简介
Timber 是Android大神 Jake Wharton 开发的一套基于Android日志的小型可扩展日志框架,是对于日志功能的封装,有点类似装饰器的思想。
基于这种封装思想,让我们可以在基于 Timber 的基础上,实现统一 api 调用,实现不同日志记录功能。
使用方法
- 在
Application.onCreate()里调用Timber.plant(tree)种植一棵树; - 调用 Timber 的静态方法进行日志记录;
更多详情请查看:Timber
原理
简单来说,Timber 将不同的日志操作以树(Tree)的概念进行表示,种植一棵树(plant)就拥有了一种日志记录功能,种植多棵树就可以同时实现多种功能的日志记录。比如,在Debug调试版本时,我们可以种植(plant)一棵调试树(DebugTree),对所有的日志进行记录;在Release版本时,我们可以种植一棵(ReleaseTree),只对 Error 信息进行记录;又比如我们可以种植一棵文件树(FileTree),在运行时将日志记录到文件中······
源码解析: timber:4.5.1
老方法,从调用方法来查看源码。
-
Timber.plant(tree),先来看下Timber的静态方法:plant
// Both fields guarded by 'FOREST'.
private static final List FOREST = new ArrayList<>();
static volatile Tree[] forestAsArray = TREE_ARRAY_EMPTY;
/** Add a new logging tree. */
public static void plant(Tree tree) {
if (tree == null) {
throw new NullPointerException("tree == null");
}
if (tree == TREE_OF_SOULS) {
throw new IllegalArgumentException("Cannot plant Timber into itself.");
}
synchronized (FOREST) {
FOREST.add(tree);
forestAsArray = FOREST.toArray(new Tree[FOREST.size()]);
}
}
主要就是最后一句代码: forestAsArray = FOREST.toArray(new Tree[FOREST.size()]);,就是将日志树保存到 forestAsArray 数组中(将树种植到森林中)。 同时,采用同步代码块(synchronized)进行日志树存储,所以 Timber.plant 支持多线程环境(支持多线程种植树)。
-
Timber.d("write your log message"),那么我们就来看下Timber.d()源码:
/** Log a debug message with optional format args. */
public static void d(@NonNls String message, Object... args) {
TREE_OF_SOULS.d(message, args);
}
所以,其实就是调用了 TREE_OF_SOULS 相应的方法,那么我们来看下 TREE_OF_SOULS 是什么呢:
/** A {@link Tree} that delegates to all planted trees in the {@linkplain #FOREST forest}. */
private static final Tree TREE_OF_SOULS = new Tree() {
···
···
@Override public void d(Throwable t, String message, Object... args) {
Tree[] forest = forestAsArray;
//noinspection ForLoopReplaceableByForEach
for (int i = 0, count = forest.length; i < count; i++) {
forest[i].d(t, message, args);
}
}
···
···
@Override protected void log(int priority, String tag, String message, Throwable t) {
throw new AssertionError("Missing override for log method.");
}
};
从源码中我们可以看出,TREE_OF_SOULS 就是一棵树(Tree 的实例),这棵树是森林的委托类,全权负责将调用转发到森林中的每棵树中,让所有已种植的树都去实现各自的日记记录功能。
Timber 内部提供了一个调试树(DebugTree),假设我们在Applicaion.onCreate() 里面种植了这棵树(Timber.plant(new DebugTree());),那么,当我们调用 Timber.d("Activity Created") 的时候,就会经由 TREE_OF_SOULS 转发给到森林中(此时森林只有一棵树:DebugTree),那么我们的 DebugTree.d() 就会被调用,在看 DebugTree.d() 源码前,我们先来看下它的父类,也就是实现自定义日志操作功能的很重要的一个类:Tree
首先,看下 Tree 的结构组成:
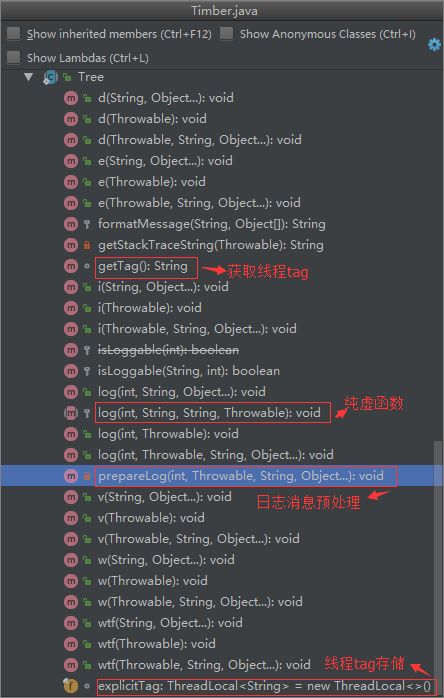
从上图可以看到,
Tree 封装了基本的日志功能函数(
d,i,v,w,e,wtf),接下来我们抽取一些
Tree 源码进行查看:
/** A facade for handling logging calls. Install instances via {@link #plant Timber.plant()}. */
public static abstract class Tree {
final ThreadLocal explicitTag = new ThreadLocal<>();
String getTag() {
String tag = explicitTag.get();
if (tag != null) {
explicitTag.remove();
}
return tag;
}
/** Log a debug exception and a message with optional format args. */
public void d(Throwable t, String message, Object... args) {
prepareLog(Log.DEBUG, t, message, args);
}
/** Return whether a message at {@code priority} or {@code tag} should be logged. */
protected boolean isLoggable(String tag, int priority) {
return isLoggable(priority);
}
private void prepareLog(int priority, Throwable t, String message, Object... args) {
// Consume tag even when message is not loggable so that next message is correctly tagged.
