图像语义分割(一)
- 1 图像语义分割的概念
- 2 语义分割的网络
- 2.1 FCN 全卷积网络
- 2.1.1 卷积化
- 2.1.2 上采样、跳跃结构
- 2.1.3 上采样的方法
- 2.1.4 FCN 的结果
- 2.2 Dilated Convolutions
- 2.2.1 膨胀卷积(Dilated Convolutions)
- 2.2.2 优点
- 2.3以条件随机场为代表的后处理操作
- 2.3.1 CRF 说明
- 2.4 解码器的变种(Decoder variants)
- 2.4.1 SegNet
- 2.4.1.1 上采样方式
- 2.4.1 SegNet
- 2.5 多尺度预测
- 2.6 特征混合
- 2.7 递归神经网络
- 2.7.1 ReSeg
- 2.1 FCN 全卷积网络
- 3 后续
- 4 参考
1 图像语义分割的概念
图像语义分割,简单而言就是给定一张图片,对图片上的每一个像素点分
类

2 语义分割的网络
2.1 FCN 全卷积网络
作者的FCN主要使用了三种技术:
- 卷积化(Convolutional)
- 上采样(Upsample)
- 跳跃结构(Skip Layer)
直接进行像素级别端到端(end-to-end)的语义分割,它可以基于主流的深度卷积神经网络模型(CNN)来实现。

2.1.1 卷积化
在FCN中,传统的全连接层 fc6 和 fc7 均是由卷积层实现,而最后的 fc8 层则被替代为一个 21 通道(channel)的 1x1 卷积层,作为网络的最终输出。之所以有 21 个通道是因为 PASCAL VOC 的数据中包含 21 个类别(20个object类别和一个「background」类别)。
2.1.2 上采样、跳跃结构
FCN 利用双线性插值将响应张量的长宽上采样到原图大小,另外为了更好的预测图像中的细节部分,FCN 还将网络中浅层的响应也考虑进来。就是将 Pool4 和 Pool3 的响应也拿来,分别作为模型 FCN-16s 和 FCN-8s 的输出,与原来 FCN-32s 的输出结合在一起做最终的语义分割预测(如下图所示)。

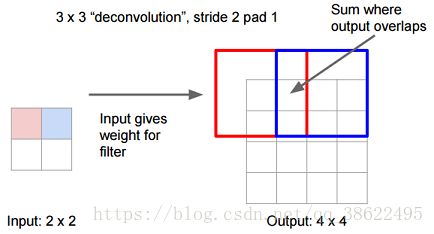
2.1.3 上采样的方法
FCN的架构使用了可学习的反卷积滤波器来上采样特征图。之后上采样的特征图被加入编码阶段产生的元素级的特征图中。
- 先进行上采样,即扩大像素;
- 再进行卷积——通过学习获得权值
- 卷积核尺寸大,一步到位
2.1.4 FCN 的结果
下图是不同层作为输出的语义分割结果,可以明显看出,由于池化层的下采样倍数的不同导致不同的语义分割精细程度。如 FCN-32s,由于是 FCN 的最后一层卷积和池化的输出,该模型的下采样倍数最高,其对应的语义分割结果最为粗略;而 FCN-8s 则因下采样倍数较小可以取得较为精细的分割结果。

