深度学习---ResNet
一、
ResNet在2015年被提出,在ImageNet比赛classification任务上获得第一名,因为它“简单与实用”并存,之后很多方法都建立在ResNet50或者ResNet101的基础上完成的,检测,分割,识别等领域都纷纷使用ResNet,Alpha zero也使用了ResNet,所以可见ResNet确实很好用。
下面我们从实用的角度去看看ResNet。
1.ResNet意义
随着网络的加深,出现了训练集准确率下降的现象,我们可以确定这不是由于Overfit过拟合造成的(过拟合的情况训练集应该准确率很高);所以作者针对这个问题提出了一种全新的网络,叫深度残差网络,它允许网络尽可能的加深,其中引入了全新的结构如图1;
这里问大家一个问题
残差指的是什么?
其中ResNet提出了两种mapping:一种是identity mapping,指的就是图1中”弯弯的曲线”,另一种residual mapping,指的就是除了”弯弯的曲线“那部分,所以最后的输出是 y=F(x)+x
identity mapping顾名思义,就是指本身,也就是公式中的 x ,而residual mapping指的是“差”,也就是 y−x ,所以残差指的就是 F(x) 部分。
为什么ResNet可以解决“随着网络加深,准确率不下降”的问题?
除了实验证明外:
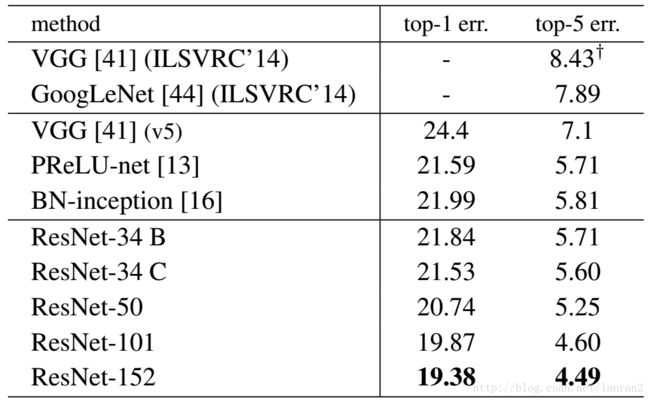
表1,Resnet在ImageNet上的结果
理论上,对于“随着网络加深,准确率下降”的问题,Resnet提供了两种选择方式,也就是identity mapping和residual mapping,如果网络已经到达最优,继续加深网络,residual mapping将被push为0,只剩下identity mapping,这样理论上网络一直处于最优状态了,网络的性能也就不会随着深度增加而降低了。
2.ResNet结构
它使用了一种连接方式叫做“shortcut connection”,顾名思义,shortcut就是“抄近道”的意思,看下图我们就能大致理解:
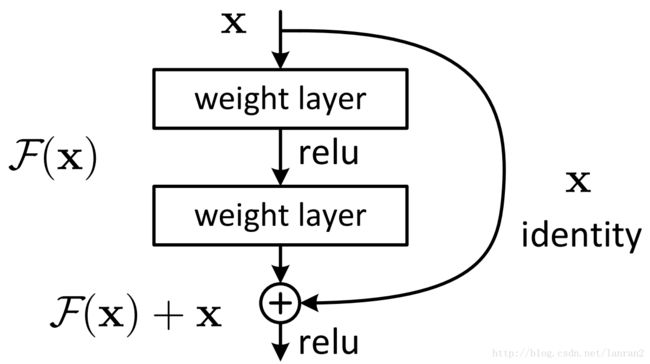
图1 Shortcut Connection
这是文章里面的图,我们可以看到一个“弯弯的弧线“这个就是所谓的”shortcut connection“,也是文中提到identity mapping,这张图也诠释了ResNet的真谛,当然大家可以放心,真正在使用的ResNet模块并不是这么单一,文章中就提出了两种方式:
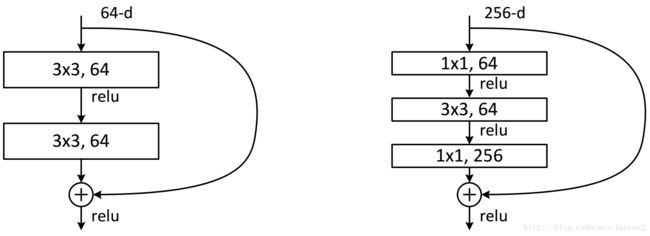
图2 两种ResNet设计
这两种结构分别针对ResNet34(左图)和ResNet50/101/152(右图),一般称整个结构为一个”building block“。其中右图又称为”bottleneck design”,目的一目了然,就是为了降低参数的数目,第一个1x1的卷积把256维channel降到64维,然后在最后通过1x1卷积恢复,整体上用的参数数目:1x1x256x64 + 3x3x64x64 + 1x1x64x256 = 69632,而不使用bottleneck的话就是两个3x3x256的卷积,参数数目: 3x3x256x256x2 = 1179648,差了16.94倍。
对于常规ResNet,可以用于34层或者更少的网络中,对于Bottleneck Design的ResNet通常用于更深的如101这样的网络中,目的是减少计算和参数量(实用目的)。
问大家一个问题:
如图1所示,如果F(x)和x的channel个数不同怎么办,因为F(x)和x是按照channel维度相加的,channel不同怎么相加呢?