String tag = getTag();
if (!isLoggable(tag, priority)) {
return;
}
if (message != null && message.length() == 0) {
message = null;
}
if (message == null) {
if (t == null) {
return; // Swallow message if it's null and there's no throwable.
}
message = getStackTraceString(t);
} else {
if (args.length > 0) {
message = formatMessage(message, args);
}
if (t != null) {
message += "\n" + getStackTraceString(t);
}
}
log(priority, tag, message, t);
}
/**
* Write a log message to its destination. Called for all level-specific methods by default.
*
* @param priority Log level. See {@link Log} for constants.
* @param tag Explicit or inferred tag. May be {@code null}.
* @param message Formatted log message. May be {@code null}, but then {@code t} will not be.
* @param t Accompanying exceptions. May be {@code null}, but then {@code message} will not be.
*/
protected abstract void log(int priority, String tag, String message, Throwable t);
}
从 Tree 源码中我们可以看出以下几点:
-
Tree.d(),Tree.i(),Tree.v(),Tree.w(),Tree.e(),Tree.wtf()都调用的是prepareLog(),而prepareLog()主要做了以下几件事:
1. 获取线程 tag:getTag()
2. 判断一下是否允许进行日志记录:isLoggable(tag, priority)
3. 对消息和异常消息进行处理组合;
4. 调用log()函数进行真正的日志记录操作(log()是纯虚函数,所以真正的日志记录操作由子类进行确定,所以,Timber 的高扩展性其实就是通过纯虚函数来实现的);
然后,我们终于可以回归到前面的内容,接下来就让我们看下 DebugTree.d() 的源码:

从上图可以看到,
DebugTree 没有复写父类(
Tree)的
d() 函数,所以它调用的就是
Tree.d(),从上文的分析中,我们可以知道,
Tree.d()最终调用的就是
prepareLog,而
prepareLog 主要做的就是4件事,其中,
DebugTree 复写了
getTag() 和
log()函数,那么我们就主要来看下
DebugTree 复写的这两个函数,然后结合我们上面对
Tree 源码的分析,就可以得出
DebugTree 的功能实现具体思路了:
- 首先看下
getTag():
private static final int CALL_STACK_INDEX = 5;
private static final Pattern ANONYMOUS_CLASS = Pattern.compile("(\\$\\d+)+$");
@Override final String getTag() {
String tag = super.getTag();
if (tag != null) {
return tag;
}
// DO NOT switch this to Thread.getCurrentThread().getStackTrace(). The test will pass
// because Robolectric runs them on the JVM but on Android the elements are different.
StackTraceElement[] stackTrace = new Throwable().getStackTrace();
if (stackTrace.length <= CALL_STACK_INDEX) {
throw new IllegalStateException(
"Synthetic stacktrace didn't have enough elements: are you using proguard?");
}
return createStackElementTag(stackTrace[CALL_STACK_INDEX]);
}
/**
* Extract the tag which should be used for the message from the {@code element}. By default
* this will use the class name without any anonymous class suffixes (e.g., {@code Foo$1}
* becomes {@code Foo}).
*
* Note: This will not be called if a {@linkplain #tag(String) manual tag} was specified.
