- 深入浅出 SQLSugar:快速掌握高效 .NET ORM 框架
m0_74823595
.net
SQLSugar是一个高效、易用的.NETORM框架,支持多种数据库(如SQLServer、MySQL、PostgreSQL等)。它提供了丰富的功能,包括CRUD操作、事务管理、动态表名、多表联查等,开发者可以通过简单的链式操作实现复杂的数据库逻辑。本文将以完整的示例,详细介绍SQLSugar的安装、配置和功能使用,适用于.NETFramework和.NETCore项目。一、SQLSugar简介1
- 足球俱乐部管理系统(11293)
codercode2022
springbootspringcloud后端hibernate架构laravelactionscript
有需要的同学,源代码和配套文档领取,加文章最下方的名片哦一、项目演示项目演示视频二、资料介绍完整源代码(前后端源代码+SQL脚本)配套文档(LW+PPT+开题报告)远程调试控屏包运行三、技术介绍Java语言SSM框架SpringBoot框架Vue框架JSP页面Mysql数据库IDEA/Eclipse开发
- 【python自动化运维】python第三方运维模块应用
leo__programmer
python自动化运维运维python自动化
一、pymysql模块——数据库编程1、介绍第三方模块作用:连接MySQL数据库1.1、操作流程创建数据库连接基于连接创建游标cursor数据库读写操作关闭游标关闭数据库连接2、pymysql模块的使用2.1、准备工作准备MySQL数据库安装pymysql模块pipinstallpymysql安装配置MySQL数据库[root@localhost~]#yuminstall-ymariadb-ser
- GaussDB数据库SQL系列-LOCK TABLE
关沵什么柿
数据库gaussdbsql
一、前言GaussDB是一款高性能、高可用的分布式数据库,广泛应用于各类行业和场景。在GaussDB中,锁是实现并发控制的关键机制之一,用于协调多个事务之间的数据访问,确保数据的一致性和完整性。本文将围绕GaussDB数据库的LOCKTABLE做一简单介绍。二、GaussDB数据库的锁GaussDB提供了多种锁模式用于控制对表中数据的并发访问。这些模式可以用在MVCC(多版本并发控制)无法给出期望
- postgrel执行VACUUM报VACUUM cannot run inside a transaction block
dianzufa9403
数据库golangjava
在python脚本里执行:1sql_gp1="VACUUMdwd_access_record_inout_temp"2sql_gp2="deletefromdwd_access_record_inout_temptwheret.indate>(selectnow()::timestamp-interval'36hour')"3conn=gputil.connect(logger,target_ho
- MySQL面试题 2024 金九银十 最新 C# 高级 资深 DB 八股文
云草桑
.net面试sql数据库mysqlsqlnetc#
最新mysql八股文chatgpt都能回答的问题,就没必要螺丝是往那边扭了。目录一、数据库知识(通用)篇1.说说drop、truncate、delete区别2.说说主键、外键、超键、候选键3.varchar和char的使用场景?4.什么叫视图?游标是什么?5.说说like%和-的区别6.为什么用自增列作为主键?7.说说非关系型数据库和关系型数据库区别,优势比较?8.说说存储过程的优缺点?9.什么是
- 基于JAVA水果商城设计计算机毕业设计源码+数据库+lw文档+系统+部署
柳下网络
java开发语言jvm
基于JAVA水果商城设计计算机毕业设计源码+数据库+lw文档+系统+部署基于JAVA水果商城设计计算机毕业设计源码+数据库+lw文档+系统+部署本源码技术栈:项目架构:B/S架构开发语言:Java语言开发软件:ideaeclipse前端技术:Layui、HTML、CSS、JS、JQuery等技术后端技术:JAVA运行环境:Win10、JDK1.8数据库:MySQL5.7/8.0源码地址:https
- MySQL 基础篇
睫毛进眼睛了!