针对channel个数是否相同,要分成两种情况考虑,如下图:

图3 两种Shortcut Connection方式
如图3所示,我们可以清楚的”实线“和”虚线“两种连接方式,
实线的的Connection部分(”第一个粉色矩形和第三个粉色矩形“)都是3x3x64的特征图,他们的channel个数一致,所以采用计算方式:
y=F(x)+x
虚线的的Connection部分(”第一个绿色矩形和第三个绿色矩形“)分别是3x3x64和3x3x128的特征图,他们的channel个数不同(64和128),所以采用计算方式:
y=F(x)+Wx
其中W是卷积操作,用来调整x的channel维度的;
下面我们看看两个实例:
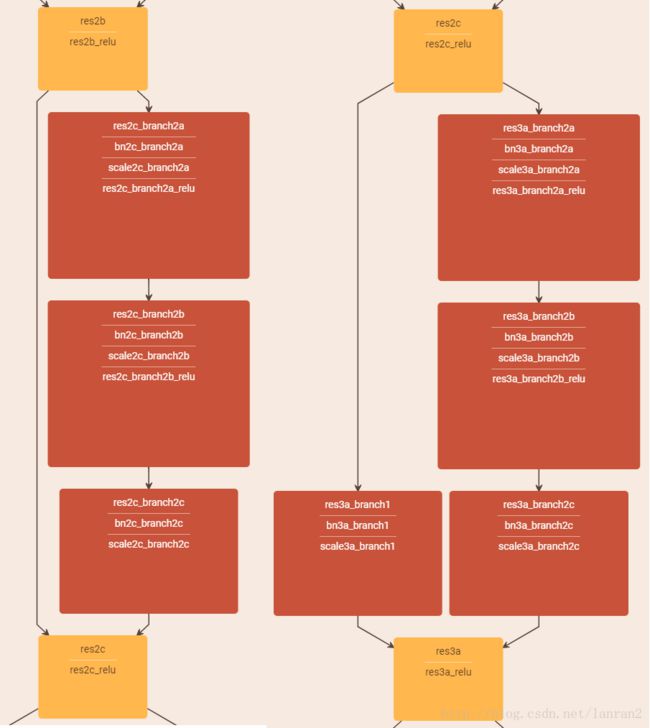
图4 两种Shortcut Connection方式实例(左图channel一致,右图channel不一样)
3.ResNet50和ResNet101
这里把ResNet50和ResNet101特别提出,主要因为它们的出镜率很高,所以需要做特别的说明。给出了它们具体的结构:
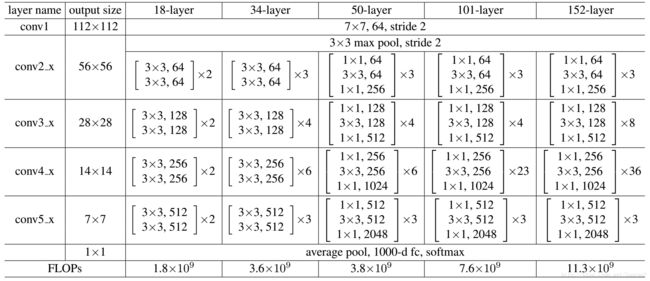
表2,Resnet不同的结构
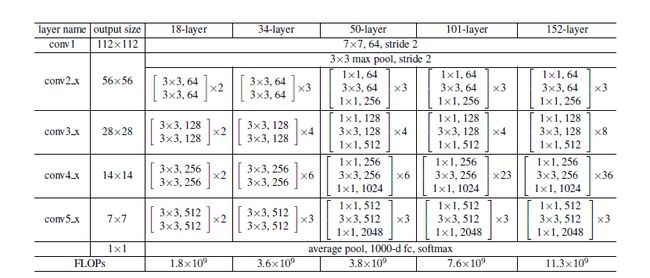
首先我们看一下表2,上面一共提出了5中深度的ResNet,分别是18,34,50,101和152,首先看表2最左侧,我们发现所有的网络都分成5部分,分别是:conv1,conv2_x,conv3_x,conv4_x,conv5_x,之后的其他论文也会专门用这个称呼指代ResNet50或者101的每部分。
拿101-layer那列,我们先看看101-layer是不是真的是101层网络,首先有个输入7x7x64的卷积,然后经过3 + 4 + 23 + 3 = 33个building block,每个block为3层,所以有33 x 3 = 99层,最后有个fc层(用于分类),所以1 + 99 + 1 = 101层,确实有101层网络;
注:101层网络仅仅指卷积或者全连接层,而激活层或者Pooling层并没有计算在内;
这里我们关注50-layer和101-layer这两列,可以发现,它们唯一的不同在于conv4_x,ResNet50有6个block,而ResNet101有23个block,查了17个block,也就是17 x 3 = 51层。
4.基于ResNet101的Faster RCNN
文章中把ResNet101应用在Faster RCNN上取得了更好的结果,结果如下:


表3,Resnet101 Faster RCNN在Pascal VOC07/12 以及COCO上的结果
这里有个问题:
Faster RCNN中RPN和Fast RCNN的共享特征图用的是conv5_x的输出么?
针对这个问题我们看看实际的基于ResNet101的Faster RCNN的结构图:
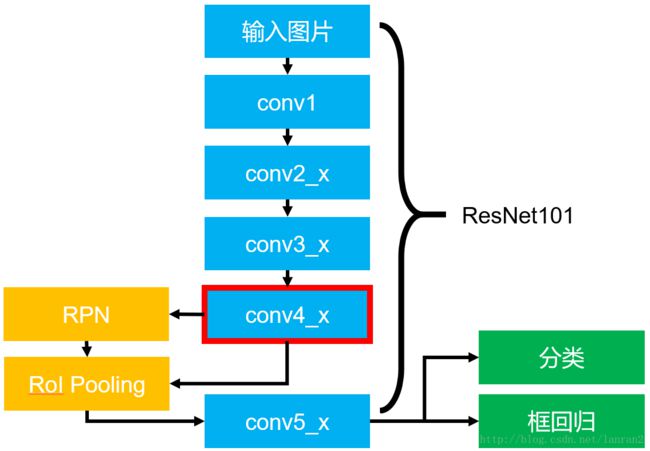
图5 基于ResNet101的Faster RCNN
图5展示了整个Faster RCNN的架构,其中蓝色的部分为ResNet101,可以发现conv4_x的最后的输出为RPN和RoI Pooling共享的部分,而conv5_x(共9层网络)都作用于RoI Pooling之后的一堆特征图(14 x 14 x 1024),特征图的大小维度也刚好符合原本的ResNet101中conv5_x的输入;
最后大家一定要记得最后要接一个average pooling,得到2048维特征,分别用于分类和框回归。
本文结构:
我的阅读笔记
1.ResNet之Building block
以下内容为我的理解,如有不正确的地方,还望各位大神指导!
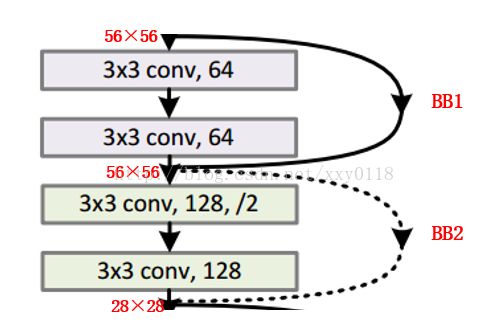
如图所示为截选自ResNet-34的部分Buildingblock,论文作者对于identiy shortcut和projection shortcut的两种options的描述,让我困惑了很久,一直在纠结到底为什么经过了3×3的卷积层以后,仍然能够保持输入输出的一致?
