文章原创,最近更新:2018-08-31
1.关于本书
2.关于作者
3.内容简介
4.案例
5.本例完整代码
引言:网上找资料觉得这本书挺通俗易懂的,刚好可以跟《机器学习实战》相关章节结合一起学习。
学习参考链接:
1.面向程序员的数据挖掘指南
1.关于本书
写给程序员的数据挖掘实践指南:豆瓣评分:7.4分
作者: [美] Ron Zacharski
出版社: 人民邮电出版社
原作名: A Programmer's Guide to Data Mining
译者: 王斌
出版年: 2015-10-24

2.关于作者
Ron Zacharski是一名软件开发工程师,曾在威斯康辛大学获美术学士学位,之后还在明尼苏达大学获得了计算机科学博士学位。博士后期间,他在爱丁堡大学研究语言学。正是基于广博的学识,他不仅在新墨西哥州立大学的计算研究实验室工作,期间还接触过自然语言处理相关的项目,而该实验室曾被《连线》杂志评为机器翻译研究领域翘楚。除此之外,他还曾教授计算机科学、语言学、音乐等课程,是一名博学多才的科技达人。
3.内容简介
本书是写给程序员的一本数据挖掘指南,可以帮助读者动手实践数据挖掘、集体智慧并构建推荐系统。全书共8章,介绍了数据挖掘的基本知识和理论、协同过滤、内容过滤及分类、算法评估、朴素贝叶斯、非结构化文本分类以及聚类等内容。本书采用“在实践中学习”的方式,用生动的图示、大量的表格、简明的公式、实用的Python代码示例,阐释数据挖掘的知识和技能。每章还给出了习题和练习,帮助读者巩固所学的知识。
4.案例
假设我们现在要为一个在线音乐网站的用户推荐乐队。用户可以用1至5星来评价一个乐队,其中包含半星(如2.5星)。下表展示了8位用户对8支乐队的评价:
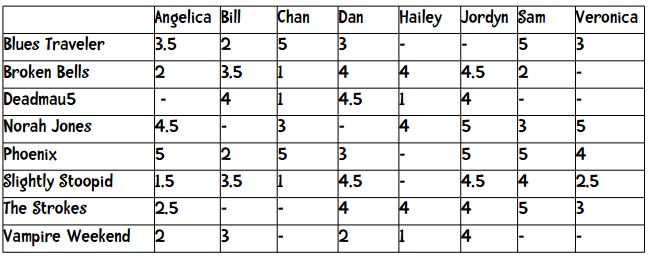
在Python中,我们可以用多种方式来描述上表中的数据,这里选择Python的字典类型(或者称为关联数组、哈希表)。
users = {"Angelica": {"Blues Traveler": 3.5, "Broken Bells": 2.0, "Norah Jones": 4.5, "Phoenix": 5.0, "Slightly Stoopid": 1.5, "The Strokes": 2.5, "Vampire Weekend": 2.0},
"Bill":{"Blues Traveler": 2.0, "Broken Bells": 3.5, "Deadmau5": 4.0, "Phoenix": 2.0, "Slightly Stoopid": 3.5, "Vampire Weekend": 3.0},
"Chan": {"Blues Traveler": 5.0, "Broken Bells": 1.0, "Deadmau5": 1.0, "Norah Jones": 3.0, "Phoenix": 5, "Slightly Stoopid": 1.0},
"Dan": {"Blues Traveler": 3.0, "Broken Bells": 4.0, "Deadmau5": 4.5, "Phoenix": 3.0, "Slightly Stoopid": 4.5, "The Strokes": 4.0, "Vampire Weekend": 2.0},
"Hailey": {"Broken Bells": 4.0, "Deadmau5": 1.0, "Norah Jones": 4.0, "The Strokes": 4.0, "Vampire Weekend": 1.0},
"Jordyn": {"Broken Bells": 4.5, "Deadmau5": 4.0, "Norah Jones": 5.0, "Phoenix": 5.0, "Slightly Stoopid": 4.5, "The Strokes": 4.0, "Vampire Weekend": 4.0},
"Sam": {"Blues Traveler": 5.0, "Broken Bells": 2.0, "Norah Jones": 3.0, "Phoenix": 5.0, "Slightly Stoopid": 4.0, "The Strokes": 5.0},
"Veronica": {"Blues Traveler": 3.0, "Norah Jones": 5.0, "Phoenix": 4.0, "Slightly Stoopid": 2.5, "The Strokes": 3.0}
}
可以用以下方式来获取某个用户的评分:
users["Veronica"]
Out[3]:
{'Blues Traveler': 3.0,
'Norah Jones': 5.0,
'Phoenix': 4.0,
'Slightly Stoopid': 2.5,
'The Strokes': 3.0}
计算曼哈顿距离
曼哈顿距离就是:
如果用数学方法计算Hailey与Veronica的曼哈顿距离,那么结果又是多少呢?