*/
protected String createStackElementTag(StackTraceElement element) {
String tag = element.getClassName();
Matcher m = ANONYMOUS_CLASS.matcher(tag);
if (m.find()) {
tag = m.replaceAll("");
}
tag = tag.substring(tag.lastIndexOf('.') + 1);
return tag.length() > MAX_TAG_LENGTH ? tag.substring(0, MAX_TAG_LENGTH) : tag;
}
从源码可以看出,DebugTree.getTag() 主要做了以下几件事:
- 首先从父类(
Tree.getTag())获取当前线程设置的tag,如果找到,就直接返回;如果找不到,那么,就获取当前线程的函数调用栈(new Throwable().getStackTrace()),获取函数调用栈索引为5的调用栈信息,然后解析该函数调用栈类名信息,得出类名作为tag。
注:这里的调用栈为5的是因为我们开始调用Timber.d()到DebugTree.getTag()函数时,总共经历了6个函数,举例说明如下:
假设我们是在DemoActivity.onCreate()中输出日志:Timber.d("Activity Created");,那么,它的调用栈如下图所示:
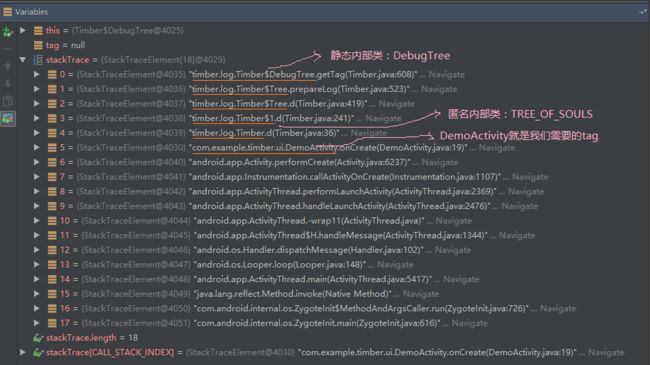
从上面的函数调用栈中可以看出,我们在一个类中,经由
Timber.d() 调用到
DebugTree.getTag() 时,总共经历了6个调用栈/函数,所以调用栈索引为5(也就是第6个)就是我们调用
Timber.d() 的类。
如果还有不清楚的地方,可以参考文章: JakeWharton的timber自动生成Tag原理
- 获取到调用栈类信息后,就调用函数
createStackElementTag()进行类名获取,对于匿名内部类(形如Foo$1),只会取其外部类类名作为tag:Foo。
注:createStackElementTag()函数主要做如下几件事:
1. 使用正则表达式对匿名内部类进行获取,获取得到就将后缀($1)删除,只保留前缀内容;
2. 获取类名;
3. 类名长度最大只取23个字符;
DebugTree.getTag()到这里就分析完了。
- 接下来看下
DebugTree.log()函数源码:
private static final int MAX_LOG_LENGTH = 4000;
/**
* Break up {@code message} into maximum-length chunks (if needed) and send to either
* {@link Log#println(int, String, String) Log.println()} or
* {@link Log#wtf(String, String) Log.wtf()} for logging.
*
* {@inheritDoc}
*/
@Override protected void log(int priority, String tag, String message, Throwable t) {
if (message.length() < MAX_LOG_LENGTH) {
if (priority == Log.ASSERT) {
Log.wtf(tag, message);
} else {
Log.println(priority, tag, message);
}
return;
}
// Split by line, then ensure each line can fit into Log's maximum length.
for (int i = 0, length = message.length(); i < length; i++) {
int newline = message.indexOf('\n', i);
newline = newline != -1 ? newline : length;
do {
int end = Math.min(newline, i + MAX_LOG_LENGTH);
String part = message.substring(i, end);
if (priority == Log.ASSERT) {
Log.wtf(tag, part);
} else {
Log.println(priority, tag, part);
}
i = end;
} while (i < newline);
}
}
从源码可以看出,log() 函数主要做了以下几件事:
- 如果
message的长度小于4000个字符,那么就根据priority标识,输出相应日志到Log(所以DebugTree底层就是调用Android原生系统的Log进行日志输出); - 如果
message的长度大于或等于4000个字符,那么就切断输出,具体切断方法如下:
1. 取出一行长度
2. 找不到换行符,证明是最后剩余的数据,则获取其长度;
3. 获取前面获取到的一行数据的长度与4000进行比较,如果小于4000,则根据priority标识,输出相应日志到Log,然后进行下一行的数据长度获取,重复步骤1,2,3; 如果获取的长度大于4000,那么就对这行数据进行分次获取,每次从message相应位置取4000个字符的子串,进行日志输出,一直循环发送直到该行遍历完成,然后才进行下一行的数据长度获取,重复步骤1,2,3;
以上,就是 Timber 源码的全部解析过程。
如有差错,烦请指出,感激不尽 ^-^。