以下是我对这个问题的理解:
首先,为了方便,我将buildingblock区分为两类:
a. 第一类Building block(BB1)如上图中实线部分的building block所示,特点为输入输出的维度一致,特征图个数也一致;
b. 第二类Building block(BB2)如上图虚线部分的building block所示,特点为输出是输入维度的1/2,输出特征图个数是输入特征图个数的2倍(即执行了/2操作)。
区分了两类Building block后,来来来跟我一起仔细读一下论文:
1. “The identity shortcuts (Eqn.(1)) can be directly used when theinput and output are of the same dimensions (solid line shortcuts in Fig. 3).”
What?对于BB1,让我直接相加?输入都经过两次3×3的卷积操作了啊喂,维度不一样怎么相加!好吧,经过查阅资料,作者可能委婉的表达了中间过程,但是我没有发现吧。我琢磨着中间过程应该如下所示:
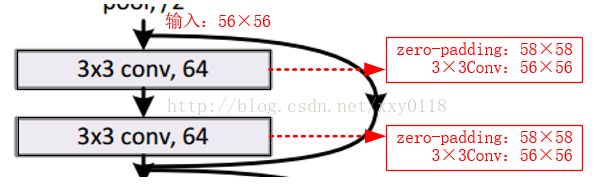
好啦,这下可以“can bedirectly used”了。接着读论文:
2. “When the dimensions increase (dotted line shortcuts in Fig. 3),we consider two options: (A) The shortcut still performs identity mapping, withextra zero entries padded for increasing dimensions. This option introduces noextra parameter; (B) The projection shortcut in Eqn.(2) is used to matchdimensions (done by 1×1 convolutions). For both options, when the shortcuts goacross feature maps of two sizes, they are performed with a stride of 2.”
对于BB2,作者提供了两种选择:(A)如BB1的处理一样,0填充技术,只是要填充好多0啊,这也是为什么得到实验4.1中的ResidualNetworks部分的“B is slightly better than A. We argue that this is because thezero-padded dimensions in A indeed have no residual learning.”的结论(P6右侧中间)。(B)采用公式(2)的projectionshortcut,让Ws与输入做步长为2的1×1的卷积操作,这样,输入和输出就具有相同的维数,接下来在进行相加操作就OK啦!过程如下图所示:
 2.ResNet之CIFAR-10实验结构
2.ResNet之CIFAR-10实验结构
哎呀,对于我的理解能力来说,作者对基于ResNet的CIFAR-10的实验网络结构描述的太混乱了!好不容易才搞清楚的。以n=3,20层的ResNet为例,具体结构如下表所示:
| Output map size |
Output_size |
20-layer ResNet |
| Conv1 |
32×32 |
{3×3,16} |
| Conv2_x |
32×32 |
{3×3,16; 3×3,16}×3 |
| Conv3_x |
16×16 |
{3×3,32; 3×3,32}×3 |
| Conv4_x |
8×8 |
{3×3,64; 3×3,64}×3 |
| InnerProduct |
1×1 |
Average pooling 10-d fc |
其他资料
1.ResNet作者何凯明博士在ICML2016上的tutorial演讲
https://www.leiphone.com/news/201608/vhqwt5eWmUsLBcnv.html
本文为何凯明博士在ICML2016上的tutorial演讲以及相关PPT整理。里面的翻译有少量的错误,例如solution 应翻译为“解”,plain net应翻译为“普通网络”。
Resnet在ILSVRC 和COCO 2015上的五个主要任务轨迹中都获得了第一名的成绩,而且远超过第二名。

大多数网络模型随着网络深度的增加,准确率会趋于饱和,并且快速下降。但作者认为这并不仅仅是overfitting的原因,也是由于某些模型加深本身会导致增加训练误差。
ResNet的核心思想是:计算层到层的残差,即F(x),以F(x)+x作为输出。其特点为:A simple and clean framework of training “very” deep nets。
简单介绍一下RestNet的细节:
① 在许多数据集中都能够观察到的普遍现象就是过深的普通网络具有更高的训练误差。但是,一个较深的模型理应具有更高的准确率。关于普通网络和Residual Net如下图所示:
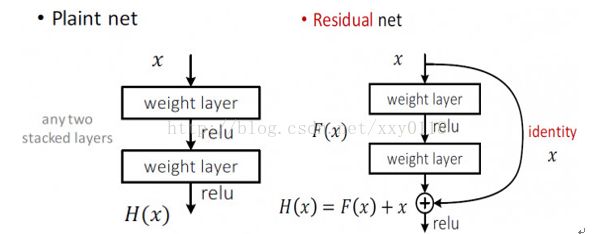
② Residual Net:H(x)是输出,希望2层权重能够拟合F(x),使得:
H(x)=F(x)+x
F(x)是一个关于恒等式残差的映射。
a. If identity were optimal, easyto set weights as 0;
b. If optimal mapping is closer toidentity, easier to find small fluctuations.
③ 网络设计:
a. 全部采用3×3 conv操作(或者大部分采用)
b. Spatial size /2 -> # filter×2
c. 没有FC层和Dropout层
④ 实验结果表明,ResNet能够在没有任何困难的情况下得到训练,并且实现更深的网络结构使其达到更低的训练误差和测试误差。
⑤ 受设备计算能力限制,作者也提出了另一个与原始ResNet复杂度相同的BottleNeck模型,它是一个逐层深入且实际可行的方案。详细细节参考2.的链接及内容。
⑥ 作者分析了学习深度学习模型存在的问题和本文提出的对策:
a. 表征能力:ResNet在表征能力上不存在明显优势(只是重复的参数化),但是,能够使加深模型变得切实可行;
b. 优化能力:能够使前向/反向传播算法更加平稳,极大程度简化/减轻(DBA)优化深度模型;
c. 一般化(Generalization)能力:ResNet未直接处理一般化问题,但是更深+更薄是一种很好的一般化手段。
以上对ResNet做了简要介绍,了解到ResNet在加深网络模型,提高学习任务准确率等方面都有很大的优势,不过也刚巧在学习本论文的当天就阅读到推送的一篇论文,对ResNet提出质疑并进行了证明,详细信息参考链接3.