SQLmysql
文章目录MySQL基础篇1.数据库概述1.1.表、记录、字段1.2.表的关联关系1.2.1.一对一关联(one-to-one)1.2.2.一对多关联(ont-to-many)1.2.3.多对多关联(mant-to-many)2.SQL之SELECT2.1.基本规则2.2.基本语法2.3.运算符2.3.1.算术运算符2.3.2.比较运算符2.3.3.逻辑运算符2.3.4.位运算符2.3.5.运算符优
- Windchill配置-数据库相关的基础操作
这城有海
系统配置Windchill二开数据库
数据库相关的基础操作一、数据库访问1.1访问方式1.2数据库服务器1.2.1Windows/Linux1.2.2监听相关命令1.2.3进入sqlplus的方式1.2.4基础SQL命令二、常用的SQL语句2.1数据库表空间使用情况查询2.1.1统计2.1.2明细2.2数据库表空间扩容2.2.1单机环境2.2.2集群环境(OracleRAC)2.3游标查询2.3.1查询最大游标数和最大打开游标数2.3
- MySql场景面试题:满意度调查分组去除最高最低求平均分
码到三十五
mysql高手mysqlspringbootspringcloud分布式数据分析数据挖掘
❃博主首页:「码到三十五」,同名公众号:「码到三十五」,wx号:「liwu0213」☠博主专栏:♝博主的话:搬的每块砖,皆为峰峦之基;公众号搜索「码到三十五」关注这个爱发技术干货的coder,一起筑基场景描述我们有一个员工满意度调查系统,数据库中有一张表:survey_scores表:存储员工对公司的满意度打分。表结构如下:--调查打分表CREATETABLEsurvey_scores(score
- Mybatis源码-加载映射文件与动态代理
大家好,我是半夏之沫一名金融科技领域的JAVA系统研发我希望将自己工作和学习中的经验以最朴实,最严谨的方式分享给大家,共同进步写作不易,期待大家的关注和点赞关注微信公众号【技术探界】前言本篇文章将分析Mybatis在配置文件加载的过程中,如何解析映射文件中的SQL语句以及每条SQL语句如何与映射接口的方法进行关联。在看该部分源码之前,需要具备JDK动态代理的相关知识,如果该部分不是很了解,可以先看
- MySQL面试题
泰山小张只吃荷园
mysql数据库java面试后端
MySQL目录1.MySQL中的数据排序是怎么实现的?2.那怎么去优化ORDERBY呢?3.MySQL中的ChangeBuffer是什么?有什么作用?4.详细描述一下一条SQL语句在MySQL中的执行过程5.MySQL的存储引擎有哪些?6.MySQL的索引有哪些?7.MySQLInnoDB引擎中的聚集索引和非聚集索引有什么区别?8.MySQL索引的最左前缀匹配原则是什么?9.MySQL的覆盖索引是
- mybatis xml sql
媤纹琴獣
mybatisxmlsql
1.mybatis根据某一个字段根据以及集合中的列表进行模糊匹配mapperListselectByLinkList(@Param("userId")StringuserId,@Param("messageName")StringmessageName,@Param("anJinGoodsNameList")ListanJinGoodsNameList,@Param("sjDate")Datesj
- TimeUnit源码走读及基本使用
amcomputer
Java基础后端JavaWebTimeUnit源码走读TimeUnit基本使用
1背景介绍笔者遇到一个场景,用户输入的时间和数据库里面时间做对比,由于数据库里面是timestamp类型,(如2021-08-2308:28:41),而用户输入一般为小时,分钟,或者毫秒。代码规约规定不能使用java.sql.Time,java.sql.Date,和java.sql.timestamp,因为在jdk8中,这3个类有缺陷。现在假设用户输入是毫秒(longstartTime=Syste
- 四大.NET ORM框架深度对比:EF Core、SqlSugar、FreeSql与Dapper的性能、功能与适用场景
m0_74823983
.net
在对比EntityFrameworkCore(EFCore)、SqlSugar、FreeSql和Dapper这四种常用的.NETORM框架时,我们可以从多个维度进行详细的梳理和总结。以下是对这些框架的对比,包括应用场景、优势、劣势,并尝试通过表格形式展示关键数据(尽管ORM框架的对比通常难以直接量化到具体的数据点,但我会尽量通过描述性信息来呈现)。ORM框架对比总结框架名称应用场景优势劣势EFCo
