APP出现卡顿不同于一般的BUG,性能问题因为并没有统一的标准,而且与用户的机器环境相关性较大。APP出现卡顿必然会影响用户的使用,所以如何解决APP卡顿问题是开发者必须要直面的问题。下面会从如何发现卡顿、分析卡顿造成的原因及解决卡顿两个方面来介绍。
1.性能检测
在开发阶段,使用内置的性能工具instruments来检测性能问题是最佳的选择。与应用运行性能关联最紧密的两个硬件CPU和GPU,前者用于执行程序指令,针对代码的处理逻辑;后者用于大量计算,针对图像信息的渲染。正常情况下,CPU会周期性的提交要渲染的图像信息给GPU处理,保证视图的更新。一旦其中之一响应不过来,就会表现为卡顿。因此多数情况下用到的工具是检测GPU负载的Core Animation,以及检测CPU处理效率的Time Profiler。
检测的方案根据线程是否相关分为两大类:
- 执行耗时任务会导致CPU短时间无法响应其他任务,检测任务耗时来判断是否可能导致卡顿
- 由于卡顿直接表现为操作无响应,界面动画迟缓,检测主线程是否能响应任务来判断是否卡顿
与主线程相关的检测方案包括:
1.fps
2.ping
3.runloop
与主线程不相关的检测包括:
1.stack backtrace
2.msgSend observe
fps
通常情况下,屏幕会保持60hz/s的刷新速度,每次刷新时会发出一个屏幕刷新信号,CADisplayLink允许我们注册一个与刷新信号同步的回调处理。可以通过屏幕刷新机制来展示fps值:
- (void)startFpsMonitoring {
WeakProxy *proxy = [WeakProxy proxyWithClient: self];
self.fpsDisplay = [CADisplayLink displayLinkWithTarget: proxy selector: @selector(displayFps:)];
[self.fpsDisplay addToRunLoop: [NSRunLoop mainRunLoop] forMode: NSRunLoopCommonModes];
}
- (void)displayFps: (CADisplayLink *)fpsDisplay {
_count++;
CFAbsoluteTime threshold = CFAbsoluteTimeGetCurrent() - _lastUpadateTime;
if (threshold >= 1.0) {
[FPSDisplayer updateFps: (_count / threshold)];
_lastUpadateTime = CFAbsoluteTimeGetCurrent();
}
}
ping
ping是一种常用的网络测试工具,用来测试数据包是否能到达ip地址。在卡顿发生的时候,主线程会出现短时间内无响应这一表现,基于ping的思路从子线程尝试通信主线程来获取主线程的卡顿延时:
@interface PingThread : NSThread
......
@end
@implementation PingThread
- (void)main {
[self pingMainThread];
}
- (void)pingMainThread {
while (!self.cancelled) {
@autoreleasepool {
dispatch_async(dispatch_get_main_queue(), ^{
[_lock unlock];
});
CFAbsoluteTime pingTime = CFAbsoluteTimeGetCurrent();
NSArray *callSymbols = [StackBacktrace backtraceMainThread];
[_lock lock];
if (CFAbsoluteTimeGetCurrent() - pingTime >= _threshold) {
......
}
[NSThread sleepForTimeInterval: _interval];
}
}
}
@end
runloop
作为和主线程相关的最后一个方案,基于runloop的检测和fps的方案非常相似,都需要依赖于主线程的runloop。由于runloop会调起同步屏幕刷新的callback,如果loop的间隔大于16.67ms,fps自然达不到60hz。而在一个loop当中存在多个阶段,可以监控每一个阶段停留了多长时间:
- (void)startRunLoopMonitoring {
CFRunLoopObserverRef observer = CFRunLoopObserverCreateWithHandler(CFAllocatorGetDefault(), kCFRunLoopAllActivities, YES, 0, ^(CFRunLoopObserverRef observer, CFRunLoopActivity activity) {
if (CFAbsoluteTimeGetCurrent() - _lastActivityTime >= _threshold) {
......
_lastActivityTime = CFAbsoluteTimeGetCurrent();
}
});
CFRunLoopAddObserver(CFRunLoopGetMain(), observer, kCFRunLoopCommonModes);
}
stack backtrace
代码质量不够好的方法可能会在一段时间内持续占用CPU的资源,换句话说在一段时间内,调用栈总是停留在执行某个地址指令的状态。由于函数调用会发生入栈行为,如果比对两次调用栈的符号信息,前者是后者的符号子集时,可以认为出现了卡顿恶鬼:
@interface StackBacktrace : NSThread
......
@end
@implementation StackBacktrace
- (void)main {
[self backtraceStack];
}
- (void)backtraceStack {
while (!self.cancelled) {
@autoreleasepool {
NSSet *curSymbols = [NSSet setWithArray: [StackBacktrace backtraceMainThread]];
if ([_saveSymbols isSubsetOfSet: curSymbols]) {
......
