深度学习
主要内容:
什么是深度学习
-
卷积神经网络的基本流程
a. 卷积
b. ReLU
c. 池化
d. 全连接 实验:利用CNN进行图像识别
-
实验:利用CNN进行目标检测
a. 滑动窗口
b. 候选生成和分类
c. 全卷积网络(FCN)
d. DetectNet
一 什么是深度学习
深度学习可用来干什么?
深度学习可以用在图像识别,自然语言处理等。
深度学习的发展过程
深度学习的整个发展过程,可以盗用网上的一张图来表示:
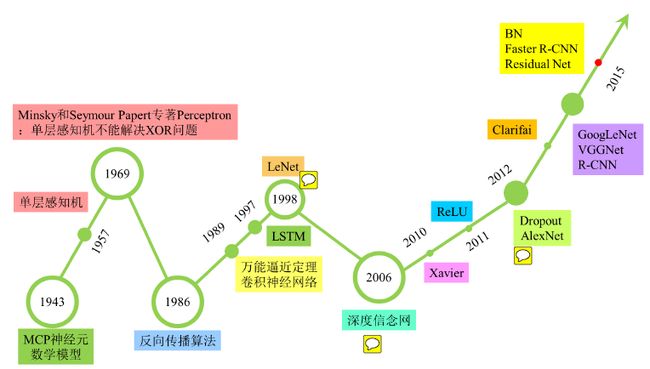
大概的描述下发展过程:
神经网络最早的起源是感知机:感知机拥有一个输入层,输出层和一个隐含层。输入的特征向量通过隐含层传递到输出层得到分类结果。但是感知机有个最大的问题是对复杂的函数不能拟合,只能处理线性分类的问题。
感知机之后,发展出多层感知器。通过多个隐含层和使用sigmoid等连续函数模拟响应,解决了“感知机只能模拟线性分类”的问题。但是随着层数增多,sigmoid带来的“梯度消失”现象越来越明显。
之后发展出ReLU等传输函数代替sigmoid,形成DNN(深度神经网络)的基本形式。但是全连接DNN的结构带来参数数量膨胀的问题。
再之后发展出卷积神经网络(CNN),通过卷积池化等操作来解决了参赛膨胀的问题。
PS : 以上内容均为本人的根据网上内容的理解所写,不一定准确。具体的发展过程,推荐看看知乎上这篇总结和CSDN上的这篇文章,讲的很清楚。
二 卷积神经网络(CNN)
LeNet
LeNet 是推进深度学习领域发展的最早的卷积神经网络之一,以下使用LeNet来讲解CNN的整个过程。
主要流程
LeNet的主要流程为 :
卷积->ReLU->池化->全连接
整个流程如下图所示:
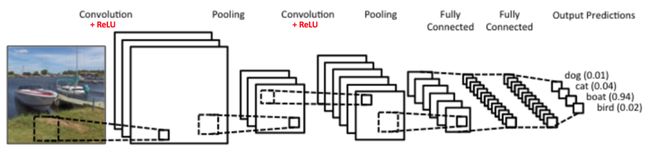
注意:卷积,ReLU,池化都是可以有多层的。
卷积 (滤波)
先说一说卷积层做了什么。我们以一张图片为例。
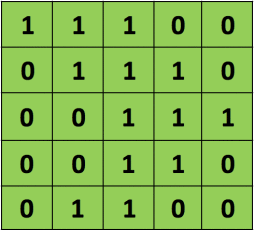
一张5 * 5的黑白图片可以用5 * 5的矩阵来表示,如下图:
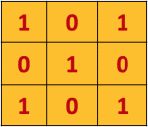
我们有另外一个3 * 3的矩阵(这个3*3的矩阵我们称为卷积核,也叫做滤波器)
通过计算得到一个另外一个3 * 3的图片(我们称之为特征图),计算的过程如下图所示:
[图片上传失败...(image-5fb30b-1517135781556)]
计算过程为:滤波器以一定的步长(该例子中的步长为1),从左至右的滑动。每次得到特征图的一个值,该值为每个位置上对应点的乘积的和。比如该图中滤波器为矩阵((1,0,1),(0,1,0),(1,0,1)),原始图片的第一个矩阵为:((1,1,1),(0,1,1),(0,0,1))。所以得到特征图的第一个值为:(1 * 1 + 0 * 1 + 1 * 1) + (0 * 0 + 1 * 1 + 0 * 1) + (1 * 0 + 0 * 0 + 1 * 1)= 4
为什么要进行卷积呢?因为卷积核在原始图片上滑动时会有重叠的部分,这样新生成的矩阵保留了空间信息。
我们使用一个比较直观的例子来看看卷积层做了什么?