- 一文搞定postgreSQL
m0_74823595
postgresql数据库
一文搞定postgreSQLPostgreSQL全面指南一、什么是PostgreSQL?二、PostgreSQL的核心概念三、安装PostgreSQL1.在Linux上安装(例如Ubuntu)2.在macOS上安装(使用Homebrew)3.在Windows上安装四、基本操作1.启动和停止PostgreSQL服务2.连接到PostgreSQL3.创建数据库和用户4.基本SQL操作五、高级功能1.事
- ASP.NET Core Web API 模板项目推荐
余怡桔Solomon
ASP.NETCoreWebAPI模板项目推荐aspnetcore-webapi-templateThisprojectisanWebAPIOpen-SourceBoilerplateTemplatethatincludesASP.NETCore5,WebAPIstandards,cleann-tierarchitecture,GraphQLservice,Redis,Mssql,Mongodat
- MySQL知识大总结(进阶)
神秘的t
mysql数据库
一,数据库的约束1,约束类型1notnull非空约束,标记这个字段不可以为空2unique唯一约束,标记这个字段的值是该列唯一的值,在这一列的其他行,不可以与该字段相等3default默认约束,在该字段没有赋值时,使用默认值填充该列4primarykey主键约束,相当于notnull+unique5foreignkey外键约束,与其他表的主键简历联系,在添加或修改数据是,会根据主外键关系检查数据是
- mysql gtid 主从_基于GTID搭建主从MySQL
呓人61
mysqlgtid主从
基于gtid搭建主从MySQL一、GTID的使用想让主从之间使用gtid的方式同步数据,需要我们在配置文件中开启mysql对gtid相关的配置信息找到my.cnf,在mysqld模块中加入如下的配置。(主库从库都这样)#on表示开启,OFF表示关闭gtid-mode=ON#下面的两个变量必须开启,否则MySQL拒绝启动#通常情况,从服务器从主服务器接收到的更新不记入它的二进制日志。该选项告诉从服务
- mysql开启gtid主从切换_Mysql 基于GTID的主从复制及切换
蕲艾唉啊
mysql开启gtid主从切换
参考http://imysql.com/tag/gtidhttp://mysqllover.com/?p=594Mysql基于GTID的主从复制及切换一、主从复制配置两个mysql服务的my.cnf中相关内容配置[mysqld]#从复制数据库表设置replicate-wild-ignore-table=mysql.%,information_schema.%,innodb.%,innodb_log
- 深入解析:Postgres 和 MySQL 的核心差异与选择建议
zhu hong yu
mysql数据库postgresql
几十年来,关系数据库为无数应用程序提供了支持,它们仍然是许多现代系统的支柱。说到可用于生产的选项,有两种最为广泛使用的数据库,即PostgreSQL和MySQL。两者都提供了可靠的性能、可靠性和社区支持,但它们在处理数据的方式、功能集和配置难易程度方面存在明显差异。了解这些细微差别可以帮助您根据特定需求选择合适的数据库。何时应该使用PostgreSQL或MySQL?下表概括了一些最大的差异:标准P
- MySQL 很重要的库 - 信息字典
shenghuiping2001
网络安全mysqladbandroidinformation
在做owaspSQL注入的时候,有个很重要的库,那就是信息库:这个库就是:information_schema;(准确的说,数据字典)mysql>showdatabases;+--------------------+|Database|+--------------------+|information_schema|下面区这个库里面看看table:mysql>select*fromTABLES
- MySQL基于gtid主从复制(一主一从、一主多从、双主一从)
晶核高手
mysqlmysql数据库