2.Bottleneck
http://www.jianshu.com/p/e502e4b43e6d
作者主要介绍了ResNet的DeeperBottleneck Architectures(DBA),一个DBA共3×3=9层。如下图:
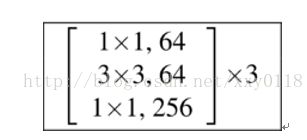
本文作者参考Ryan Dahl的源码(https://github.com/ry/tensorflow-resnet),画出了DBA内部网络的前三层,如下图所示:

注意,56*56的map经过3*3的卷积核后输出仍然是56*56的原因是两边是有补零的,来保证尺寸大小不变。
3.diss ResNet的论文
http://www.jianshu.com/p/e502e4b43e6d
作者介绍,CornellUniversity的几个人研究了ResNet,发现它所谓的“超深网络”只是个噱头,并在NIPS上发表论文《Residual Networks are Exponential Ensembles of Relatively ShallowNetworks》,表明ResNet并不深,它本质上是一堆浅层网络的集合。

一个拥有三个block的ResNet可以展开为上右图的形式,类似于多个网络的ensemble形态,所以精度很高。
① 论文作者证明,少个block情况下,对ResNet影响甚微,与之相比,VGGNet识别率惨不忍睹。因为,多线网络少个block,网络仍然是通的,单线网络少个block,网络断开。
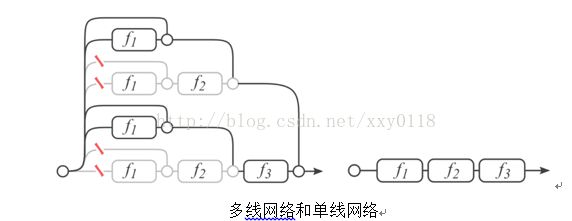
② 继网络的“深度”和“宽度”两项指标之后,作者根据网络包含的“子网络”数量,提出了一个新指标——multiplicity。
摘要
越深层次的神经网络越难以训练。我们提供了一个残差学习框架,以减轻对网络的训练,这些网络的深度比以前的要大得多。我们明确地将这些层重新规划为通过参考输入层x,学习残差函数,来代替没有参考的学习函数。
我们提供了综合的经验证据,表明残差网络更容易优化,并且可以从显著增加的深度中获得准确性。在ImageNet数据集上,我们对剩余的网进行评估,其深度为152层,比VGG网41层更深,但仍可以保证有较低的复杂度。结合这些残差网络在ImageNet测试集上获得了3.57%的误差,这一结果在ILSVRC2015分类任务中获得了第一名。我们还对cifar 10进行了100和1000层的分析。
对于许多视觉识别任务来说,特征表达的深度是至关重要的。仅仅由于我们的极深的表示,我们在COCO目标检测数据集上获得了28%的相对改进。深度残差网络是我们参加LSVRC&COCO 2015比赛的基础,我们还赢得了ImageNet检测、ImageNet本地化、可可检测和可可分割等任务的第1个位置。
1. 引言
深度卷积神经网络已经为图像分类带来了一系列突破。网络深度是至关重要的。
在深度重要性的驱使下,一个问题出现了:学习更好的网络是否像堆更多的层一样简单?回答这个问题的一个障碍是众所周知的“梯度消失/爆炸”,这阻碍了从一开始就收敛。然而,这个问题主要通过规范化的初始化和中间的标准化层(Batch Normalization)来解决,这使得具有数十层的网络通过随机梯度下降(SGD)方法可以开始收敛。
当更深的网络能够开始收敛时,退化问题就暴露出来了:随着网络深度的增加,准确度就会饱和(这可能不足为奇),然后就会迅速下降。出乎意料的是,这种退化不是由过度拟合造成的,并且在适当的深度模型中加入更多的层会导致更高的训练错误,正如我们的实验所证实的那样。
(训练精度的)退化表明不是所有的系统都同样易于优化。让我们考虑一个较浅的架构,以及在它上面添加了更多的层的深层的架构。有一种解决方案可以通过构建到更深层次的模型(解决优化问题):增加的层是恒等映射,而其他层则是从学习的浅模型中复制出来的。这种构造方法表明,一个较深的模型不应产生比较浅的模型更高的训练误差。但实验表明,我们现有的解决方案无法找到比这个构建方案好或更好的解决方案(或者在可行的时间内无法做到这一点)。
本文通过引入一个深层残差学习框架来解决退化问题。我们没有希望每一层都直接匹配所需的潜在映射,而是明确地让这些层适合一个残差映射。在形式上,将所需的潜在映射表示为H(x),我们让堆叠的非线性层适合另一个映射F(x)=H(x)-x。原来的映射被重新定义为F(x)+x。我们假设优化残差映射比优化原始的映射更容易。在极端情况下,如果一个标识映射是最优的,那么将残差值推到零将比通过一堆非线性层来匹配一个恒等映射更容易。
F(x)+x的表达式可以通过使用“shortcut connections”的前馈神经网络实现(图2)。“shortcutconnections”是跳过一个或多个层。在我们的例子中,“shortcut connections”简单地执行恒等,它们的输出被添加到叠加层的输出中(图2)。恒等的“shortcut connections”既不增加额外参数,也不增加计算复杂度。整个网络仍然可以通过SGD对反向传播进行端到端训练,并且可以在不修改解决方案的情况下使用公共库轻松实现。
我们对ImageNet进行了全面的实验,以显示其退化问题,并对其进行了评价。我们证明:1)我们极深的残差网络很容易优化,但是当深度增加时,对应的普通网(简单的叠层)显示出更高的训练错误;2)我们的深层残差网可以很容易地从深度的增加中获得精确的增益,产生的结果比以前的网络要好得多。
2. 相关工作
残差表达
在图像识别中,VLAD是一种由残差向量关于字典的编码表示,而Fisher Vector可以被定义为VLAD的概率版本。它们都是图像检索和分类的强大的浅层表示。对于向量化,编码残差向量比编码原始向量更有效。
在低层次的视觉和计算机图形学中,为了解决偏微分方程(PDEs),被广泛使用的多网格法将系统重新设计成多个尺度下的子问题,每个子问题负责一个较粗的和更细的尺度之间的残差解。多网格的另一种选择是分层基础的预处理,它依赖于在两个尺度之间表示残差向量的变量。研究表明,这些(转化成多个不同尺度的子问题,求残差解的)解决方案的收敛速度远远快于那些不知道残差的标准解决方案。这些方法表明,良好的重构或预处理可以简化优化问题。
Shortcut Connections
与我们的工作同时,HighwayNetworks提供了与门控功能的shortcut connection。这些门是数据相关的,并且有参数,这与我们的恒等shortcut connection是无参数的。当一个封闭的shortcut connection被关闭(接近于零)时,highway networks中的层代表了无残差的函数。相反,我们的公式总是学习残差函数;我们的恒等shortcut connection永远不会关闭,在学习其他残差函数的同时,所有的信息都会被传递。此外,highway networks还没有显示出从增加深度而获得的准确率的增长(例如:,超过100层)。
