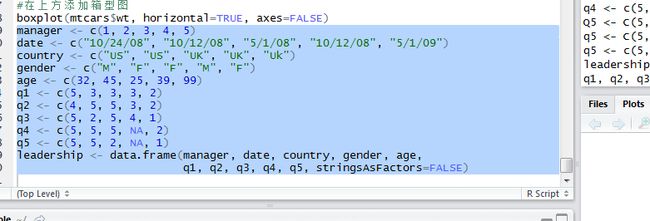
为了解决感兴趣的问题,我们首先必须解决一些数据管理方面的问题。
4.2 创建新变量
在典型的研究项目中,你可能需要创建新变量或者对现有变量进行转换。这可以通过以下形式的的语句来完成:
变量名←表达式
以上语句中“表达式”部分可以包含多种运算符和函数。算数运算符可以用于构造公式(formula)。
表4-2 算数运算符
运算符 描述
+ 加
- 减
* 乘
/ 除
︿或** 求冥
x%%y 求余(x mod y).5%%2的结果为2
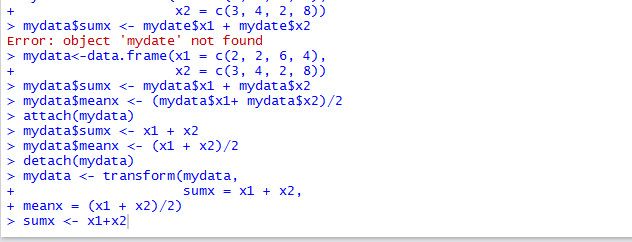
假设你有一个名为mydata的数据框,其中一个变量为x1和x2,现在你想创建一个新变量sumx存储以上两个变量的加和,并创建一个名为meanx的新变量存储这两个变量的均值。以上代码清单提供了三种不同的方式实现这个目标,具体选择自己决定,本书作者倾向于第三种方式,即transform()函数的一个示例。这种方式简化了按需创建新变量并将其保存到数据框的过程。
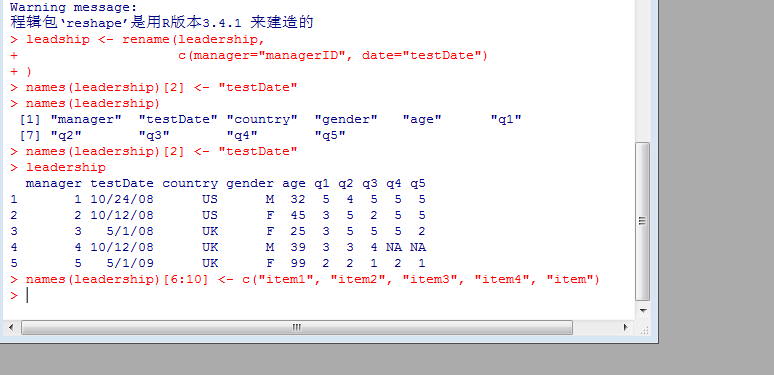
reshape包拥有一系列强大的数据集结构修改函数,最后,可以通过names()函数来重命名变量,以上代码中将date重命名为testDate。
4.5 缺失值
在r中,缺失值以符号NA(Not Available,不可用)表示。不可能出现的值(例如,被0除的结果)通过符号NaN(Not a Number,非数值)来表示。与SAS等程序不同,r中字符型和数值型数据使用的缺失值符号是相同的。
r提供了一些函数,用于识别包含缺失值的观测。函数is.na()允许你检测缺失值是否存在。假设你有一个向量:
y <- c(1, 2, 3, NA)
然后使用函数
is.na(y)
将返回c(FALSE,FALSE,FALSE,TRUE).
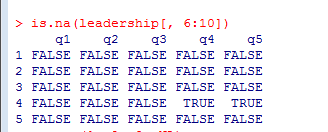
这里的leadership[, 6:10]将数据框限定到第6列至第10列,接下来is.na()识别出了缺失值。
4.5.1重编码某些值为缺失值
如同4.3节中演示的那样,你可以使用赋值语句将某些重编码为缺失值。在我们的leadership示例中,缺失的年龄值被编码为99.在分析这一数据集之前,你必须让r明白本例中的99表示缺失值。你可以通过重编码这个变量完成这项工作
leadership$age[leadefship$age == 99] <- NA
任何等于99的年龄值都将被修改为NA.