MySQL基于gtid主从复制(一主一从、一主多从、双主一从)MySQL基于gtid主从复制什么是GTID?全局唯一,一个事务对应一个GTID替代传统的binlog+pos复制;使用master_auto_position=1自动匹配GTID断点进行复制MySQL5.6开始支持在传统的主从复制中,slave端不用开启binlog;但是在GTID主从复制中,必须开启binlogslave端在接受ma
- centos下安裝python
白小白的小白
pythonpythoncentos
更新系统文件yumupdateyuminstallzlib-develbzip2-developenssl-develncurses-develsqlite-develreadline-develtk-devellibffi-develgccmake下载安装包并解压wgethttps://www.python.org/ftp/python/3.7.6/Python-3.7.6.tar.xztar-
- 中型项目下的 MySQL 挑战与应对
计算机毕设定制辅导-无忧学长
#MySQLmysql数据库
中型项目里MySQL面临的挑战数据量增长挑战在中型项目的发展进程中,业务不断拓展,数据量往往会呈现出持续增长的态势,这就给MySQL带来了不小的挑战。要知道,MySQL单表虽然理论上可以存储10亿级的数据,但当数据量达到亿级时,其性能,比如查询速度等方面,就会面临严峻的考验,处理效率会大打折扣,进而影响整个系统的运行效率。例如,在某些项目实例(一主一从)中,曾出现过告警情况,每天凌晨会报SLA报警
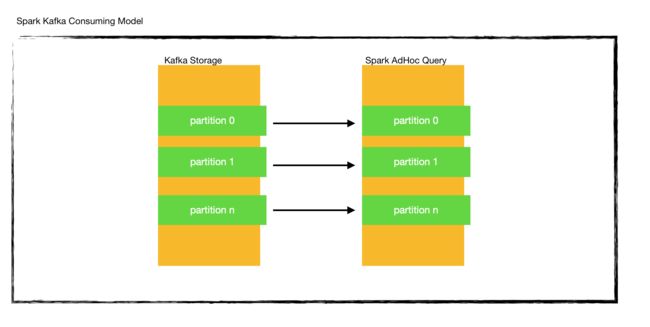
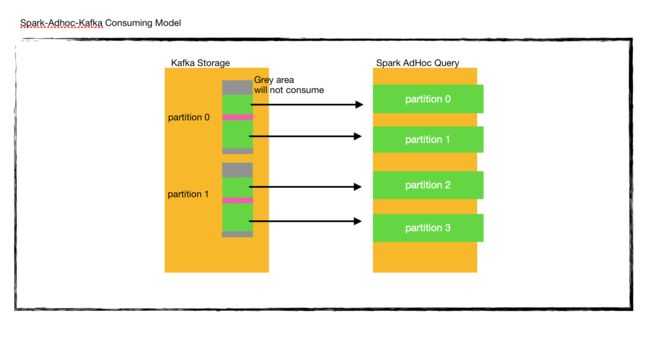
- kafka 学习笔记3-传统部署Kraft模式集群——筑梦之路
筑梦之路
kafka学习笔记
部署kafka集群规划一般模式下,元数据在zookeeper中,运行时动态选举controller,由controller进行Kafka集群管理。kraft模式架构下,不再依赖zookeeper集群,而是用三台controller节点代替zookeeper,元数据保存在controller中,由controller直接进行Kafka集群管理。ip主机名角色nodeid192.168.100.131
- MySQL备份还原(多种不同的方式备份还原)
obboda
数据库
一、mysqldump+binlog实现完全+增量备份1)素材准备:mysql>createdatabaseschool;QueryOK,1rowaffected(0.01sec)mysql>useschoolDatabasechangedmysql>CREATETABLE`Student`(->`Sno`int(10)NOTNULLCOMMENT'学号',`Sname`varchar(16)NO
- Spring @Transactional注解失效场景重现
轻尘×
SpringJava基础MysQL后端mysqljavaspring
环境jdk1.8+springboot2.1.0.RELEASE+mysql8innerDB存储引擎正常在数据插入一条数据抛出checked异常@TransactionalpublicApiResultupdateUser(@RequestBodyUserParamsuser)throwsException{SysUsersysUser=newSysUser();sysUser.setUserNa
- PostgreSQL - pgvector 插件构建向量数据库并进行相似度查询
花千树-010
RAG数据库postgresqlAI编程
在现代的机器学习和人工智能应用中,向量相似度检索是一个非常重要的技术,尤其是在文本、图像或其他类型的嵌入向量的操作中。本文将介绍如何在PostgreSQL中安装pgvector插件,用于存储和检索向量数据,并展示如何通过Python脚本向数据库插入向量并执行相似度查询。一、安装PostgreSQL并配置pgvector插件1.安装PostgreSQL首先,确保你已经安装了PostgreSQL。可以
- 厦门租房信息分析展示(pycharm+python爬虫+pyspark+pyecharts)(踩坑记录)
吃西红柿的鸡蛋
大数据hadoopsparkpython