}
_saveSymbols = curSymbols;
[NSThread sleepForTimeInterval: _interval];
}
}
}
@end
msgSend observe
OC方法的调用最终转换成msgSend的调用执行,通过在函数前后插入自定义的函数调用,维护一个函数栈结构可以获取每一个OC方法的调用耗时,以此进行性能分析与优化:
#define save() \
__asm volatile ( \
"stp x8, x9, [sp, #-16]!\n" \
"stp x6, x7, [sp, #-16]!\n" \
"stp x4, x5, [sp, #-16]!\n" \
"stp x2, x3, [sp, #-16]!\n" \
"stp x0, x1, [sp, #-16]!\n");
#define resume() \
__asm volatile ( \
"ldp x0, x1, [sp], #16\n" \
"ldp x2, x3, [sp], #16\n" \
"ldp x4, x5, [sp], #16\n" \
"ldp x6, x7, [sp], #16\n" \
"ldp x8, x9, [sp], #16\n" );
#define call(b, value) \
__asm volatile ("stp x8, x9, [sp, #-16]!\n"); \
__asm volatile ("mov x12, %0\n" :: "r"(value)); \
__asm volatile ("ldp x8, x9, [sp], #16\n"); \
__asm volatile (#b " x12\n");
__attribute__((__naked__)) static void hook_Objc_msgSend() {
save()
__asm volatile ("mov x2, lr\n");
__asm volatile ("mov x3, x4\n");
call(blr, &push_msgSend)
resume()
call(blr, orig_objc_msgSend)
save()
call(blr, &pop_msgSend)
__asm volatile ("mov lr, x0\n");
resume()
__asm volatile ("ret\n");
}
除了这些还有很多优秀的检测工具可以使用:
MLeakFinder是微信读书成员zepo在github开源的一款内存泄露检测工具,具体原理和使用方法可以参见这篇文章。在此之前,内存泄露引起的性能问题是很难被察觉的,只有泄露到了相当严重的程度,然后通过Instrument工具,不断尝试才得以定位。MLeakFinder能在开发阶段,把内存泄露问题暴露无遗,减少了很多潜在的性能问题。
2.造成原因及解决办法
1.离屏渲染问题
在tableView or collectionView的Cell使用中如果大量出现了view.layer.cornerRadius + ClipToBoundsormasksToBounds的设置,会造成滚动不流畅,滚动起来十分的卡顿。
下面是个真实的case
某App有一个用UICollectionView制作了书架的功能,可以放置图书,多本图书叠放在一起自动生成文件夹,如图:

可以看到图中每一本书都是一个圆角矩形,而一个文件夹,如果图书超过4本则是4+1个圆角矩形,普通的用户使用习惯,可能不会有太多的文件夹(也说不准哟!)但是如果文件夹数量超过2个屏幕,每一个文件夹都是4本以上的图书,那么在2各屏幕内来回滚动,产生了很恐怖的结果。。。
我们的app,在ip6上,同屏幕最多可以有9个Item,每个Item如果都是4个以上图书的文件夹就是5个圆角矩形,换句话说,一个屏幕内最多有45个圆角矩形。在这样的极限情况下,iPhone6上会卡的只有15帧左右!60帧才是满帧啊亲。。。
更何况我们的app,在iPhone 6 plus上是4*4个item,于是一个屏幕内最多有80个圆角矩形。
我们还支持iPad universal
细思极恐
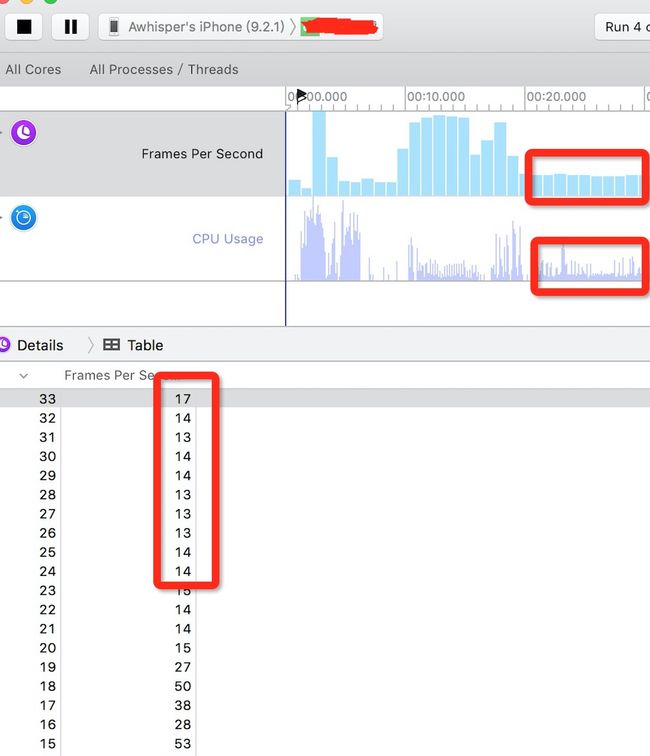
可怕地事情来了,在全是文件夹的情况下,已经达到了单屏45个圆角矩形,帧率已经降到了平均15,这是一种什么感觉,满帧率60,现在只达到了滚动流畅的25%,简直惨不忍睹。
针对上面这个特殊情况,最广泛的办法就是预先用CPU,构建圆角路径贝塞尔曲线UIBezierPath,用原来的图片填充进圆角路径,获得天然的自带圆角透明的bitmap数据UIImage,从而直接交给GPU进行普通渲染。
但是Gpu在处理浮点运算,处理矩阵运算的时候,一定会比Cpu快得,毕竟他天生就是拿来做图形处理的,所以在离屏渲染的数量比较少的时候,我们把运算交给Cpu,反而是略微增加了耗时与卡顿。离屏渲染真正的消耗,在于不同缓冲区的来回切换,一旦圆角的数量增多,计算量加大,这种切换会更加频繁,所以当数量庞大的时候,Gpu最终所有的操作就会更加耗时。
AsyncDisplay(异步绘制)
简单地说,就是已经采用了Cpu离屏渲染,还是会因为主线程计算耗时很长而卡顿UI,那我们就把Cpu计算bitmap这个过程放到线程里去。
运算量大怎么办?
- 优化运算,合并图层,在需求范围内替换贴图
- 开个后台线程慢慢算,算好了再回到主线程绘制
其实 facebook开源的 AsyncDisplayKit 就是实现了这些,功能很强大,这个就需要自己去看了。
关于离屏渲染问题,可以去看看我的另一篇文章。iOS学习日记-离屏渲染
2.线程问题