2.2 Dilated Convolutions
FCN 的一个不足之处在于,由于池化层的存在,响应张量的大小(长和宽)越来越小,但是FCN的设计初衷则需要和输入大小一致的输出,因此 FCN 做了上采样。但是上采样并不能将丢失的信息全部无损地找回来。
池化层可以能增大上层卷积核的感受野,而且能聚合背景同时丢弃部分位置信息。然而,语义分割方法需对类别图谱进行精确调整,因此需保留池化层中所舍弃的位置信息。
对此,dilated convolution 是一种很好的解决方案——既然池化的下采样操作会带来信息损失,那么就把池化层去掉。但是池化层去掉随之带来的是网络各层的感受野(Receptive field)变小,这样会降低整个模型的预测精度。Dilated convolution 的主要贡献就是,如何在去掉池化下采样操作的同时,而不降低网络的感受野。
2.2.1 膨胀卷积(Dilated Convolutions)
以 3×3 的卷积核为例,传统卷积核在做卷积操作时,是将卷积核与输入张量中「连续」的 3×3 的 patch 逐点相乘再求和(如下图a,红色圆点为卷积核对应的输入「像素」,绿色为其在原输入中的感知野)。而 dilated convolution 中的卷积核则是将输入张量的 3×3 patch 隔一定的像素进行卷积运算。如下图 b 所示,在去掉一层池化层后,需要在去掉的池化层后将传统卷积层换做一个「dilation=2」的 dilated convolution 层,此时卷积核将输入张量每隔一个「像素」的位置作为输入 patch 进行卷积计算,可以发现这时对应到原输入的感知野已经扩大(dilate)倍 ;同理,如果再去掉一个池化层,就要将其之后的卷积层换成「dilation=4」的 dilated convolution 层,如图 c 所示。这样一来,即使去掉池化层也能保证网络的感受野,从而确保图像语义分割的精度。

感受野尺寸的扩充公式:
2.2.2 优点
扩展卷积在保持参数个数不变的情况下增大了卷积核的感受野,同时它可以保证输出的特征映射(feature map)的大小保持不变。一个扩张率为2的3×3卷积核,感受野与5×5的卷积核相同,但参数数量仅为9个,是5×5卷积参数数量的36%