厦门租房信息分析展示(pycharm+python爬虫+pyspark+pyecharts)(踩坑记录)项目地址http://dblab.xmu.edu.cn/blog/2307/踩坑:Spark分析文件rent_analyse.py改变Spark读取csv文件的写法sparkContext=SparkContext("local","rent_analyse")sqlContext=SQLCon
- 关于旗正规则引擎中的MD5加密问题
何必如此
jspMD5规则加密
一般情况下,为了防止个人隐私的泄露,我们都会对用户登录密码进行加密,使数据库相应字段保存的是加密后的字符串,而非原始密码。
在旗正规则引擎中,通过外部调用,可以实现MD5的加密,具体步骤如下:
1.在对象库中选择外部调用,选择“com.flagleader.util.MD5”,在子选项中选择“com.flagleader.util.MD5.getMD5ofStr({arg1})”;
2.在规
- 【Spark101】Scala Promise/Future在Spark中的应用
bit1129
Promise
Promise和Future是Scala用于异步调用并实现结果汇集的并发原语,Scala的Future同JUC里面的Future接口含义相同,Promise理解起来就有些绕。等有时间了再仔细的研究下Promise和Future的语义以及应用场景,具体参见Scala在线文档:http://docs.scala-lang.org/sips/completed/futures-promises.html
- spark sql 访问hive数据的配置详解
daizj
spark sqlhivethriftserver
spark sql 能够通过thriftserver 访问hive数据,默认spark编译的版本是不支持访问hive,因为hive依赖比较多,因此打的包中不包含hive和thriftserver,因此需要自己下载源码进行编译,将hive,thriftserver打包进去才能够访问,详细配置步骤如下:
1、下载源码
2、下载Maven,并配置
此配置简单,就略过
- HTTP 协议通信
周凡杨
javahttpclienthttp通信
一:简介
HTTPCLIENT,通过JAVA基于HTTP协议进行点与点间的通信!
二: 代码举例
测试类:
import java
- java unix时间戳转换
g21121
java
把java时间戳转换成unix时间戳:
Timestamp appointTime=Timestamp.valueOf(new SimpleDateFormat("yyyy-MM-dd HH:mm:ss").format(new Date()))
SimpleDateFormat df = new SimpleDateFormat("yyyy-MM-dd hh:m
- web报表工具FineReport常用函数的用法总结(报表函数)
老A不折腾
web报表finereport总结
说明:本次总结中,凡是以tableName或viewName作为参数因子的。函数在调用的时候均按照先从私有数据源中查找,然后再从公有数据源中查找的顺序。
CLASS
CLASS(object):返回object对象的所属的类。
CNMONEY
CNMONEY(number,unit)返回人民币大写。
number:需要转换的数值型的数。
unit:单位,
- java jni调用c++ 代码 报错
墙头上一根草
javaC++jni
#
# A fatal error has been detected by the Java Runtime Environment:
#
# EXCEPTION_ACCESS_VIOLATION (0xc0000005) at pc=0x00000000777c3290, pid=5632, tid=6656
#
# JRE version: Java(TM) SE Ru
- Spring中事件处理de小技巧
aijuans
springSpring 教程Spring 实例Spring 入门Spring3
Spring 中提供一些Aware相关de接口,BeanFactoryAware、 ApplicationContextAware、ResourceLoaderAware、ServletContextAware等等,其中最常用到de匙ApplicationContextAware.实现ApplicationContextAwaredeBean,在Bean被初始后,将会被注入 Applicati