3. 深度残差网络学习
3.1残差学习
我们令H(x)作为需要多层神经网络去拟合的目标函数。如果假设多个非线性层可以逐渐近似一个复杂的函数,那么等价于假设他们可以逐渐近似残差函数,即H(x)-x。因此,与其让期望这些层近似H(x),我们让这些层直接近似残差函数F(x)= H(x)-x。原始的函数则变成了H(x) = F(x)+x。尽管这两种形式都应该能够逐渐地近似期望的函数,但学习的轻松度可能是不同的。
这个重新制定的动机是由于退化问题的反直觉现象(图一,左图)。正如我们在引言中所讨论的,如果添加的层可以被构造为恒等映射,那么一个较深的模型的训练错误不应该比相对更浅的模型训练误差大。退化问题表明,求解起在通过多个非线性层逼近恒等映射时遇到困难。利用残差的学习方法,如果恒等映射是最优的,求解器也许只需将多个非线性层的权重简单的置为零,以近似恒等映射。
在实际情况中,恒等映射不太可能是最优的,但是我们的重制可能有助于解决问题。如果最优函数更接近于标识映射,而不是零映射,相比于将其作为一个新函数的学习,解析器可以更容易地找到与恒等映射相关的扰动(即残差)。我们通过实验(图7)显示,习得的残差函数一般都有很小的波动,这表明恒等映射提供了合理的前提条件。
3.2通过Shortcut的恒等映射
我们采取将每一个叠层都应用残差学习。图2中显示了一个building block。正式地,在本文中,我们考虑一个定义为:
其中x和y是层的输入和输出向量。函数F(x,{wi})表示要学习的残差映射。如图2为两个层的例子,F=w2(W1x),其中表示ReLU,为了简化表示,省略了偏差b。F+x的操作是通过一个shortcutconnection将对应元素进行相加来执行的。在加法之后,我们采用了第二次非线性映射。(即(y),见图2)。
等式(1)中的shortcut connection既没有引入额外的参数,也没有增加计算复杂度。这不仅在实践中很有吸引力,而且在我们对普通的网络和残差网络的比较中也很重要。我们可以公平地比较同时具有相同数量的参数、深度、宽度和计算成本(除了可以忽略的相对应的元素相加操作之外)的普通网络和残差网络。
x和F的维数在等式(1)中必须相等。如果不是这样的话(例如:当改变输入/输出通道时),我们可以通过shortcut connection来执行一个线性投影,以匹配维度:
我们也可以在等式(1)中使用一个矩阵Ws。但我们将通过实验证明,恒等映射对于解决退化问题是足够的,而且是经济的,因此只有在匹配维度时才需要使用Ws。
残差函数F的形式是灵活的。本文的实验涉及到一个函数F,它有两个或三个层(图5),当然更多的层也是可以的。但是,如果F只有一个层,等式(1)与线性层y=W1x+x相似,我们没有观察到它的优势。
我们还注意到,尽管上面的符号是为了简单起见而使用完全连接的层,但它们适用于卷积层。函数F(x;{wi})可以代表多个卷积层。元素相加是一个通道接着通道,在两个特征图上执行的。
3.3网络结构
我们测试了各种各样的普通/残差网网络,并观察到一致的现象。为了提供讨论的实例,我们描述了ImageNet的两个模型。
普通网络
我们的基准线(图3,中间)主要受VGG网络(图3左)的启发。卷积层主要有3×3的过滤器,并遵循两个简单的设计规则:(i)相同的输出特性图的大小,各层有相同数量的过滤器;(2)如果特征图的大小减半,那么过滤器的数量就增加一倍,以保证每一层的时间复杂度相同。我们直接通过卷积层来进行向下采样,这些层的步长为2。该网络以一个全局平均池层和一个1000层的完全连接层和softmax来结束。图3(中)的权重层数为34。
值得注意的是,我们的模型比VGG网络(图3左)更少的过滤器和更低的复杂性。我们的具有34层的baseline有36亿 FLOPs,只是VGG-19(19.6亿FLOPs)的18%。
残差网络
基于上面的普通网络,我们插入了shortcut connection(图3,右),将网络转换为对应的残差版本。当输入和输出是相同的维度时,恒等shortcut(等式(1))可以直接使用(图3实线)。当维度增加(图3中虚线),我们提供两个选择:(A)short connection仍然执行恒等映射,用额外的零填充增加维度。这个选项不引入额外的参数;(B)等式 (2)中的投影shortcut用于匹配维数(由1×1卷积完成)。对于这两个选项,当shortcut融合两个大小的特征图时,它们的执行时的步长是2。
3.4实施
我们对ImageNet的实现遵循了[21、41]的实践。为了扩大规模,[256,480]大小的图像被沿着短边通过随机采样调整大小。从图像或它的水平翻转中随机抽取[224,224],每像素减去平均。[21]中的标准颜色增强技术被使用。我们在每次卷积和激活前都采取Batch Normalization。我们同[13]一样初始化权重,从头开始训练普通网络和残差网络。我们使用SGD的批量大小为256。学习率从0.1开始,当误差停滞时,将学习率除以10,模型被训练多大60万次。我们使用0.0001的权重衰减,和0.9的momentum。根据[16],我们不使用Dropout层。
在测试中,为了比较研究,我们采用了标准的十折交叉验证。为了得到最好的结果,我们采用了全卷积式的形式如[41,13],并在多个尺度上平均得分(图像被调整大小到更短的变,如224,256,384,480,640)。
4. 实验
4.1ImageNet分类
我们在包含1000类的ImageNet2012分类数据集上评估我们的方法。模型在包含128万的训练数据将上训练,在5玩的验证图像上评估。我们最终的结果是由测试服务器在10万的测试集上获得的。我们评估了前1和前5的错误率。
普通网络
我们首先评估18层和34层的普通网络。34层普通网络如图3中间的网络所示。18层普通网络是同样的形式。详细结构请参考表1。
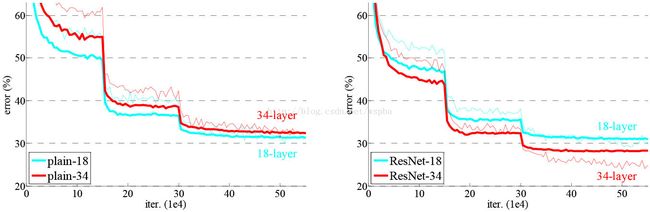
表2所示的结果说明,更深的34层普通网络比较浅的18层网络具有更高的验证错误率。为揭露其原因,如图4左,我们在训练过程中比较它们的训练/验证误差。我们观察到了退化现象—尽管这个18层普通网络的解空间是34层的一个子空间,34层的普通网络在训练过程中始终具有更高的训练误差。
我们认为这种优化问题不太可能是由梯度消失引起的。这个普通网络用BN训练,这确保了传播的信号具有非零的方差。我们还验证了反向传播的梯度在BN中表现出了健康的规范。因此,无论是向前还是向后的信号都不会消失。事实上,34层普通网络仍然能够达到具有竞争力的准确率,说明求解器在某种程度上是可行的。我们推测,深度普通网络可能具有低指数的收敛速度,这将影响训练误差的减少。这种优化问题的原因在未来将会被研究。