2.3以条件随机场为代表的后处理操作
当下许多以深度学习为框架的图像语义分割工作都是用了条件随机场(Conditional random field,CRF)作为最后的后处理操作来对语义预测结果进行优化。
- CNN架构的空间变换无关性限制了分割任务中的空间准确性。
- CRFs能够将低级的图像信息如像素之间的交互,和多类推理系统的输出结合起来即每个像素的标签,结合起来。这种结合对于获取大范围的依赖关系是非常重要的。
- DeepLab模型利用全连接对级CRF作为一个独立的后处理阶段以增强分割效果。其将每个像素建模为场中的一个节点,对于每对像素,不管有多远都使用一个对级项(密集或全连接因子图)。
- 考虑了短程和长程的交互,有助于系统修复细节。
- 全连接模型较为低效,可以使用概率推理进行替代
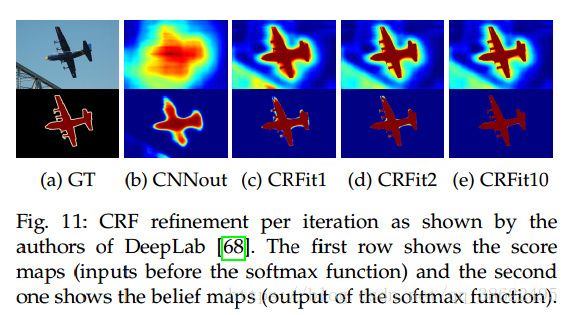
2.3.1 CRF 说明
在全链接的 CRF 模型中,对应的能量函数为:
其中, ψμ ψ μ 是一元项, 表示 xi x i 像素对应的语义类别, 其类别可以由 FCN 或者其他语义分割模型的预测结果得到; 而第二项为二元项,二元项可将像素之间的语义联系/关系考虑进去。例如,「天空」和「鸟」这样的像素在物理空间是相邻的概率,应该要比「天空」和「鱼」这样像素的相邻概率大。 最后通过对 CRF 能量函数的优化求解,得到对 FCN 的图像语义预测结果进行优化,得到最终的语义分割结果。值得一提的是,[3]已经将原本与深度模型训练割裂开的 CRF 过程嵌入到神经网络内部。即将 FCN+CRF 的过程整合到一个端到端的系统中,这样做的好处是 CRF 最后预测结果的能量函数可以直接用来指导 FCN 模型参数的训练,而取得更好的图像语义分割结果。
2.4 解码器的变种(Decoder variants)
- 编码:产生低分辨率的图像表示或特征映射的过程,将图像转化为特征;
- 解码:将低分辨率图像映射到像素级标签的过程,将特征转化为图像标签。
2.4.1 SegNet
SegNet由一系列上采样和卷积层组成,最后是一个softmax分类器预测像素级的标签,其输出与输入大小相同。解码阶段每个上采样层与编码阶段的最大池化相对应(上采样与最大池化使用类似的对应规则)。这些层使用编码阶段最大值池化所对应的特征映射,将特征映射为标签。特征图上采样后的结果,与一组训练好的滤波器组进行卷积产生密集特征图。当特征图恢复到原始的分辨率时,之后就通过softmax分类器产生最终的分割结果。
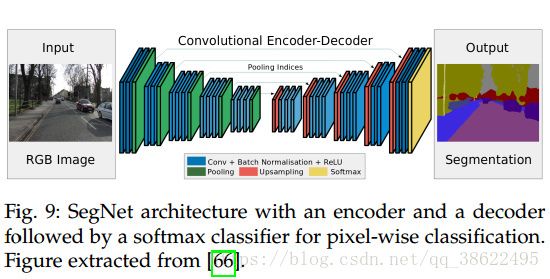
2.4.1.1 上采样方式
在SegNet中,进行最大池化时会记录该最大值所在位置,从而在上采样时,使用相同的位置关系将其映射到较大的特征图中,其余部分用零填充。
2.5 多尺度预测
CNNs中的每个参数都影响着特征图的尺度。滤波器存在只能检测特定尺度特征的危险(假设与角度无关)。参数也可能和当前问题有关,使模型难以泛化到不同的大小。其中一种解决方法就是使用多尺度的网络,生成多个尺度下的预测结构,之后将其结合到一个输出中。
- 基于VGG-16的多尺度全连接网络模型。该网络有两条路径,一条处理原始大小的图片,其网络较浅。另一条路径则处理二倍大小的图片,其网络结构为全连接的VGG-16和一个卷积层,其处理结果经过上采样与第一条路径的相结合。融合后的输出经过另一系列卷积层产生最终的输出。该网络对尺度变换鲁棒性较强。
- 另一种途径是使用由4种尺度结合的CNNs的方法。这4个网络具有相同的结构。其中的一个网络用于寻找场景的语义标签。该网络从粗到细粒度的提取特征。
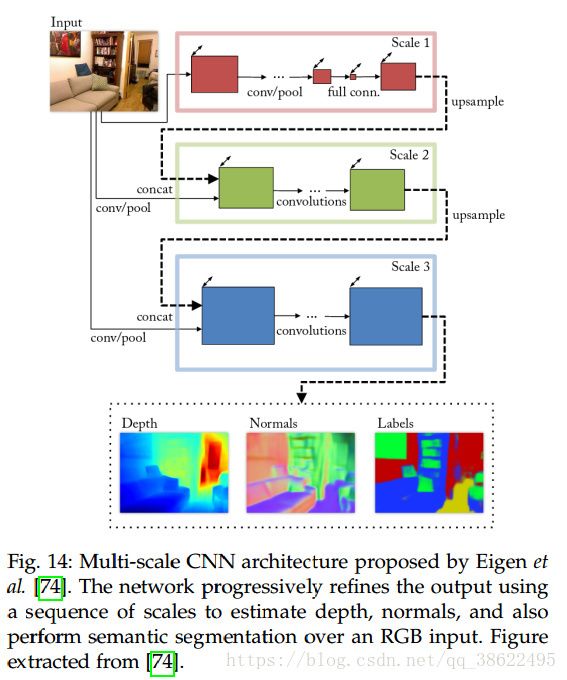
- 另一种网络结构是由n个在不同尺度上操作的FCNs组成。从网络中提取到的特征混合在一起(经过必要的上采样和填充),之后经过卷积层产生最终的分割结果。其主要贡献为两个阶段的学习过程。第一阶段,独立地训练各个网络,之后将网络组合到一起,对最后一层进行微调。这种多次度模型允许高效地添加任意数量的训练好的层。
2.6 特征混合
另一种向全卷积架构中加入上下文信息的方式是特征混合。
- 一种方法是将全局特征(从网络前一层中提取的)和从子序列中的局部特征相混合。通用的架构如原始的FCN使用跳跃连接(skip connections)来实现不同层特征图的混合。
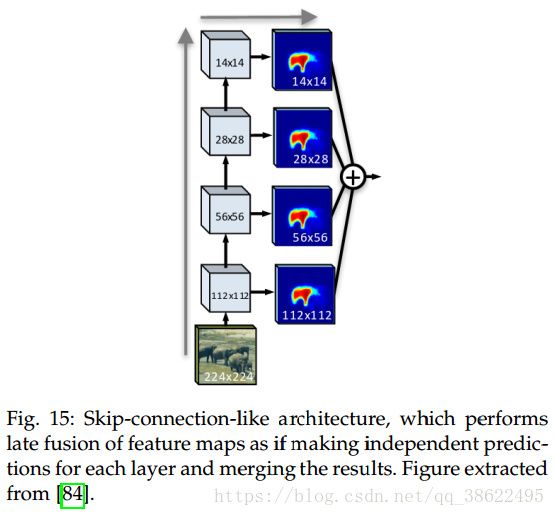
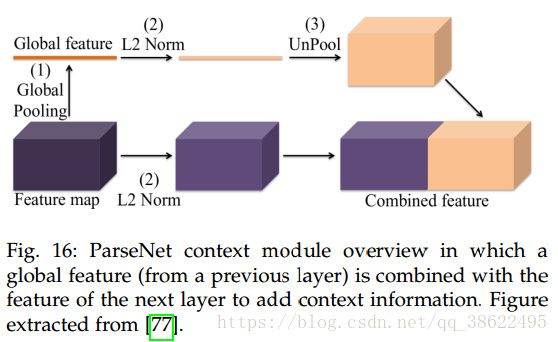
- 另一种方法是早期混合。全局特征被反池化为局部特征大小,之后混合产生用于下一层的特征
2.7 递归神经网络
2.7.1 ReSeg
ReSeg是基于ReNet的语义分割架构。输入图像经过VGG-16第一层处理,将特征图输入到多个ReNet层中进行微调。最后使用反卷积(transposed convolution)对特征图进行上采样。这种方法中门递归单元的使用能够减少内存占用和提高计算效率上。

