一开始我是学习崔大神的flask和redis动态代理池,可惜里面的异步检查以及请求,还有元类的编程(看了整整一天,实在没有完全搞懂),我就算照着写也报错不断,于是今天自己写了一个代理池,也实现了一样的功能,先说一下代理池主要的思路,首先是启动一个主进程,然后分别创建两个子进程,一个是定期测试IP,一个是定期检查IP数量,符合要求则不用进行抓取,不符合要求则进行抓取,同时记得启动tornado框架,让我们可以在浏览器访问,然后获得代理。楼主对于代理的测试用的是线程池,用协程实在没有信心写好,git_hub地址是https://github.com/xiaobeibei26/dynamic_ip_pool
代码下载之后,大家只要运行了里面的run文件就不用管了,代理池会自己启动,自己刷新,你可用在别的脚本或者浏览器提取用就好了
这里先看一看关键的两个子进程的代码
from ip_pool.database import RedisConnect#导入数据库链接
import requests
import re
from ip_pool.ip_request import FreeProxyGetter
from ip_pool.Thread_pool import ThreadPool
import time
from multiprocessing import Process
check_time = 50#多久检查一次IP的有效性
count_time =50#多久严查一次IP数量是否够
lower_num_ip = 30#最少的IP数量
max_num_ip = 70#最多的IP数量
class Test_ip(object):#用于测试IP
def __init__(self):
self.url='http://ip.chinaz.com/getip.aspx'#用于测试的url
self._conn=RedisConnect()
self._raw_proxies =None
self.Thread_pool =ThreadPool(10)
def set_raw_proxies(self,proxies):#接收以备测试的代理
self._raw_proxies =proxies
def _test(self,proxy):#测试IP
if isinstance(proxy,bytes):
proxy=proxy.decode('utf-8')
real_proxy= {'http':'http://{}'.format(proxy),
'https':'http://{}'.format(proxy),}
print('正在测试,',proxy)
try:
html = requests.get(self.url, proxies=real_proxy, timeout=1)
status_number = re.findall(r'\d\d\d', str(html))[0] # 提取网页返回码
re_ip = re.findall(r'\{ip', html.text) # 有些 ip极其恶心,虽然返回的是200数字,表示正常,实则是bad request,这里去除掉
if status_number == str(200):
if re_ip:
# 检验代理是否能正常使用
self._conn.put(proxy)
print('网页返回状态码:', html, proxy, '代理有效,地址是:', html.text)
except Exception as e:
print('移除无效代理,',proxy)
def Thread_test_ip(self,proxies):#传进去一个列表
for proxy in proxies:
self.Thread_pool.run(func=self._test, args=proxy) # 用多线程测试
print('本次测试用了多少线程',len(self.Thread_pool.generate_list))
class Get_ip(object):
def __init__(self,max_ip_count=max_num_ip):#默认IP池里面最多的IP上面设置好了
self._conn=RedisConnect()
self.max_ip_count=max_ip_count
self.crawl=FreeProxyGetter()
self.Test=Test_ip()
self.Thread_pool=ThreadPool(10)#用于多线程测试,这里设置最多10个线程
def is_ip_enough(self):
if self._conn.ip_count >= self.max_ip_count:#如果池里IP数大于规定最大的数量,则返回False
return False
return True
def catch_ip(self):
while self.is_ip_enough():
print('代理数量不足,代理抓取中')
for callback_lable in range(self.crawl.__CrawlFuncCount__):#该方法在元类里面添加了
callback = self.crawl.__CrawlFunc__[callback_lable]
raw_proxies = self.crawl.get_raw_proxies(callback)#这是接收抓取的代理
if raw_proxies:
self.Test.Thread_test_ip(raw_proxies)
else:
print('该源头没有代理')
class schedule(object):
@staticmethod
def check_ip(cycle_time=check_time):
conn = RedisConnect()
tester = Test_ip()
while True:
print('IP检查程序启动')
count= int(0.5 * conn.ip_count)
if count == 0:
time.sleep(cycle_time)
continue
raw_proxies = conn.get_to_test(count)
tester.Thread_test_ip(raw_proxies)#将列表传进去
time.sleep(cycle_time)
@staticmethod
def catch_ip(cycle_time = count_time,max_ip=max_num_ip,min_ip=lower_num_ip):#时间多久检查一次IP数量是否足够
conn= RedisConnect()
Ip_catch = Get_ip()
while True:
if conn.ip_count 这么长的代码,我也懒得再看了,其主要功能就是同事运行两个进程,一个检查IP数量,一个测试质量
数据库的操作也很简单
import redis
class RedisConnect(object):
def __init__(self):
self.db=redis.Redis(host='localhost',port=6379)
def get_to_test(self,count=1):#获取代理以备检查
proxy = self.db.lrange('proxies',0,count-1)
self.db.ltrim('proxies',count,-1)
return proxy
def put(self,proxy):#放进一个代理