[图片上传失败...(image-4bca76-1517135781556)]
该图中,我们选取不同的滤波器会得到不同的特征图。
第1幅图中,我们选取的Filter对图像进行滤波之后得到的图片和原始的图片是一致的。
第2~4幅图片中,我们得到图片是原始图片中的边界
第5幅图,得到是原始图片的锐化
第6,7幅图,得到的是原始图片的模糊化之后的图片.
[站外图片上传中...(image-e00c9d-1517135781556)]
该图中,非常直观的展示了两个滤波器从原始图片滑动,得到两张不同的特征图。
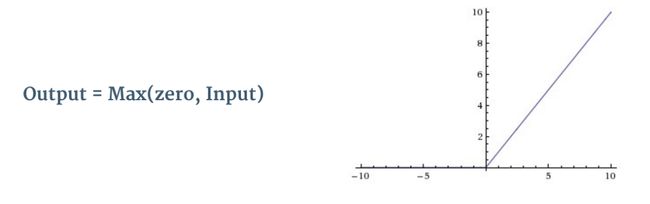
修正线性单元 (Rectified linear unit,ReLU)
由于隐藏层的变换为线性变换,即使有多个隐藏层,最终得到的依然是线性函数,为了拟合复杂的函数,引入非线性操作,我们在每次卷积操作后使用ReLU操作。
ReLU操作如下图所示:
池化 (下采样)
在通过卷积得到特征图之后,理论上,我们就可以通过特征来训练分类模型。但是由于特征的维度太大,导致计算量太大。比如:对于一个 96X96 像素的图像,假设我们已经学习得到了400个定义在8*8输入上的特征,每一个特征和图像卷积都会得到一个 (96 − 8 + 1) * (96 − 8 + 1) = 7921 维的卷积特征,由于有 400 个特征,所以每个样例 (example) 都会得到一个 89 * 89 * 400=3168400 维的卷积特征向量。学习一个拥有超过300W 特征输入的分类器十分不便,并且容易出现过拟合 (over-fitting)。
什么是过度拟合?
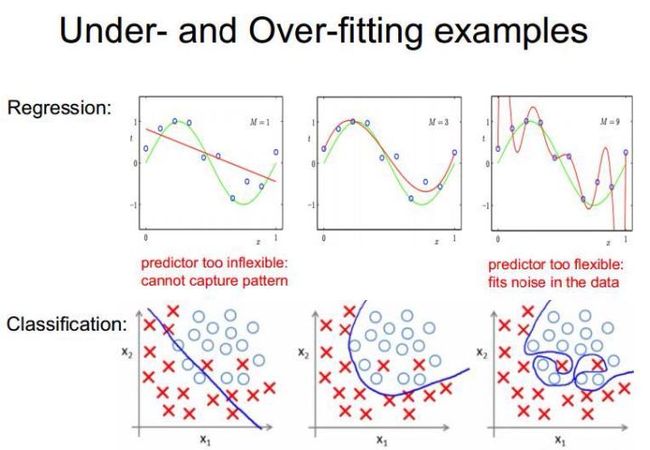
{:width="50%"}
图片来自网络
如上图,第三幅图片表示过度拟合。
所以我们通过池化操作来降低特征的维度。通常是通过对一定区域进行采样,用采用的值代表整个区域。
比如通过最大化的方式进行池化的过程如下图:
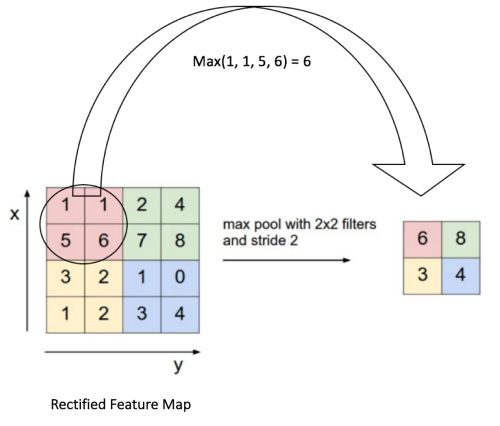
在上图中,特征图为8 * 8的矩阵,我们通过一个2*2的窗口对特征图进行采样,每次选取窗口内最大的值代表整个窗口。这样就将8 * 8的矩阵变为了2 * 2的矩阵。
分类(全连接层)
全连接层就是传统的多层感知器,基于训练数据训练的模型参数,对数据的图像进行分类。
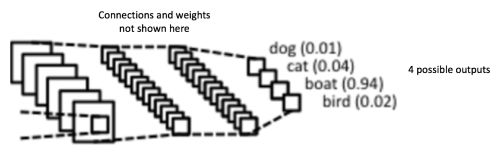
对传统的多层感知器不了解的话,可以看看这篇文章: A Quick Introduction to Neural Networks
三 实验:利用CNN进行图像识别
通过一个图像识别的实验来看看整个过程。ps:实验使用DIGITS(nvidia的开源软件)
训练网络识别手写数字
我们要训练一个深层神经网络识别手写体数字0-9。这个挑战性问题被称为“图像分类”,我们的网络将能够决定哪一个图像属于哪个类或群体。
加载和整理数据
加载第一个数据集
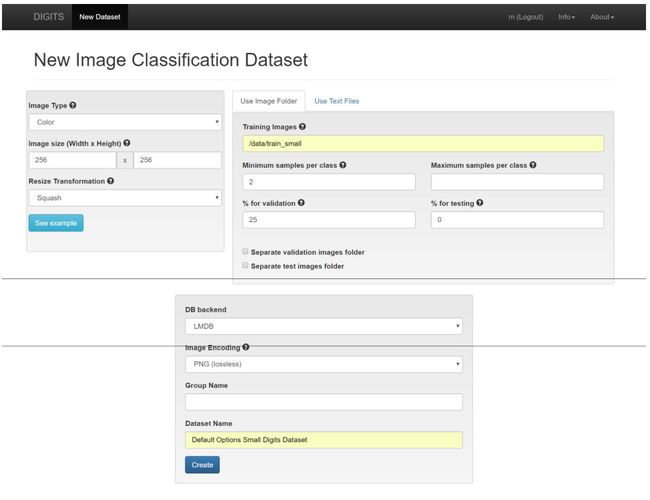
注意以下几点:
- 数据是有标签的。在数据中每个图像配一个标签,告诉计算机,图片所代表的数字,即0-9。我们基本上提供了问题的答案,或者,正如我们的网络将看到的,每个输入都有所期望的输出。这些是我们的网络将从中学习的“示例”。
- 每个图像只不过是白背景上的一个数字。图像分类是一个识别图像中主要物体的任务。对于第一次尝试,我们使用只包含一个对象的图像。在后续的试验中我们将建立应对混乱的数据的能力。
此处所用数据来自 MNIST 创立的MNIST数据集。 其在很大程度上被认为是深入学习领域的“Hello World”或入门。
从数据中学习 - 训练神经网络
接下来, 将使用我们的数据来训练一个人工神经网络。 就像生物的灵感一样,人脑、人工神经网络就是学习机器。和大脑一样,这些“网络”只能够解决有经验的问题,在这种情况下,可以与数据交互。在整个实验中,我们将把“网络”作为未经训练的人工神经网络,把“模型”作为经过训练的网络(通过接触数据)。