| Veronica | distance | distance | |
|---|---|---|---|
| Blues Traveler | - | 3 | |
| Broken bells | 4 | - | |
| Deadmau | 1 | - | |
| Norah Jones | 4 | 5 | 1 |
| Phoenix | - | 4 | |
| Slightly Stoopid | - | 2.5 | |
| The Strokes | 4 | 3 | 1 |
| Vampire Weekend | 1 | - |
最后距离即是上方数据的加和:(1+ 1)=2。
那么又如何用代码来表示以上的计算过程呢?具体如下:
def manhattan(rating1, rating2):
"""计算曼哈顿距离。rating1和rating2参数中存储的数据格式均为
{'The Strokes': 3.0, 'Slightly Stoopid': 2.5}"""
distance=0
for key in rating1:
if key in rating2:
distance += abs(rating1[key]-rating2[key])
return distance
测试及其结果如下:
>>> manhattan(users['Hailey'], users['Veronica'])
2.0
>>> manhattan(users['Hailey'], users['Jordyn'])
7.5
>>>
下面我们编写一个函数来找出距离最近的用户(其实该函数会返回一个用户列表,按距离排序):
def computeNearestNeighbor(username, users):
"""计算所有用户至username用户的距离,倒序排列并返回结果列表"""
distances=[]
for user in users:
if user !=username:
distance=manhattan(users[user],users[username])
distances.append((distance,user))
distances.sort()
return distances
测试结果及其代码如下:
computeNearestNeighbor("Hailey", users)
Out[21]:
[(2.0, 'Veronica'),
(4.0, 'Chan'),
(4.0, 'Sam'),
(4.5, 'Dan'),
(5.0, 'Angelica'),
(5.5, 'Bill'),
(7.5, 'Jordyn')]
假设我想为Hailey做推荐,这里我找到了离他距离最近的用户Veronica。然后,我会找到出Veronica评价过但Hailey没有评价的乐队,并假设Hailey对这些陌生乐队的评价会和Veronica相近。
比如,Hailey没有评价过Phoenix乐队,而Veronica对这个乐队打出了4分,所以我们认为Hailey也会喜欢这支乐队。下面的函数就实现了这一逻辑:
def recommend(username, users):
"""返回推荐结果列表"""
# 找到距离最近的用户
recommendations = []
nearest= computeNearestNeighbor(username, users)[0][1]
# 找出这位用户评价过、但自己未曾评价的乐队
for artist in users[nearest]:
if artist not in users[username]:
recommendations.append((artist,users[nearest][artist]))
# 按照评分进行排序
return sorted(recommendations,key=lambda recommendations:recommendations[:][1],reverse = True)
可以用它来为Hailey做推荐了:
recommend('Hailey', users)
Out[31]: [('Phoenix', 4.0), ('Blues Traveler', 3.0), ('Slightly Stoopid', 2.5)]
运行结果和我们的预期相符。我们看可以看到,和Hailey距离最近的用户是Veronica,Veronica对Phoenix乐队打了4分。我们再试试其他人:
recommend('Chan', users)
Out[32]: [('The Strokes', 4.0), ('Vampire Weekend', 1.0)]
recommend('Sam', users)
Out[33]: [('Deadmau5', 1.0)]
我们可以猜想Chan会喜欢The Strokes乐队,而Sam不会太欣赏Deadmau5。
作业:实现一个计算闵可夫斯基距离的函数,并在计算用户距离时使用它。
我们可以将曼哈顿距离和欧几里得距离归纳成一个公式,这个公式称为闵可夫斯基距离:
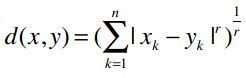
其中:
- r = 1 该公式即曼哈顿距离
- r = 2 该公式即欧几里得距离
- r = ∞ 极大距离
def minkowski(rating1, rating2, r):
distance = 0
for key in rating1:
if key in rating2:
distance += pow(abs(rating1[key] - rating2[key]), r)
return pow(distance, 1.0 / r)
备注:
修改computeNearestNeighbor函数中的一行
distance = minkowski(users[user], users[username], 2)
这里2表示使用欧几里得距离
5.本例完整代码
users = {"Angelica": {"Blues Traveler": 3.5, "Broken Bells": 2.0, "Norah Jones": 4.5, "Phoenix": 5.0, "Slightly Stoopid": 1.5, "The Strokes": 2.5, "Vampire Weekend": 2.0},
"Bill":{"Blues Traveler": 2.0, "Broken Bells": 3.5, "Deadmau5": 4.0, "Phoenix": 2.0, "Slightly Stoopid": 3.5, "Vampire Weekend": 3.0},
"Chan": {"Blues Traveler": 5.0, "Broken Bells": 1.0, "Deadmau5": 1.0, "Norah Jones": 3.0, "Phoenix": 5, "Slightly Stoopid": 1.0},
"Dan": {"Blues Traveler": 3.0, "Broken Bells": 4.0, "Deadmau5": 4.5, "Phoenix": 3.0, "Slightly Stoopid": 4.5, "The Strokes": 4.0, "Vampire Weekend": 2.0},
"Hailey": {"Broken Bells": 4.0, "Deadmau5": 1.0, "Norah Jones": 4.0, "The Strokes": 4.0, "Vampire Weekend": 1.0},
"Jordyn": {"Broken Bells": 4.5, "Deadmau5": 4.0, "Norah Jones": 5.0, "Phoenix": 5.0, "Slightly Stoopid": 4.5, "The Strokes": 4.0, "Vampire Weekend": 4.0},
"Sam": {"Blues Traveler": 5.0, "Broken Bells": 2.0, "Norah Jones": 3.0, "Phoenix": 5.0, "Slightly Stoopid": 4.0, "The Strokes": 5.0},
"Veronica": {"Blues Traveler": 3.0, "Norah Jones": 5.0, "Phoenix": 4.0, "Slightly Stoopid": 2.5, "The Strokes": 3.0}
}
def manhattan(rating1, rating2):
"""计算曼哈顿距离。rating1和rating2参数中存储的数据格式均为
{'The Strokes': 3.0, 'Slightly Stoopid': 2.5}"""
distance=0
for key in rating1:
if key in rating2:
distance += abs(rating1[key]-rating2[key])
return distance
def computeNearestNeighbor(username, users):
"""计算所有用户至username用户的距离,倒序排列并返回结果列表"""
distances=[]
for user in users:
if user !=username:
distance=manhattan(users[user],users[username])
distances.append((distance,user))
distances.sort()
return distances
def recommend(username, users):
"""返回推荐结果列表"""
# 找到距离最近的用户
recommendations = []
nearest= computeNearestNeighbor(username, users)[0][1]
# 找出这位用户评价过、但自己未曾评价的乐队
for artist in users[nearest]:
if artist not in users[username]:
recommendations.append((artist,users[nearest][artist]))
# 按照评分进行排序
return sorted(recommendations,key=lambda recommendations:recommendations[:][1],reverse = True)
def minkowski(rating1, rating2,r):
distance=0
for key in rating1:
if key in rating2:
distance += pow(abs(rating1[key]-rating2[key]),r)
return pow(distance,1.0/r)