残差网络
接着我们评估了18层和34层的残差网络。除了每对3×3的filters之间增加了shortcut连接外,基准结构和之前的普通网络相同,如图3右所示。第一个对比(表2和图4右),我们使用对所有的shortcut使用恒等映射,并使用0填充技术用于增加维度(操作A)。因此,与相应的普通网络相比,它们没有增加额外的参数。
我们从表2和图4中得到了三个主要的观察结果。第一,在残差学习中情况是相反的--34层的ResNet比18层的ResNet要好(2.8%)。更重要的是,34层ResNet展现出相当低的训练误差并可以概括验证数据(即验证数据有相同的实验结果)。这表明,在这样的设置下,退化问题得到了很好的解决,并且我们成功的从增加的深度获得了精度的提高。
第二,与其相对应的普通网络相比,由于成功减少了训练误差 (图4右与左),ResNet将top-1的误差降低了3.5%(表2)。这一比较验证了在极深系统中残差学习的有效性。
最后,我们还注意到,18层的普通/残差的网是相当精确的(表2),但是18层的ResNet更快速地收敛(图4右与左)。当网络不太深(这里有18层)时,当前的SGD求解器仍然能够找到普通网络的优解。在这种情况下,ResNet通过在早期提供更快的聚合来使优化变得轻松。
恒等shorcut vs. 投影shortcut
我们已经证明了,不增加参数的恒等shortcut有助于训练。接下来我们研究投影快捷方式(等式2)。在表3中,我们比较了三个选项:(A)用于增加维度的零填充shortcut,所有的shortcut都是不增加参数的(与表2和图4相同);(B)用于增加维度的投影shortcut,其他快shortcut采用恒等shortcut;(ps,我认为他说的维度增加是指featuremap增加的部分)(C)所有的shortcut都采用投影。
表3显示了这三个选项都比普通网络的要好得多。B比A稍微好一点。我们认为这是因为A的0填充的维度确实没有残差学习。C比B略好,我们将其归因于许多(13)投影shortcut引入的额外参数。但是,a/b/c之间的微小差异表明,投射shortcut对于解决退化问题并不是必需的。因此,在本文的其余部分中,我们不使用选项C,以减少内存/时间复杂度和模型大小。恒等shortcut不增加复杂度对于下面引入的Bottleneck结构的特别重要。
Deeper Bottleneck Architectures
接下来描述的针对ImageNet的深度网络。考虑到我们所能承担的训练时间,我们修改building block为bottleneck。对于每个残差函数F,我们使用一个3层的栈式结构代替2层的结构(图5)。这三层分别是1×1、3×3和1×1的卷积,1×1的卷积的目的是使维度先减小再增加(复原),让3×3的卷积层作为一个低维输入输出的bottleneck。图5展示了一个示例,两种设计有相同的时间复杂度。
恒等的shortcut对bottleneck结构非常重要。如果图5右的恒等shortcut被投影shortcut代替,时间复杂度和模型大小都被加倍,因为shortcut用于连接两个高维的端。因此,恒等shortcuts使bottleneck的设计更有效。(注意,bottleneck也有退化现象,所以bottleneck的设计要尽量简洁)
50层ResNet:我们用这种3层的bottleneck代替34层ResNet中的每个两层block,构成50层ResNet(表1)。我们使用选项B来增加维度。这个模型有38亿FLOPs。
101层和152层ResNet:我们通过使用更多的3层block构建101层和152层ResNet(表1)。尽管深度有了显著的增加,152层ResNet(113亿FLOPs)仍然比VGG-16/19(153亿/196亿FLOPs)复杂度更低。
50/101/152层的比34层更精确(表3和4),我们没有观察到退化问题,并因此从相当高的深度上获得了显著的精度增益。在所有评估指标上都可以看到深度的好处(表3和4)。
与优秀算法的比较
表4中,我们比较累之前最好的单模型结果。我们的基本34层ResNet已经达到具有竞争力的准确度。我们的152层的ResNet有一个单模型top-5验证验证误差为4.49%。这个单模型结果比以前所有的集合结果都要出色(表5)。我们结合六种不同深度的模型形成一个集合(在提交时只用了2个152层ResNet)。在测试集上取得了3.57%的top-5错误率。这项赢得了ILSVRC2015的第一名。
4.2CIFAR-10和分析
我们在CIFAR-10上做了更多研究,它由包括10个类别的5万个训练图和1万个测试图组成。我们展示在需年纪的训练和在测试集上的测试实验。我们主要研究极其深的网络的表现,而不是找出一个优异的实验结果,因此我们有意使用如下简单的结构。
普通网络/残差网络结构如图3(中/右)所示。网络输入为32×32的图片,每个像素都减去平均值。第一层为一个3×3的卷积层。然后我们使用将6n层3×3的卷积层堆栈在一起,特征图大小分别为{32,16,8},每个特征图大小对应2n个层。Filter的个数分别为{16,32,64}。下采样操作通过步长为2的卷积操作执行。网络以一个全局平均池化层和softmax层结合。一共有6n+2个权重层。下表总结了结构。
当shortcut被使用时,它们被连接到成对的3×3层(3n个shortcut)。在这个数据集上,我们全部使用恒等shortcuts(即选项A),因此,我们的残差模型和相应的普通网络具有相同的深度、宽度和参数的个数。
我们使用0.0001的权重衰减和0.9的动量,并常用[13]的权重初始化和BN,但是没有dropout层。这个模型用批量大小为128,在2个GPU上训练。我们开始时设置学习率为1.1,在32k和48k次迭代时将学习率除以10,并在64k次迭代时结束训练,这由45k/5k train/val划分决定。我们根据[24]的简单数据扩增进行训练:每一侧都填充4个像素,并且从填充图像或水平翻转中随机抽取32×32的corp。为了测试,我们只评估原始32×32图像的单一视角。
我们比较n={3,5,7,9},即20,32,44,56层网络。图6左展示了普通网络的表现。深度普通网络受到了深度的影响,并且在深的时候表现出了更高的训练错误。这个现象与ImageNet和MNIST相同,说明这样的优化困难是一个基本问题。
图6(中间)展示了ResNets的表现。也和ImageNet相同,我们的ResNets成功的克服了优化困难并展示出在深度的时候获得的准确度。
我们更进一步探索了n=18时,110层的ResNet。在这个试验中,我们发现0.1的初始学习率有一些太大以至于提早开始收敛。因此我们使用0.01的学习路开始训练指导训练误差地域80%(大约400次迭代),然后变回0.1的学习率继续训练。其他的学习任务和前面的实验一样。110层的网络能够很好的收敛(图6中间)。它具有比其他又深又窄的网络如FitNet和HighWay更少的参数(表6),已经是最优异的结果了(6.43%,表6)。