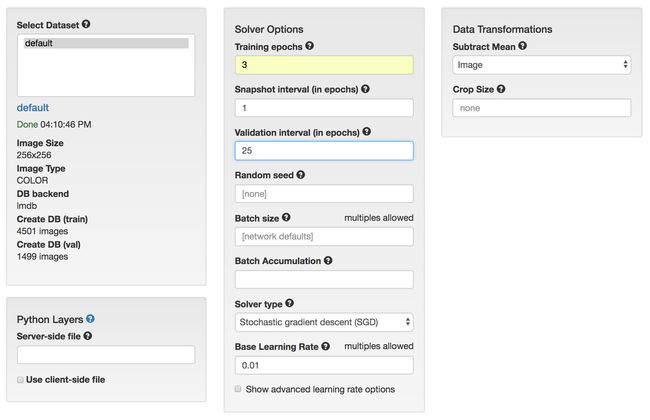
完成后,右边的训练图表应该是类似下图:
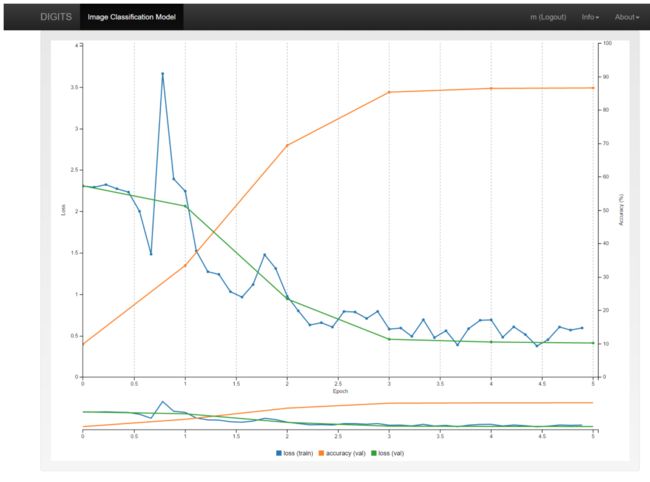
报告包含三个量:训练损失、验证损失和准确性。训练和验证损失的值应该从一个epoch降低到另一个epoch,尽管它们可能会跳来跳去。准确度是模型对验证数据进行正确分类的能力的度量。如果将鼠标悬停在任何数据点上,就会看到其精确值。在这种情况下,最后一个epoch的准确率大约是87%。由于最初的网络是随机生成的,所以结果可能与这里显示的稍有不同。
一个epoch是学习机器所需数据的完整表示。让我们了解一个epoch中发生的事情。
- 神经网络获取第一幅图像(或一小组图像),并预测它是什么(或它们是什么)。
- 将它们的预测与图像的实际标签进行比较。
- 网络使用预测和实际标签之间的差异的信息来自我调整。
- 然后网络使用下一个图像(或一组图像)并做另一个预测。
- 将这个新的(希望更接近的)预测与图像的实际标签进行比较。
- 网络使用这个新预测和实际标签之间的差值的信息来再次调整。
- 经过一轮轮的这种调整,直到网络查看到每一副图像为止。
相比于人使用抽认卡进行学习:
- 一个学生看第一张抽认卡,猜测另一面是什么。
- 他们检查另一侧,看看猜测内容有多接近。
- 他们根据这些新信息来调整自己的理解。
- 然后,学生看着下一张卡片,做出另一个预测。
- 将这个新的(希望更接近的)预测与卡背面的答案进行比较。
- 学生使用这种新的预测值和正确答案之间的差异信息,再次进行调整。
- 经过一轮轮的这种调整,直到学生查看到每一张抽认卡为止。
我们将把这个图作为改进的工具,但是最重要的一点是经过5分钟的训练,我们已经建立了一个模型,它可以将手写数字的图像映射到它们所代表的数字,准确率大约为87%!