4.5.2 在分析中排除缺失值
确定了缺失值的位置以后,你需要进一步分析数据之前以某种方式删除这些缺失值。原因是,含有缺失值的算术表达式和函数的计算结果也是缺失值。

由于x中的第三个元素是缺失值,所以y和z也都是NA(缺失值)。
好在多数函数都拥有一个na.rm=TRUE选项,可以在计算之前移除缺失值并用剩余值进行计算:
x <- c(1, 2, NA, 3)
y <- sum(x, na.rm=TRUE)
这里,y等于6
在使用函数处理不完整的数据时,请务必查阅他们的帮助文档(例如,help(sum)),检查这些函数是如何处理缺失数据的。
你可以通过函数na.omit()移除所有含缺失值的观测。na.omit()可以删除所有含有缺失数据的行。
代码清单4-4 使用na.omit()移除所有含缺失值的观测。

在结果被保存到newdata之前,所有包含缺失数据的行均已从leadership中删除。
删除所有含有缺失数据的观测(成为行删除,list deletion)是处理不完整数据集的若干手段之一。
4.6 日期值
日期值通常以字符串的形式输入到R中,然后转化为以数值的形式存储的日期变量。函数as.date()用于执行这种转化。其语法为as.Date(x,"input_format"),其中x是字符型数据,input-format则给出了用于读入日期的适当格式
符号 含义 示例
%d 数字表示的日期 01~31
%a 缩写的星期名 Mon
%A 非缩写星期名 Monday
%m 月份(00~12) 00~12
%b 缩写的月份 Jan
%B 非缩写的月份 January
%y 两位数的年份 07
%y 四位数的年份 2007
日期值得默认输入格式为yyyy-mm-dd。
语句:
mydates <- as.Date(c("2007-06-22", "2004-02-13"))
将默认格式的字符型数据转换为了对应日期。相反,
steDates <- c("01/05/1965","08/16/1975")
dates <- as.date(strDates,"%m/%d/%y")
则使用mm/dd/yyyy的格式读取数据。
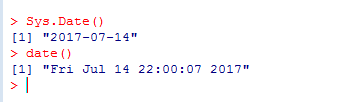
有两个函数对于处理时间戳数据特别实用。Sys.Date()可以返回当天的日期,而date()则返回当前的日期和时间。我写下这段文字的时间是2010年12月1日下午4:28.所以执行这些函数的结果是:
你可以使用函数format(x,format=“output-fomat”)来输出指定格式的日期值,并且可以提取日期值中的某些部分:
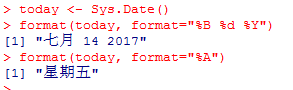
format()函数可接受一个参数(本例中是一个日期)并按某种格式输出结果(本例中使用了表4-4中符号的组合)。
R的内部在存储日期时,是使用自1970年1月1日以来的天数表示的,更早的日期则表示为负数。这意味着可以在日期值上执行算术运算。例如:
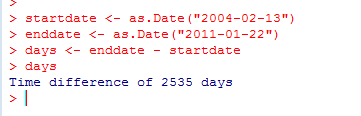
显示了2004年2月13日和2011年1月22日之间的天数。
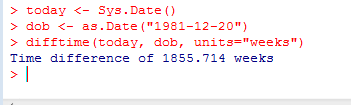
最后,也可以使用函数difftime()来计算时间间隔,并以星期、天、时、分、秒来表示。
假设我出生于1981年12月20日,我现在有多大了呢?
