HIVE中join连接全解析
续写:SQL ON Hadoop-Hive(二)-DDL数据定义语言
1.多表join
select * from table1 t1 join table2 t2 on t1.id=t2.id join table3 t3
on t1.id=t3.id --第一个作业的输出与表3的连接操作
--目前hive只支持等值join,不支持非等值的连接(很难转化成map/reduce任务)可以join多于两个表,执行流程分析
--如果join多个表时,join key是同一个,则join会被转化为单个map/reduce任务,reducer端会缓存a表和b表的记录,然后每取得一次c表记录就计算一次join结果
select a.val,b.val,c.val from a join b on (a.key=b.key1) join c on (c.key=b.key1)
--如果join key非同一个,则join会被转化为多个map/reduce任务
select a.val,b.val,c.val from a join b on (a.key=b.key1) join c on (c.key=b.key2)
--join被转化为2个map/reduce任务.因为b.key1用于第一次join条件,b.key2用于第二次join,第一次缓存a表用b表序列化,第二次缓存第一次map/reducer任务结果,然后用c表序列化2.join时每次map/reducer的任务逻辑
reducer会缓存join序列中除最后一个表所有表的记录,再通过最后一个表将结果序列化到文件系统(有助于在reducer端减少内存使用量,实践中应该把最大那个表放在最后)
3.左半连接
hive特有语法,返回左表记录,前提是左表记录对于右边表满足on语句中的判定条件,被用来代替标准SQL中exists\in的操作(右表字段只能出现在on子句中,不能出现在select和where子句中引用,没有right semi join)
其实内连接也可以实现同样目的,但前者更高效(对于左表中的一条指定记录,在右表中一旦找到匹配记录,hive就停止扫描)
select t1.id from table_name t1 left semi join table_name2 t2 on t1.id=t2.id4.join发生在where子句之前(以left/right outer join为例)
select a.val,b.val from a left outer join b on (a.key=b.key) where a.ds='2016-12-30' and b.ds='2016-12-30'
问题描述:如果b找不到对应a表的记录,所有列都会列出null包括ds列.也就是说join会过滤掉b表中不能找到匹配a表join key的所有记录,导致LEFT OUTER与where子句无关(是将left outer join后的结果进行where条件筛选)
解决方案:在left out时使用条件
select a.val,b.val from a left outer join b on (a.key=b.key and b.ds='2016-12-29' and a.ds='2016-12-29')
说明1:这一查询结果是预先在join阶段过滤的,所以不会存在上述的问题.这一逻辑可以用于right 和full类型join中
说明2:过滤条件写在on上面会让基表所有数据都能显示,不满足条件的右表以null填充,当过滤条件写在where上只会让符合筛选条件的数据显示
--hive实例
select r.phone_num,r.lab1,s.phone_num,s.lab1 from hkdw_dk_edu r left outer join hkdw_dk_edu s on (r.phone_num=s.phone_num and s.lab1='dk_seyy' and r.lab1='dk_sryyss') where r.lab1='dk_sryyss' and s.phone_num is null5.内连接+全连接
--如果单独用join,如select ... from table_name1 a join table_name2 b on a.id=b.id表示内连接,full outer join全连接6.map side join
如果在连接的表中有一张是小表,在map阶段完全可以将小表读到内存中,直接在map端进行join,这种操作可以明显降低join所耗费的时间
select /*+MAPJOIN(t1)*/ t1.id,t2.id from table1 t1 join table2 t2 on t1.id=t2.id
--如果想让hive自动开启这个优化,设置hive.auto.convert.join=true(这样hive会在必要时自动执行map端join,自动获取两张表的数据,判定哪张是小表放到内存中)
--自动转换为mapjoin
set hive.auto.convert.join = true;
--小表的最小文件大小,默认值为25Mb
set hive.mapjoin.smalltable.filesize = 25000000;
--是否将多个mapjoin合并为一个
set hive.auto.convert.join.noconditionaltask = true;
--多个mapjoin转换为1个时,所有小表的文件大小总和的最大值。
set hive.auto.convert.join.noconditionaltask.size = 10000000;7.hive的三种join方式
1.reduce join在hive中也称common join或shuffle join。适合两边数据量都较大的join,它会把相同key的value合在一起(相同的key被拖拽到同一个reducer),然后再去组合(在reduce端完成join)

set mapreduce.map.memory.mb=2049;
set mapreduce.reduce.memory.mb=20495;
set hive.auto.convert.join=false;2.map join
参考第六点,适合一张表的数据量很大另外一张表很少(通常<=1000行)的join,那么可将数据量少的表放到内存中,在map端做join,省去reduce运行效率会高很多
不等值join:例如a.x 3.SMB( sort merge buket) join 使用场景:大表对大表。在运行SMS join时会重新创建两张表(后台默认做的,不需要用户主动创建) select /*+ MAPJOIN(a) */
a.start_level, b.*
from dim_level a inner
join (select * from test) b
where b.xx>=a.start_level and b.xx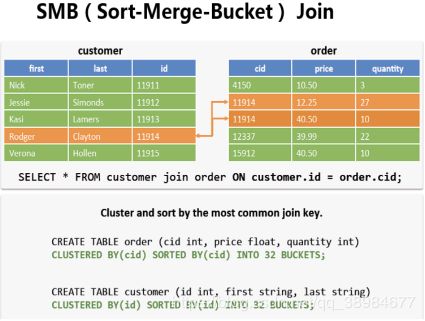
set hive.auto.convert.sortmerge.join=true
set hive.optimize.bucketmapjoin=true;
set hive.optimize.bucketmapjoin.sortedmerge=true;