注:
1、本课完整的爬虫代码可以在神箭手示例代码中查看:http://www.shenjianshou.cn/index.php?r=demo/docs&demo_id=500004
2、如何在神箭手上运行代码,请查看文档:http://docs.shenjianshou.cn/overview/guide/develop/crawler.html
3、更详细的爬虫开发教程,请查看文档:http://docs.shenjianshou.cn/develop/summary/summary.html
大家好,好久不见了!游牧老师最近一直在忙着开发咱们神箭手的平台功能,近期我们又上线了很多强大的function,还上线了新版更萌萌哒的官网(大家喜欢么( ̄▽ ̄)”)
今天继续给大家讲解新的爬虫开发知识点:如何爬取列表页的数据
看过之前两课的童鞋们应该对神箭手上开发爬虫的基本过程很了解了,数据都是从内容页中使用xpath进行抽取的。那么在实际开发中,我们会遇到数据需要从列表页中抽取的情况,举个栗子:
打开网址:http://hy.87870.com/news/list-0-0-1.html
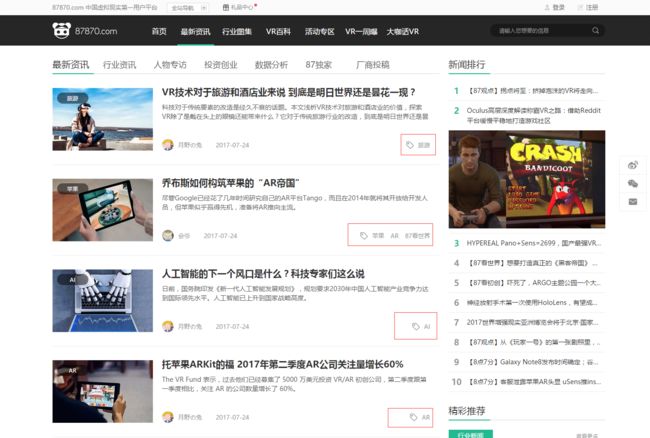
我们要爬取87870最新资讯里的文章,包括文章标签。我们可以看到文章标签(如上图红圈内的)是在文章列表页中的,那么就需要从列表页中抽取数据啦~
神箭手提供了”内容页附加数据”的方式将列表页数据添加到内容页内容中,从而统一从内容页抽取数据的方式,从而可以轻松爬取到列表页数据:http://docs.shenjianshou.cn/develop/configs/field.html#SourceType-UrlContext
基本过程呢,主要分为两步:
第一步,在onProcessHelperPage回掉函数中,从列表页读取需要的数据,附加给内容页URL
configs.onProcessHelperPage = function(page, content, site){
var contentList = extractList(content, "//ul[contains(@class,'news-list')]/li");
if(!contentList){
return false;
}
for(var i=0;i
// 1、获取列表页中每篇文章的tags数据
var tags = extract(contentList[i], "//span[contains(@class,'keyword')]");
var contentUrl = extract(contentList[i], "//a[contains(@class,'news-tit')]/@href");
var options = {
method: "GET",
contextData: '
'+tags+'
' // 将tags数据添加到options的contextData中
};
// 2、将options附加到内容页中,再将内容页链接添加到待爬队列中
site.addUrl(contentUrl, options);
}
// 判断是否有下一页列表页以及将下一页列表页链接添加到待爬队列中
var nextPage = extract(content, "//a[contains(@class,'next')]/@href");
if(nextPage){
site.addUrl(nextPage);
}
return false; //不让爬虫自动发现新的待爬链接
};
第二步,在抽取fields中,添加从UrlContext方式抽取
{
name: "article_tags",
alias: "标签",
// 3、从之前添加到内容页中的附加数据中抽取文章标签
sourceType: SourceType.UrlContext, // 将抽取的数据来源设置为UrlContext
selector: "//div[@id='sjs-tags']//a/text()",
repeated : true
}
是不是很简单啊?神箭手为开发者们提供了最简单和灵活的调用处理方式!
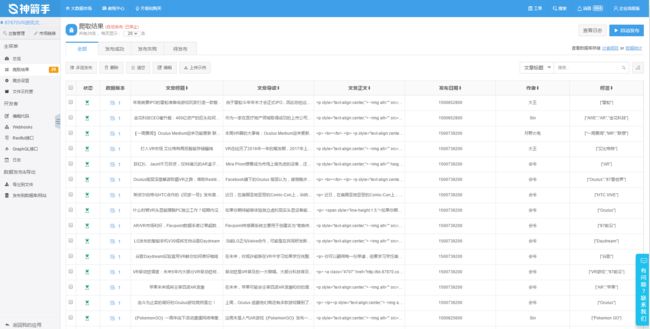
爬取结果截图:
完整的代码在这里:
http://www.shenjianshou.cn/index.php?r=demo/docs&demo_id=500004
p.s. 更多爬取列表页数据的例子,请点我查看:http://docs.shenjianshou.cn/develop/advance/useUrlContext.html
再p.s. 如何把爬取的数据发布到自己的系统或者导出到本地文件,看这里:http://docs.shenjianshou.cn/use/publish/summary.html