4.6.1 将日期转换为字符型变量
函数as.character()可将日期值转换为字符型:strDates <- as.character(dates)
进行转换后,即可使用一系列字符处函数处理数据理
4.6.2 更进一步
4.7 类型转换
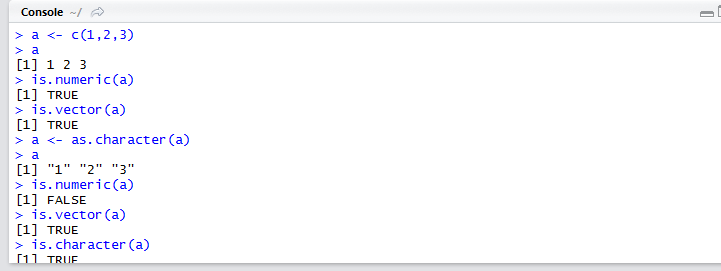
你可以使用表4-5中列出的函数来判断数据的类型或者将其转换为指定类型。
表4-5 类型转换函数
判断 转换
is.numeric() as.numeric()
is.character() as.character()
is.vector() as.vector()
is.matrix() as.matrix()
is.data.frame() as.date.frame()
is.factor() as.factor()
is.logical() as.logical()
名为is.datatype()这样的函数返回TRUE或FALSE,而as.datatype()这样的函数则将其参数转换为对应的类型。
代码清单4-5提供了一个示例
代码清单4-5 转换数据类型
4.8 数据排序
在R中,可以使用order()函数对一个数据框进行排序。默认的排序顺序是升序。在排序变量的前边加一个减号即可得到降序的排序结果。一下示例使用leadership演示了数据框的排序。
语句:
本章问题1:为什么使用attach(leadership)会出现以上的错误,这样的问题已经一再出现了,基本只要使用attach()就会出现以上类似的提示????????
4.9 数据集的合并
如果数据分散在多个地方,你就需要在继续下一步之前将其合并。
4.9.1 添加列
要横向合并两个数据框(数据集)请使用merge()函数。在多数情况下,两个数据框是通过一个或多个共有变量进行联结的(即一种内联结,innerjoin)。例如:

注意 如果要直接横向合并两个矩阵或数据框,并且不需要指定一个公共索引,那么可以直接使用cbind()函数:
total <- cbind(A, B)
这个函数将横向合并对象A和对象B.为了让它正常工作,每个对象必须拥有相同的行数,且要以相同顺序排序。
4.9.2 添加行
要纵向合并两个数据框(数据集),请使用rbind()函数:
total <- rbind(datafameA,dataframeB)
两个数据框必须拥有相同的变量,不过它们的顺序不必一定相同。如果dataframeA中拥有dataframeB中没有的变量,请在合并他们之前做以下某种处理:
。删除dataframeA中的多余变量
。在dataframeB中创建追加的变量并将其值设为NA(缺失)
纵向联结通常用于向数据框中添加观测。
4.10 数据集取子集
4.10.1 选入(保留)变量
从一个大数据集中选择有限数量的变量来创建一个新的数据集是常有的事。在第二章中,数据框中的元素是通过dataframe[row indices, column indices]这样的记号来访问的。你可以沿用这种方法来选择变量:
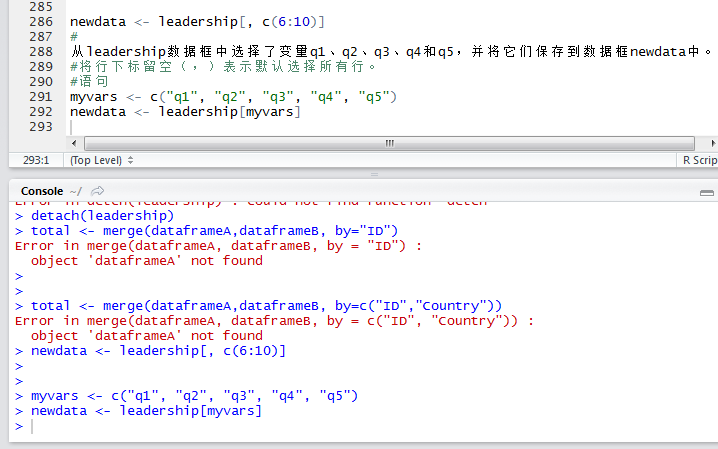
实现了等价的变量选择。这里,(引号中的)变量名充当了列的下标,因此选择的列是相同的。
最后,其实你可以写:

本例使用paste()函数创建了与上例中相同的字符型向量。
4.10.2 剔除(丢弃)变量
剔除变量的原因有很多。举例来说,如果某个变量中有若干缺失值,你可能就想在进一步分析之前将其丢弃。下面是一些剔除变量的方法。
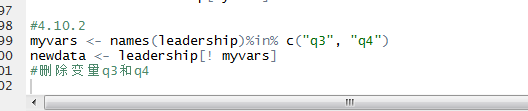
为了理解以上语句的原理,你需要把它拆解如下。
1、names(leadership)生成了一个包含所有变量名的字符型向量:
c(“managerID","testDate”,“country”,“gender”,“age”,“q1”,“q2”,“q3”,“q4”,“q5”)。
2.names(leadership) %in%c(“q3”, “q4”)返回了一个逻辑型向量,names(leadership)中每个匹配q3或q4的元素的值为TRUE,反之为FALSE:c(FALSE, FALSE, FALSE, FALSE, FALSE, FALSE,FALSE, TRUE, TRUE, FALSE).