层响应分析
图7展示了层响应的方差。这个响应是BN之后,其他非线性操作(ReLU/addition)之前的输出。对于ResNets,这个分析揭示了残差函数的响应力度。图7展示了ResNet一般比相应的普通网络具有更小的响应。这个结果支持了我们的基本动机(3.1节),即残差函数比非残差函数更易接近于0。我们也注意到,更深的ResNet比20,56,110层的ResNet有更小量级的响应,如图7。当有更多的层时,一个单独的ResNet层往往会更少地修改信号。
探索1000+层
我们探索了一个超过1000层的深度模型。我们设置n=200,使其产生一个1202层的网络,同如上所述的进行训练。我们的方法没有显示优化困难,这个1000层网络能够实现训练误差小于0.1%(图6,右)。它的测试错误也相当好(7.93%,表6)。
但在这种过分深层的模型上,仍存在一些问题。这个1202层网络的测试结果比我们的110层网络要差,尽管两者都有相似的训练误差。我们认为这是因为过度拟合。对于小数据集来说,1202层的网络也许没有必要。如Maxout和Dropout等强大的正则化方法在这个数据集上已经取得了很好的结果。在这篇论文中,我们没有使用maxout/dropout并且只简单的通过深度和设计薄的结构来实现规范化,而不会分散对优化问题的注意力。但是,结合更强的规范化可能会改善结果,我们将在未来研究。
4.3在PASCAL和MS COCO上的目标检测
我们的方法已经在其他识别任务上取得了一般化的表现。表7和表8展示在PASCAL VOC 2007和2012以及COCO上的基本结果。我们采取Faster R-CNN作为检测方法。我们对用resnet-101替换VGG-16的改进感兴趣。使用这两种模型检测的实现(见附录)是相同的,因此所得的结果只能归因于更好的网络。值得注意的是,在COCO数据集的挑战上,我们在COCO标准度量上获得了6%的增加(mAP@[.5,.95])相对改进了28%。这个进步仅仅是因为特征的学习。
基于深度残差网络,我们在ILSVRC&COCO2015年的比赛中获得了第1名:ImageNet检测、ImageNet定位、COCO检测和COCO分割。细节在附录中。
论文地址:Deep Residual Learning for Image Recognition
ResNet——MSRA何凯明团队的Residual Networks,在2015年ImageNet上大放异彩,在ImageNet的classification、detection、localization以及COCO的detection和segmentation上均斩获了第一名的成绩,而且Deep Residual Learning for Image Recognition也获得了CVPR2016的best paper,实在是实至名归。就让我们来观摩大神的这篇上乘之作。
ResNet最根本的动机就是所谓的“退化”问题,即当模型的层次加深时,错误率却提高了,如下图:

但是模型的深度加深,学习能力增强,因此更深的模型不应当产生比它更浅的模型更高的错误率。而这个“退化”问题产生的原因归结于优化难题,当模型变复杂时,SGD的优化变得更加困难,导致了模型达不到好的学习效果。
针对这个问题,作者提出了一个Residual的结构:
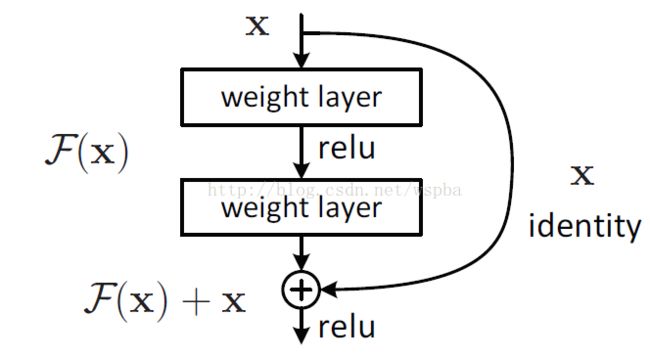
即增加一个identity mapping(恒等映射),将原始所需要学的函数H(x)转换成F(x)+x,而作者认为这两种表达的效果相同,但是优化的难度却并不相同,作者假设F(x)的优化 会比H(x)简单的多。这一想法也是源于图像处理中的残差向量编码,通过一个reformulation,将一个问题分解成多个尺度直接的残差问题,能够很好的起到优化训练的效果。
这个Residual block通过shortcut connection实现,通过shortcut将这个block的输入和输出进行一个element-wise的加叠,这个简单的加法并不会给网络增加额外的参数和计算量,同时却可以大大增加模型的训练速度、提高训练效果,并且当模型的层数加深时,这个简单的结构能够很好的解决退化问题。
接下来,作者就设计实验来证明自己的观点。
首先构建了一个18层和一个34层的plain网络,即将所有层进行简单的铺叠,然后构建了一个18层和一个34层的residual网络,仅仅是在plain上插入了shortcut,而且这两个网络的参数量、计算量相同,并且和之前有很好效果的VGG-19相比,计算量要小很多。(36亿FLOPs VS 196亿FLOPs,FLOPs即每秒浮点运算次数。)这也是作者反复强调的地方,也是这个模型最大的优势所在。

模型构建好后进行实验,在plain上观测到明显的退化现象,而且ResNet上不仅没有退化,34层网络的效果反而比18层的更好,而且不仅如此,ResNet的收敛速度比plain的要快得多。
对于shortcut的方式,作者提出了三个选项:
A. 使用恒等映射,如果residual block的输入输出维度不一致,对增加的维度用0来填充;
B. 在block输入输出维度一致时使用恒等映射,不一致时使用线性投影以保证维度一致;
C. 对于所有的block均使用线性投影。
对这三个选项都进行了实验,发现虽然C的效果好于B的效果好于A的效果,但是差距很小,因此线性投影并不是必需的,而使用0填充时,可以保证模型的复杂度最低,这对于更深的网络是更加有利的。
进一步实验,作者又提出了deeper的residual block:
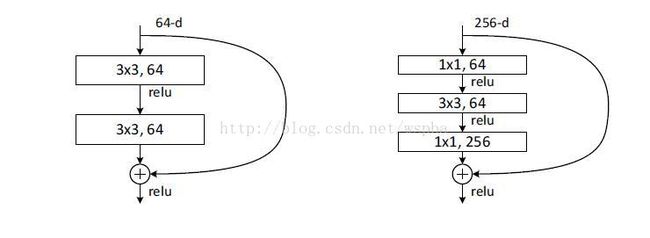
这相当于对于相同数量的层又减少了参数量,因此可以拓展成更深的模型。于是作者提出了50、101、152层的ResNet,而且不仅没有出现退化问题,错误率也大大降低,同时计算复杂度也保持在很低的程度。
这个时候ResNet的错误率已经把其他网络落下几条街了,但是似乎还并不满足,于是又搭建了更加变态的1202层的网络,对于这么深的网络,优化依然并不困难,但是出现了过拟合的问题,这是很正常的,作者也说了以后会对这个1202层的模型进行进一步的改进。(想想就可怕。)
在文章的附录部分,作者又针对ResNet在其他几个任务的应用进行了解释,毕竟获得了第一名的成绩,也证明了ResNet强大的泛化能力,感兴趣的同学可以好好研究这篇论文,是非常有学习价值的。
四、
《Deep Residual Learning for Image Recognition》是2016年CVPR的最佳论文,也是我Kaiming男神第二次获得CVPR的最佳论文,简直强的一批啊!
