# -*- coding: utf-8 -*-
import time
import urllib
import urllib2
import cookielib
from lxml import etree
import random
'''
爬取第一页,获取共页数
爬取第二页至最后一页
'''
# 下载当前页所有文章的pdf或caj
def download_paper(treedata, opener, localdir):
'''
传入参数:
treedata:当前列表页的treedata数据
opener: referer已修改为当前页
localdir: 保存目录
'''
tr_node = treedata.xpath("//tr[@bgcolor='#f6f7fb']|//tr[@bgcolor='#ffffff']")
for item in tr_node:
paper_title = item.xpath("string(td/a[@class='fz14'])")
paper_link = item.xpath("td/a[@class='fz14']/@href")
paper_author = item.xpath("td[@class='author_flag']/a/text()")
paper_source = item.xpath("td[4]/a/text()")
paper_pub_date = item.xpath("td[5]/text()")
paper_db = item.xpath("td[6]/text()")
paper_cited = item.xpath("td[7]//a/text()")
paper_download_count = item.xpath("td[8]/span/a/text()")
print paper_title
print paper_link
# 获取paper详情页面链接,访问详情页前,要设置referer
paper_detail_url_fake = "http://kns.cnki.net" + paper_link[0]
response = opener.open(paper_detail_url_fake)
paper_detail_page_treedata = etree.HTML(response.read())
# 下载前要设置referer为详情页
opener.addheaders = [("Referer", response.url)]
# 硕士论文并没有【pdf下载】的链接
pdf_download_url = paper_detail_page_treedata.xpath('//*[@id="pdfDown"]/@href')
if len(pdf_download_url) == 0:
whole_book_download_url = paper_detail_page_treedata.xpath('//*[@id="DownLoadParts"]/a[1]/@href')
download_url = whole_book_download_url[0]
filename = localdir + paper_title + ".caj"
else:
download_url = pdf_download_url[0]
filename = localdir + paper_title + ".pdf"
filename.replace("\\", "").replace("/","").replace(":", "").replace("*", "").replace("?", "").replace("\"","").replace("<","").replace(">","").replace("|","")
response_file = opener.open(download_url)
down_file = open(filename, 'wb')
down_file.write(response_file.read())
down_file.close()
# 构建第一次请求时使用的URL
url = 'http://kns.cnki.net/kns/request/SearchHandler.ashx?action=&NaviCode=*&'
parameter={'ua':'1.11'}
parameter['formDefaultResult']=''
parameter['PageName']='ASP.brief_default_result_aspx'
parameter['DbPrefix']='SCDB'
parameter['DbCatalog']='中国学术文献网络出版总库'
parameter['ConfigFile']='SCDBINDEX.xml'
parameter['db_opt']='CJFQ'
parameter['db_opt']='CJFQ,CJRF,CDFD,CMFD,CPFD,IPFD,CCND,CCJD'
parameter['txt_1_sel']='SU$%=|'
parameter['txt_1_value1']='爬虫'
parameter['txt_1_special1']='%'
parameter['his']='0'
parameter['parentdb']='SCDB'
parameter['__']='Sun Nov 05 2017 20:09:05 GMT+0800 (中国标准时间) HTTP/1.1'
times = time.strftime('%a %b %d %Y %H:%M:%S')+' GMT+0800 (中国标准时间)'
parameter['__']=times
getdata = urllib.urlencode(parameter)
uapools = [
"Mozilla/5.0 (Windows NT 6.1; WOW64; rv:34.0) Gecko/20100101 Firefox/34.0",
"Mozilla/5.0 (X11; U; Linux x86_64; zh-CN; rv:1.9.2.10) Gecko/20100922 Ubuntu/10.10 (maverick) Firefox/3.6.10",
"Mozilla/5.0 (Windows NT 6.1; WOW64; rv:34.0) Gecko/20100101 Firefox/34.0",
"Mozilla/5.0 (X11; U; Linux x86_64; zh-CN; rv:1.9.2.10) Gecko/20100922 Ubuntu/10.10 (maverick) Firefox/3.6.10",
"Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/534.57.2 (KHTML, like Gecko) Version/5.1.7",
"Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/39.0.2171.71",
"Mozilla/5.0 (X11; Linux x86_64) AppleWebKit/537.11 (KHTML, like Gecko) Chrome/23.0.1271.64 Safari/537.11"
]
headers = {'Connection': 'Keep-Alive','Accept': 'text/html,*/*','User-Agent': 'Mozilla/5.0 (Windows NT 6.2; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/29.0.1547.66 Safari/537.36'}
headers['Referer']='http://kns.cnki.net/kns/brief/default_result.aspx'
#headers['User-Agent'] = random.choice(uapools)
req = urllib2.Request(url + getdata, headers=headers)
cookie = cookielib.CookieJar()
opener = urllib2.build_opener(urllib2.HTTPCookieProcessor(cookie), urllib2.HTTPHandler)
html = opener.open(req).read()
with open('C:/code/test3/web1.html', 'w') as e:
e.write(html)
# 构建第二次请求时使用的URL
query_string = urllib.urlencode({'pagename': 'ASP.brief_default_result_aspx','dbPrefix':'SCDB', 'dbCatalog': '中国学术文献网络出版总库',
'ConfigFile': 'SCDBINDEX.xml', 'research':'off', 't': int(time.time()), 'keyValue': '爬虫', 'S': '1'})
url2 = 'http://kns.cnki.net/kns/brief/brief.aspx'
req2 = urllib2.Request(url2 + '?' + query_string, headers=headers)
# 返回的是搜索结果列表页,第一页
result2 = opener.open(req2)
#opener.addheaders = [("Referer", req2.get_full_url())]
html2 = result2.read()
with open('C:/code/test3/web2.html', 'w') as e:
e.write(html2)
treedata = etree.HTML(html2)
# 请求详情页之前把引用地址改成列表页
opener.addheaders = [("Referer", req2.get_full_url())]
localdir = "C:/code/test3/pdf/"
download_paper(treedata, opener, localdir)
#获取总页数total_page_count
current_page_node = treedata.xpath('//span[@class="countPageMark"]/text()')
print "current_page_node:", current_page_node
total_page_count = current_page_node[0].split('/')[1]
print "total_page_count:", total_page_count
current_url = result2.url
for page_num in range(2, int(total_page_count)+1):
#获取下一页的链接
print "准备爬取第", str(page_num), "页"
next_page_node = treedata.xpath('//div[@class="TitleLeftCell"]/a[last()]/@href')
next_page_url = next_page_node[0]
next_page_url_full = url2 + next_page_url
opener.addheaders = [("Referer", current_url)]
# 返回的是搜索结果下一页的列表页
next_page_response = opener.open(next_page_url_full)
opener.addheaders = [("Referer", next_page_response.url)]
#file_next_page = open('C:/code/test3/web4' + str(page_num) + '.html', 'w')
html = next_page_response.read()
#file_next_page.write(html)
#file_next_page.close()
#print "current_url:", current_url
#print "next_page_url:", next_page_response.url
# 修改上一页,以供请求下页时引用
#result2 = next_page_response
treedata = etree.HTML(html)
current_url = next_page_response.url
localdir = "C:/code/test3/pdf/"
download_paper(treedata, opener, localdir)
最新代码
https://github.com/tom523/crawlCnki.git
爬虫夹故障
- 服务器响应超时
- 验证码输入
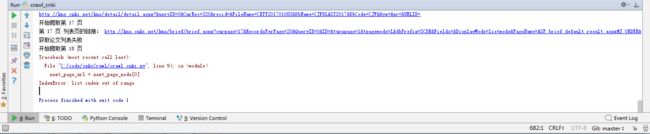
image.png
不只一次的在第17页,需要输入验证码

image.png
处理方法:重新更换User-Agent后,直接从第17页开始爬取
20171110日志
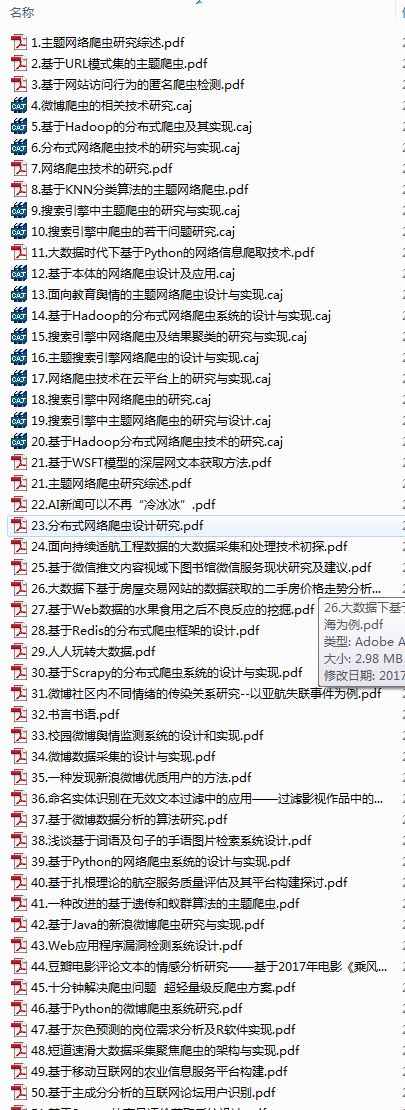
image.png
20171109晚上爬取结果,搜索关键字“爬虫”,看起来像是给了假数据,可能知网检测出来了爬虫。