型到上层处理。
crdb的文档没有具体讲各种version的数据到底是怎么存储的,不过我觉得应该跟tidb差不多,都是key最后带版本信息,按新版本到旧版本从上到下排列,扫描的时候应该会把key范围内所有版本数据扫出来然后判断每条是否有intent,然后根据每条的timestamp判断intent造成的冲突类型,具体哪几种冲突事务层文档有讲。
在判断完是否有intent冲突后,如果仍然没有返回错误,那么就根据timestamp来读取操作相应版本的数据,crdb是通过使用rocksdb提供的
iterator形成当前timestamp的snapshot。 -
在read或者write后继续执行flow中的其他步骤,当需要node间交换输出时则通过前面说的gRPC的mailbox来传输数据流,数据流的分配一般按hash分流,对于一些特殊情况可能会将该node的数据复制几份全部传给其他node。每个node的flow执行完成后也会通过mailbox将数据传回给gateway node,gateway node收集这些数据直到所有flow都执行完成,这些结果一级级的返回最后到client。
RocksDB
-
RocksDB主要包括三类重要结构:
-
MemTable,分为memtable和immutable memtable,区别是后者不可修改,只可读。memtable的数据结构是skiplist,类似与平衡树的平衡有序结构,但是是基于概率而不需要旋转等操作,每当新操作数据都插入到memtable中,当memtable达到一个界限就会变成immutable,并生成一个新的memtable已供插入。而变成immutable的memtable则由后台线程异步的刷新到level0的sstable中。
-
Log,主要是为了保证不丢失数据,对于每个memtable都有一个log,在写入memtable前都会先写入log,这样即使崩溃了memtable丢失,再重启时仍然能够恢复memtable。log文件是key无序的,因而每次写入都是顺序写入,不会对写入造成压力。
-
SSTABLE,用来在硬盘中持久化memtable中存储的KV对。sst是分层级的,从level0到levelN,从底层变成高层level需要进行compaction操作。sst主要分为两部分,一部分是data block,用来存储KV数据,一部分是索引block,存储每个data block最后一个key的值,block的位置以及大小
-
Manifest,也是一个重要的文件,主要是存储了各个sst的key的范围。
-
-
write操作,rocksdb写入很简单,只需要对log的一次顺序磁盘写入和一次logN时间复杂度的内存skiplist插入即可。需要注意的是rocksdb对更新还是删除还是插入,都不会改变原有记录,而是产生一条新的记录,比如删除就产生一条新纪录然后标记为删除,这些记录的回收在compaction时进行,compaction会根据一定的规则回收旧的记录,比如对一条记录进行了更新和删除,那么最后更新记录会被删除,只保留删除记录,不过rocksdb也提供了接口来让用户自己定义compaction filter的规则,crdb的按ttlseconds来回收旧记录应该就是用了这个接口。
-
read操作,rocksdb的读取要复杂很多,因为数据并不是都在memtable中,很多都写到了sst中,因而按照新鲜度来按顺序查找,顺序从memtable到level0再levelN。当memtable中找不到的时候需要去sst找,从sst找也有快捷的方法,主要是内存中有table cache和block cache,前一个cache存储了sst表名,指向sst文件的指针,指向存储在内存中的这个sst的索引数据以及cache id,通过manifest可以找到key在哪一个sst,然后查找table cache通过索引数据确定是哪一个block以及cache id,这时如果有block cache,那么通过cache id可以直接在其中找到对应block,如果没有则需要硬盘中读取sst然后找到该block。
level0的sst查找跟其他level不同,因为level0是直接memtable导入到硬盘的,因而可能存在key的范围重合的sst,故通过manifest将这些sst都找出来,然后按照新鲜度顺序遍历这些sst。当这个level没找到则继续遍历后续level的sst。
-
rocksdb中对于事务的处理有两种,一种是严格的带锁的事务,这种在一个事务操作数据时会加锁,另一个事务要操作这些数据时会block住,另一种是乐观的事务,不同事务都能够操作数据,但是在最后提交的时候会进行检查,如果有不同事务操作了数据,那么事务提交就不会成功。
对于crdb我觉得采用的是乐观的事务,因为它本身在raft部分的时候机会检查操作相同key范围的事务,会将其加入到等待队列commandQueue中。
-
compaction操作主要一个为了将内存中数据保存到硬盘中,一个是减少硬盘的冗余记录,经过compaction的sst将会提高一个level,rocksdb有三种compaction类型:1.universal compaction,这会一次性compaction整个level,然后与下一个level的重合的sst整合。2.level style compaction。3.FIFO compaction。
-
因为rocksdb这种组织特性,因而它对写入的支持要强于读取,理论的写入性能是40w+/S,而理论的读取性能是6W+/s。