摘要
resNet主要解决一个问题,就是更深的神经网络如何收敛的问题,为了解决这个问题,论文提出了一个残差学习的框架。然后简单跟VGG比较了一下,152层的残差网络,比VGG深了8倍,但是比VGG复杂度更低,当然在ImageNet上的表现肯定比VGG更好,是2015年ILSVRC分类任务的冠军。
另外用resNet作为预训练模型的检测和分割效果也要更好,这个比较好理解,分类效果提升必然带来检测和分割的准确性提升。
介绍
在resNet之前,随着网络层数的增加,收敛越来越难,大家通常把其原因归结为梯度消失或者梯度爆炸,这是不对的。另外当训练网络的时候,也会有这样一个问题,当网络层数加深的时候,准确率可能会快速的下降,这当然也不是由过拟合导致的。我们可以这样理解,构造一个深度模型,我们把新加的层叫做identity mapping(这个mapping实在不知道怎么翻译好,尴尬……),而其他层从学好的浅层模型复制过来。现在我们需要保证这个构造的深度模型并不会比之前的浅层模型产生更高的训练错误,然而目前并没有好的比较方法。

从图上可以看到,层数越多,收敛越慢,且error更高。
在论文中,kaiming大佬提出了一个深度残差学习框架来解决网络加深之后准确率下降的问题。用公式来表示,假如我们需要的理想的mapping定义为 H(x) ,那么我们新加的非线性层就是 F(x):=H(x)−x ,原始的mapping就从 x 变成了 F(x)+x 。也就是说,如果我们之前的 x 是最优的,那么新加的identity mapping F(x) 就应该都是0,而不会是其他的值。

这样整个残差网络是端对端(end-to-end)的,可以通过随机梯度下降反向传播,而且实现起来很简单(实际上就是两层求和,在Caffe中用Eltwise层实现)。至于它为什么收敛更快,error更低,我是这么理解的:
我们知道随机梯度下降就是用的链式求导法则,我们对 H(x) 求导,相当于对 F(x)+x 求导,那么这个梯度值就会在1附近(x的导数是1),相比之前的plain网络,自然收敛更快。
深度残差学习
假设多个线性和非线性的组合层可以近似任意复杂函数(这是一个开放性的问题),那么当然也可以逼近残差函数 H(x)−x (假设输入和输出的维度相同)。
论文中残差模块定义为:
y=F(x,wi)+x
其中, x 代表输入, y 代表输出, F(x,wi) 代表需要学习的残差mapping。像上图firgure 2有两层网络,用 F=W2σ(W1x) 表示,这里 σ 表示ReLU激活层。这里 Wx 是卷积操作,是线性的,ReLU是非线性的。
其中 x 和 F 的维度一定要相同,如果不同的话,可以通过一个线性映射 Ws 来匹配维度:
y=F(x,Wi)+Wsx
这里 F 是比较灵活的,可以包含两层或者三层,甚至更多层。但是如果只有一层的话,就变成了 y=Wix+x ,这就是普通的线性函数了,就没有意义了。
接下来就是按照这个思路将网络结构加深了,下面列出几种结构:
最后是一个更深的瓶颈结构问题,论文中用三个1x1,3x3,1x1的卷积层代替前面说的两个3x3卷积层,第一个1x1用来降低维度,第三个1x1用来增加维度,这样可以保证中间的3x3卷积层拥有比较小的输入输出维度。

好了,resNet读到这里基本上差不多了,当然啦,后来又出了resNet的加宽版resNeXt,借鉴了GoogLeNet的思想,以后有机会再细读!
到底Resnet在解决一个什么问题呢?
理论上深层的神经网络一定比浅层的要好,比如深层网络A,浅层网络B,A的前几层完全复制B,A的后几层都不再改变B的输出,那么效果应该是和B是一样的。也就是说,A的前几层就是B,后几层是线性层。但是实验发现,超过一定界限之后,深层网络的效果比浅层的还差。一个可能的解释是:理论上,我们可以让A的后几层输入等于输出,但实际训练网络时,这个线性关系很难学到。既然如此,我们把这个线性关系直接加到网络的结构当中去,那么效果至少不必浅层网络差。也就是说,Resnet让深层神经网络更容易被训练了。
实际操作中,加上这个residual,我们一方面可以做的更深,这样网络表达的能力更好了,一方面训练的也更快了,至少比VGG快多了。
大意是神经网络越来越深的时候,反传回来的梯度之间的相关性会越来越差,最后接近白噪声。因为我们知道图像是具备局部相关性的,那其实可以认为梯度也应该具备类似的相关性,这样更新的梯度才有意义,如果梯度接近白噪声,那梯度更新可能根本就是在做随机扰动。
有了梯度相关性这个指标之后,作者分析了一系列的结构和激活函数,发现resnet在保持梯度相关性方面很优秀(相关性衰减从 到了 )。这一点其实也很好理解,从梯度流来看,有一路梯度是保持原样不动地往回传,这部分的相关性是非常强的。
推荐:1, 2, 3, 4