self.db.rpush('proxies',proxy)
def pop(self):#获取一个代理,然后提出
try:
return self.db.rpop('proxies')
except Exception as e:
return '没有代理可用'
@property
def ip_count(self):#获取代理数量
return self.db.llen("proxies")
这里值得一提的是元类的编程,如图这是代理抓取的代码
from .html_request import MyRequest
from pyquery import PyQuery as pq
from bs4 import BeautifulSoup
class ProxyMetaclass(type):
"""
__CrawlFunc__和__CrawlFuncCount__
两个参数,分别表示爬虫函数,和爬虫函数的数量。
"""
def __new__(cls, name, bases, attrs):#这几个是固定参数
count = 0
attrs['__CrawlFunc__'] = []
for k, v in attrs.items():
if 'crawl_' in k:#检查每个方法里面的key值是否有crawl字符,然后运行,方便以后添加代理的抓取进去
attrs['__CrawlFunc__'].append(k)
count += 1
attrs['__CrawlFuncCount__'] = count
return type.__new__(cls, name, bases, attrs)
class FreeProxyGetter(object, metaclass=ProxyMetaclass):
def get_raw_proxies(self, callback):
proxies = []
print('Callback', callback)
for proxy in eval("self.{}()".format(callback)):#eval这里用于执行字符串
print('Getting', proxy, 'from', callback)
proxies.append(proxy)
return proxies
def crawl_daili66(self, page_count=4):
start_url = 'http://www.66ip.cn/{}.html'
urls = [start_url.format(page) for page in range(1, page_count + 1)]
for url in urls:
print('Crawling', url)
try:
html = MyRequest.get(url,3)
if html:
doc = pq(html)
trs = doc('.containerbox table tr:gt(0)').items()
for tr in trs:
ip = tr.find('td:nth-child(1)').text()
port = tr.find('td:nth-child(2)').text()
yield ':'.join([ip, port])
except Exception as e:
print('Crawling faild', url)
def crawl_proxy360(self):
start_url = 'http://www.proxy360.cn/Region/China'
print('Crawling', start_url)
try:
html = MyRequest.get(start_url,3)
if html:
doc = pq(html)
lines = doc('div[name="list_proxy_ip"]').items()
for line in lines:
ip = line.find('.tbBottomLine:nth-child(1)').text()
port = line.find('.tbBottomLine:nth-child(2)').text()
yield ':'.join([ip, port])
except:
print('Crawling faild', start_url)
def crawl_goubanjia(self):
start_url = 'http://www.goubanjia.com/free/gngn/index.shtml'
try:
html = MyRequest.get(start_url,3)
if html:
doc = pq(html)
tds = doc('td.ip').items()
for td in tds:
td.find('p').remove()
yield td.text().replace(' ', '')
except:
print('Crawling faild', start_url)
def crawl_haoip(self):
start_url = 'http://haoip.cc/tiqu.htm'
try:
html =MyRequest.get(start_url,3)
if html:
doc = pq(html)
results = doc('.row .col-xs-12').html().split('
')
for result in results:
if result: yield result.strip()
except:
print('Crawling faild', start_url)
def crawl_xici(self):#西刺网的爬取
start_url ='http://www.xicidaili.com/nn/1'
try:
data = MyRequest.get(start_url, 3)
all_data = BeautifulSoup(data, 'lxml')
all_ip = all_data.find_all('tr', class_='odd')
for i in all_ip:
ip = i.find_all('td')[1].get_text() # ip
port = i.find_all('td')[2].get_text() # 端口
proxy = (ip + ':' + port).strip() # 组成成proxy代理
if proxy:
yield proxy
except:
print('Crawling faild', start_url)
这里封装了多个网站的代理抓取,元类起的作用是根据这个类创建的对象,都具有了自定义new方法里面的属性,我们这里定义的是检查自身所定义的方法以及数量这个属性,后面要添加什么网站的代理抓取,直接添加进去就好了,不需要做任何改动,上两张结果图,代理不足的时候就会自动去抓取,也会定时测试可用代理,这就实现了动态代理池的功能
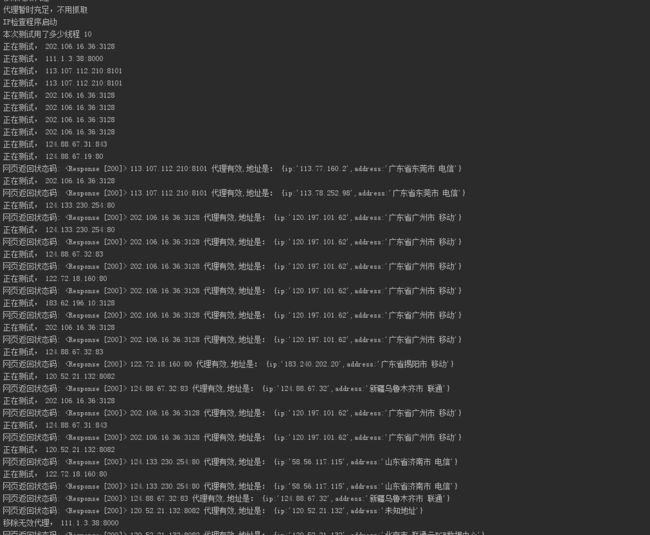
Paste_Image.png
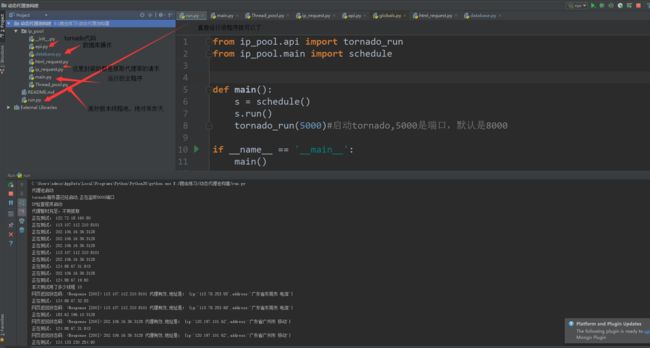
Paste_Image.png
我们在浏览器打开,一个显示的是当前代理可用的数量,一个是提取的代理,每次是提取一个
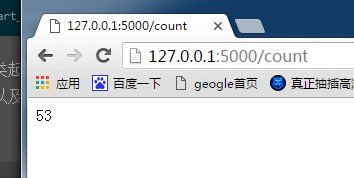
Paste_Image.png
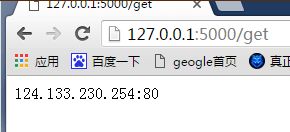
Paste_Image.png