四 实验:利用CNN进行目标检测
概述
在本次实验中我们将通过多个实例说明如何使用DIGITS和 Caffe检测航拍图像中的目标。具体使用的是NOAA的露脊鲸识别竞赛(https://www.kaggle.com/c/noaa-right-whale-recognition) 的例子,参赛者被要求在海洋的航空影像中识别到鲸鱼。
图1显示了一个包含母露脊鲸和幼鲸的示例图像:

我们将解决一个稍有不同的问题。不仅仅是要识别鲸鱼的存在,我们还要训练一个卷积神经网络(CNN)来定位鲸鱼在图像中的位置。不论鲸鱼在不在图像里,这类定位问题时常被称为目标检测。在最初的竞赛中,许多成功的参赛选手发现,在试图用裁剪和标准化的图像来识别鲸鱼之前,首先在图像中发现并定位鲸鱼,可以提高他们的得分。
目标检测方法1:滑动窗口
有多种方法可以用卷积神经网络(CNN)来检测和定位图像中的物体。最简单的方法是首先在可以区分目标和非目标实体的图像块上训练CNN分类器。图2显示了一个CNN的架构,其能够从背景图块中区分出鲸鱼的斑块。
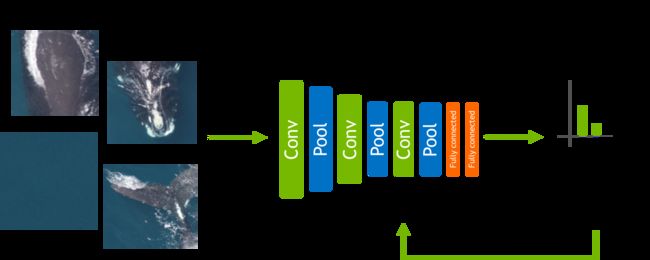
有哪些方法可以提高该模型的分类精度?
事实上,我们使用一个滑动窗口与非重叠的栅格意味着它很可能是我们的一些栅格只能部分包含一个鲸鱼的面部,这会导致错误分类。不幸的是,如果我们增加了重叠的栅格,这个滑动窗口方法的运算时间将急剧增加。我们还需要一个解决方案将重叠分类结合到最终分类“热图”中去-一种流行的方法是非最大抑制(NMS)算法。
正如我们所看到的这种滑动窗口方法的优点是,我们可以训练一个检测器,只使用基于局部块来训练数据(这种方法具有更广泛的使用)。但也有几个缺点:
- 预测速度慢,特别是栅格之间存在较大的重叠,导致大量冗余的计算
- 对于产生一个平衡的训练数据集是一个挑战,非常容易造成误报造成混乱
- 难以达到目标检测的尺度不变性
目标检测方法2:候选生成和分类
我们不采用以滑动窗口的方式实现CNN分类,您可以使用一些更便宜、更灵敏的样式,但容易产生候选检测误报的算法。用于这个流程的算法的例子是级联分类器和选择性搜索。将这些候选检测体传递给CNN按目标类型进行分类或者作为背景噪声过滤掉。
这些候选生成算法,通常会生成比在滑动窗口方法中测试所需要的栅格要少得多的图像块来通过CNN分类。此外,这些候选的检测可以进行批处理后输入CNN,以便从并行运算中得到性能提升。
图3显示了如何在车辆检测场景中使用此方法。

这种方法的优点是:
候选检测体的数目变少,使得测试加速
根据候选生成算法,我们可以获得更精确的目标定位
这种方法的缺点是:
多级处理通道变得更加复杂
需要候选生成构建或训练一个附加模型
较高的误报率
基于候选生成的数量,推理时间是一个变量
目标检测方法3:全卷积网络(FCN)