- linux shell ls脚本样例
annan211
linuxlinux ls源码linux 源码
#! /bin/sh -
#查找输入文件的路径
#在查找路径下寻找一个或多个原始文件或文件模式
# 查找路径由特定的环境变量所定义
#标准输出所产生的结果 通常是查找路径下找到的每个文件的第一个实体的完整路径
# 或是filename :not found 的标准错误输出。
#如果文件没有找到 则退出码为0
#否则 即为找不到的文件个数
#语法 pathfind [--
- List,Set,Map遍历方式 (收集的资源,值得看一下)
百合不是茶
listsetMap遍历方式
List特点:元素有放入顺序,元素可重复
Map特点:元素按键值对存储,无放入顺序
Set特点:元素无放入顺序,元素不可重复(注意:元素虽然无放入顺序,但是元素在set中的位置是有该元素的HashCode决定的,其位置其实是固定的)
List接口有三个实现类:LinkedList,ArrayList,Vector
LinkedList:底层基于链表实现,链表内存是散乱的,每一个元素存储本身
- 解决SimpleDateFormat的线程不安全问题的方法
bijian1013
javathread线程安全
在Java项目中,我们通常会自己写一个DateUtil类,处理日期和字符串的转换,如下所示:
public class DateUtil01 {
private SimpleDateFormat dateformat = new SimpleDateFormat("yyyy-MM-dd HH:mm:ss");
public void format(Date d
- http请求测试实例(采用fastjson解析)
bijian1013
http测试
在实际开发中,我们经常会去做http请求的开发,下面则是如何请求的单元测试小实例,仅供参考。
import java.util.HashMap;
import java.util.Map;
import org.apache.commons.httpclient.HttpClient;
import
- 【RPC框架Hessian三】Hessian 异常处理
bit1129
hessian
RPC异常处理概述
RPC异常处理指是,当客户端调用远端的服务,如果服务执行过程中发生异常,这个异常能否序列到客户端?
如果服务在执行过程中可能发生异常,那么在服务接口的声明中,就该声明该接口可能抛出的异常。
在Hessian中,服务器端发生异常,可以将异常信息从服务器端序列化到客户端,因为Exception本身是实现了Serializable的
- 【日志分析】日志分析工具
bit1129
日志分析
1. 网站日志实时分析工具 GoAccess
http://www.vpsee.com/2014/02/a-real-time-web-log-analyzer-goaccess/
2. 通过日志监控并收集 Java 应用程序性能数据(Perf4J)
http://www.ibm.com/developerworks/cn/java/j-lo-logforperf/
3.log.io
和
- nginx优化加强战斗力及遇到的坑解决
ronin47
nginx 优化
先说遇到个坑,第一个是负载问题,这个问题与架构有关,由于我设计架构多了两层,结果导致会话负载只转向一个。解决这样的问题思路有两个:一是改变负载策略,二是更改架构设计。
由于采用动静分离部署,而nginx又设计了静态,结果客户端去读nginx静态,访问量上来,页面加载很慢。解决:二者留其一。最好是保留apache服务器。
来以下优化:
- java-50-输入两棵二叉树A和B,判断树B是不是A的子结构
bylijinnan
java
思路来自:
http://zhedahht.blog.163.com/blog/static/25411174201011445550396/
import ljn.help.*;
public class HasSubtree {
/**Q50.
* 输入两棵二叉树A和B,判断树B是不是A的子结构。
例如,下图中的两棵树A和B,由于A中有一部分子树的结构和B是一
- mongoDB 备份与恢复
开窍的石头
mongDB备份与恢复
Mongodb导出与导入
1: 导入/导出可以操作的是本地的mongodb服务器,也可以是远程的.