3.运算符非(!)将逻辑值反转:c(TRUE, TRUE, TRUE, TRUE, TRUE, TRUE, TRUE, FALSE, FALSE, FALSE, TRUE).
4.leadership[c(TRUE,TRUE,TRUE,TRUE,TRUE,TRUE,TRUE,FALSE,FALSE,TRUE)]选择了逻辑值为TRUE的列,于是q4和q4被剔除了。
在知道了q3和q4是第8个和第9个变量的情况下,可以使用语句:
newdata <- leadership[c(-8, -9)]
将它们剔除。这种方式的工作原理是,在某一列的下标之前加一个减号(?)就会剔除那一列。
末了,相同的变量删除工作亦可通过:
leadership$q3 <- leadership$q4 <- NULL
来完成。这回你将q3和q4两列设为了未定义(NULL).注意,NULL与NA(表示缺失是不同的。丢弃变量是保留变量的逆向操作。选择哪一种方式进行变量筛选依赖于两种方式的编码难易程度。如果有许多变量需要丢弃,那么直接保留需要的留下的变量可能更简单,反之亦然。
4.10.3 选入观察
选入或剔除观测(行)通常是成功的数据准备和数据分析的一个关键方面。
代码清单4-6 选入观测

在本章开始的时候,我曾经提到,你可能希望将研究的范围限定在2009年1月1日到2009年12月31日之间的收集的观测上。
leadership$date <- as.Date(leadership$date, "%m/%d/%y")
startdate <- as.Date("2009-01-01")
enddate <- as.Date("2009-10-31")
<- leadership[which(leadership$date >=stardate &
leadership$date <= enddate),]
首先,使用格式mm/dd/yy将开始作为字符值读入的日期转换为日期值。然后创建开始日期和结束日期。由as.Date()函数的默认格式就是yyyy-mm-dd,所以你必须在这里提供这个参数。
4.10.4 subset()函数
前两节中的示例很重要,因为他们辅助描述了逻辑型向量和比较运算符在R中的解释方式。

???上面出现了“select=c(q1,q2,q3,q4))弹出了上图最后一列的问题是上面原因,我的猜想是之前的记录中没有输入相关数据,导致后面找不到?
在第一个示例中,你选择了所有age的值大于或等于35或age值小于24的行,保留了变量q1到q4.在第二个示例中,你选择了所有25岁以上的男性,并保留了变量gender到q4(gender、q4和其间所有列)。
4.10.5 随机抽样
sample()函数能够让你从数据集中(有放回或无放回地)抽取大小为n的一个随机样本。
你可以使用以下语句从leadership数据集中随机抽取一个大小为3的样本:
mysample <- leadership[sample(1:nrow(leadership), 3, replace=FALSE),]
sample()函数中的第一个参数是一个要从中抽样的元素组成的向量。在这里,这个向量是1到数据框中观测的数量,第二个参数是要抽取的元素数量,第三个参数表示无法取回抽样。
sample()函数会返回随机抽样得到的元素,之后即可用于选择数据框中的行。
4.11 使用SQL语句操作数据框
4.12 小结
我们