正如前面提到的,在重叠窗口的滑动窗口法中存在大量冗余计算。幸好有一个巧妙的方法能避免这种冗余。对于像Alexnet这样的卷积分类的末级通常采用全连接层,可以很简单的用卷积层替换。这些替换层具有与前一层的特征映射输出相同的卷积滤波器,滤波器的数目等于它替换的全连接层中的神经元的数目。这种替换的好处是可以将不同大小的图像输入到网络中进行分类。如果输入图像小于网络的期望图像大小(称为网络的感受野),那么我们仍然能够获得这副图像的单一分类。然而,如果图像比感受野大,我们将得到一个热图的分类,非常像我们从滑动窗口获取分类的方法。
让我们来看看Alexnet的fc6 层是如何工作的。 您可以用DIGITS来检查到 fc6输入形状: 使用您在这个实验第一部分训练得到的CNN分类器, 勾选 "Show visualizations and statistics" 来测试任意图像。 您将看到如下图4所示:
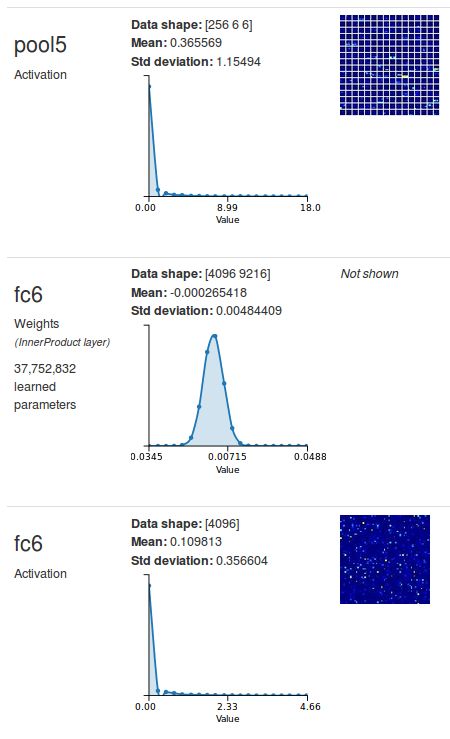
可以看到fc6从pool5接收输入. 在pool5 的激活形状是256 * 6 * 6.
在fc6的激活的形状是4096,这意味着fc6有4096个输出神经元。把fc6转化为一个等效的卷积层,我们将创建一个6×6卷积核的卷积层和4096输出的特征图。
如果没有看明白,可以参考这个blog
目标检测方法4:DetectNet
最后一类目标检测方法是训练一个CNN网络,以便同时对在一副图像中每个位置可能出现的目标进行分类。并通过回归法预测该目标的相应边界框。例如:

这种方法有很大的优点:
只有一次的简单检测、分类和边界框回归反馈通道
非常低的延迟
由于强而大量的背景训练数据,误报率非常低
为了训练这种类型的网络,需要专门的训练数据,所有感兴趣的目标都用精确的边界框标记。这种类型的训练数据比较稀少,成本也很高;然而,如果这种类型的数据可以用于目标检测问题,这几乎是最好的方法。图6显示了用于车辆检测场景的标记训练样本的示例。

最近发布的DIGITS 4增加了这类模型训练的功能,并提供了一个新的 “standard network” -称为 DetectNet - 作为例子。我们将使用 DetectNet在全尺寸海洋航拍图像中训练露脊鲸检测器。
在训练单个CNN作为目标检测和边界框回归中主要面临的挑战是处理不同图像中存在不同数量的目标这一情形,在某些情况下,图像中可能一个目标对象都没有。 DetectNet通过将一副具有一系列边界框的注释的图像转换成一个固定维度的描述。我们直接通过CNN尝试预测。图6显示了在一个单独的分类目标检测问题中,数据是如何映射到这个描述的。
DetectNet实际上是上面所述的FCN,但是需要配置以产生精确的数据描述作为它的输出。DetectNet大部分层是著名的GoogLeNet网络。

参考资料
强烈推荐:
- An Intuitive Explanation of Convolutional Neural Networks
- 池化
- A Quick Introduction to Neural Networks
- NVLABS
- 神经网络技术发展的脉络
- 深度学习的发展历史
- 全卷积网络 FCN 详解