所以,都有如下通用选项:
-h host 主机
--port port 端口
-u username 用户名
-p passwd 密码
2: mongoexport 导出json格式的文件
- [网络与通讯]椭圆轨道计算的一些问题
comsci
网络
如果按照中国古代农历的历法,现在应该是某个季节的开始,但是由于农历历法是3000年前的天文观测数据,如果按照现在的天文学记录来进行修正的话,这个季节已经过去一段时间了。。。。。
也就是说,还要再等3000年。才有机会了,太阳系的行星的椭圆轨道受到外来天体的干扰,轨道次序发生了变
- 软件专利如何申请
cuiyadll
软件专利申请
软件技术可以申请软件著作权以保护软件源代码,也可以申请发明专利以保护软件流程中的步骤执行方式。专利保护的是软件解决问题的思想,而软件著作权保护的是软件代码(即软件思想的表达形式)。例如,离线传送文件,那发明专利保护是如何实现离线传送文件。基于相同的软件思想,但实现离线传送的程序代码有千千万万种,每种代码都可以享有各自的软件著作权。申请一个软件发明专利的代理费大概需要5000-8000申请发明专利可
- Android学习笔记
darrenzhu
android
1.启动一个AVD
2.命令行运行adb shell可连接到AVD,这也就是命令行客户端
3.如何启动一个程序
am start -n package name/.activityName
am start -n com.example.helloworld/.MainActivity
启动Android设置工具的命令如下所示:
# am start -
- apache虚拟机配置,本地多域名访问本地网站
dcj3sjt126com
apache
现在假定你有两个目录,一个存在于 /htdocs/a,另一个存在于 /htdocs/b 。
现在你想要在本地测试的时候访问 www.freeman.com 对应的目录是 /xampp/htdocs/freeman ,访问 www.duchengjiu.com 对应的目录是 /htdocs/duchengjiu。
1、首先修改C盘WINDOWS\system32\drivers\etc目录下的
- yii2 restful web服务[速率限制]
dcj3sjt126com
PHPyii2
速率限制
为防止滥用,你应该考虑增加速率限制到您的API。 例如,您可以限制每个用户的API的使用是在10分钟内最多100次的API调用。 如果一个用户同一个时间段内太多的请求被接收, 将返回响应状态代码 429 (这意味着过多的请求)。
要启用速率限制, [[yii\web\User::identityClass|user identity class]] 应该实现 [[yii\filter
- Hadoop2.5.2安装——单机模式
eksliang
hadoophadoop单机部署
转载请出自出处:http://eksliang.iteye.com/blog/2185414 一、概述
Hadoop有三种模式 单机模式、伪分布模式和完全分布模式,这里先简单介绍单机模式 ,默认情况下,Hadoop被配置成一个非分布式模式,独立运行JAVA进程,适合开始做调试工作。
二、下载地址
Hadoop 网址http:
- LoadMoreListView+SwipeRefreshLayout(分页下拉)基本结构
gundumw100
android
一切为了快速迭代
import java.util.ArrayList;
import org.json.JSONObject;
import android.animation.ObjectAnimator;
import android.os.Bundle;
import android.support.v4.widget.SwipeRefreshLayo
- 三道简单的前端HTML/CSS题目
ini
htmlWeb前端css题目
使用CSS为多个网页进行相同风格的布局和外观设置时,为了方便对这些网页进行修改,最好使用( )。http://hovertree.com/shortanswer/bjae/7bd72acca3206862.htm
在HTML中加入<table style=”color:red; font-size:10pt”>,此为( )。http://hovertree.com/s
- overrided方法编译错误
kane_xie
override
问题描述:
在实现类中的某一或某几个Override方法发生编译错误如下:
Name clash: The method put(String) of type XXXServiceImpl has the same erasure as put(String) of type XXXService but does not override it
当去掉@Over
- Java中使用代理IP获取网址内容(防IP被封,做数据爬虫)
mcj8089
免费代理IP代理IP数据爬虫JAVA设置代理IP爬虫封IP
推荐两个代理IP网站:
1. 全网代理IP:http://proxy.goubanjia.com/
2. 敲代码免费IP:http://ip.qiaodm.com/
Java语言有两种方式使用代理IP访问网址并获取内容,
方式一,设置System系统属性
// 设置代理IP
System.getProper
- Nodejs Express 报错之 listen EADDRINUSE
qiaolevip
每天进步一点点学习永无止境nodejs纵观千象
当你启动 nodejs服务报错:
>node app
Express server listening on port 80
events.js:85
throw er; // Unhandled 'error' event
^
Error: listen EADDRINUSE
at exports._errnoException (
- C++中三种new的用法
_荆棘鸟_
C++new
转载自:http://news.ccidnet.com/art/32855/20100713/2114025_1.html
作者: mt
其一是new operator,也叫new表达式;其二是operator new,也叫new操作符。这两个英文名称起的也太绝了,很容易搞混,那就记中文名称吧。new表达式比较常见,也最常用,例如:
string* ps = new string("
- Ruby深入研究笔记1
wudixiaotie
Ruby
module是可以定义private方法的
module MTest
def aaa
puts "aaa"
private_method
end
private
def private_method
puts "this is private_method"
end
end