长项依赖存在梯度消失的问题。一些衍生模型如LSTM( Long Short-Term
Memory ,长短期记忆)网络和GRUs可以避免这个问题。
3 后续
基于深度学习的图像语义分割技术虽然可以取得相比传统方法突飞猛进的分割效果,但是其对数据标注的要求过高:不仅需要海量图像数据,同时这些图像还需提供精确到像素级别的标记信息(Semantic labels)。因此,越来越多的研究者开始将注意力转移到弱监督(Weakly-supervised)条件下的图像语义分割问题上。在这类问题中,图像仅需提供图像级别标注(如,有「人」,有「车」,无「电视」)而不需要昂贵的像素级别信息即可取得与现有方法可比的语义分割精度。
另外,示例级别(Instance level)的图像语义分割问题(即实例分割)也同样热门。该类问题不仅需要对不同语义物体进行图像分割,同时还要求对同一语义的不同个体进行分割(例如需要对图中出现的九把椅子的像素用不同颜色分别标示出来) @ 实例分割
- FCN更像一种技巧。随着基本网络(如VGG, ResNet)性能的提升而不断进步。
- 深度学习+概率图模型(PGM)是一种趋势。其实DL说白了就是进行特征提取,而PGM能够从数学理论很好的解释事物本质间的联系。
- 概率图模型的网络化。因为PGM通常不太方便加入DL的模型中,将PGM网络化后能够是PGM参数自学习,同时构成end-to-end的系统。
特征融合的种类总结:
- FCN式的逐点相加,对应caffe的EltwiseLayer层,对应tensorflow的tf.add()
- U-Net式的channel维度拼接融合,对应caffe的ConcatLayer层,对应tensorflow的tf.concat()
4 参考
[1]FCN-1
[2]语义分割 FCN & U-net & SegNet & DeconvNet
[3] Shuai Zheng, Sadeep Jayasumana, Bernardino Romera-Paredes, Vibhav Vineet, Zhizhong Su, Dalong Du, Chang Huang and Philip H. S. Torr. Conditional Random Fields as Recurrent Neural Networks. International Conference on Computer Vision, 2015.
[4]图像语义分析学习(一):图像语义分割的概念与原理以及常用的方法
[5]基于深度学习的图像语义分割技术概述之4常用方法