1.主线程阻塞
这是一个最常出现的问题,当在主线程进行长耗时操作时就会出现明显的卡顿现象。这时的解决办法就是将长耗时操作放到分线程处理,这个就不多赘述了。
2.多线程问题
我在网上看到过一个大神写的关于iOS App 使用 GCD 导致的卡顿问题
的文章,下面是部分类容:
Apple 一直推荐自己创建 serial GCD queue 的时候,一定要控制数量,而且最好设置 target queue,否则会出现问题,但会出现什么问题呢,下面是一位 Apple 内核团队工程师的回复。
* On macOS, where the system is happier to over commit, you end up with a thread explosion. That in turn can lead to problems running out of memory, running out of Mach ports, and so on.
* On iOS, which is not happy about over committing, you find that the latency between a block being queued and it running can skyrocket. This can, in turn, have knock-on effects. For example, the last time I looked at a problem like this I found that `NSOperationQueue` was dispatching blocks to the global queue for internal maintenance tasks, so when one subsystem within the app consumed all the dispatch worker threads other subsystems would just stall horribly.
Note: In the context of dispatch, an “over commit” is where the system had to allocate more threads to a queue then there are CPU cores. In theory this should never be necessary because work you dispatch to a queue should never block waiting for resources. In practice it’s unavoidable because, at a minimum, the work you queue can end up blocking on the VM subsystem.
Despite this, it’s still best to structure your code to avoid the need for over committing, especially when the over commit doesn’t buy you anything. For example, code like this:
group = dispatch_group_create();
for (url in urlsToFetch) {
dispatch_group_enter(group);
dispatch_async(dispatch_get_global_queue(…), ^{
… fetch `url` synchronously …
dispatch_group_leave(group);
});
}
dispatch_group_wait(group, …);
is horrible because it ties up 10 dispatch worker threads for a very long time without any benefit. And while this is an extreme example — from dispatch’s perspective, networking is /really/ slow — there are less extreme examples that are similarly problematic. From dispatch’s perspective, even the disk drive is slow (-:
这段回复很有意思。阅读过 GCD 源码的同学会知道,所有默认创建的 GCD queue 都有一个优先级,但其实每个优先级对应两个 queue,比如一个是 default-priority, 那么另一个就是 default-priority-overcommit。dispatch_async 的时候,会首先将任务丢进 default-priority 队列,如果队列满了,就转而丢进 default-priority-overcommit。
在 Mac 系统里,GCD 允许 overcommit,意味着每次 dispatch_async 都会创建一个新线程,即使 over commit 了,这些过量的线程会根据优先级来竞争 CPU 资源。
而在 iOS 系统里,GCD 会控制 overcommit,如果某个优先级队列 over commit 里,那么排在后面的任务就会处于等待状态。移动设备 CPU 资源比较紧张,这种设计合乎常理。
所以如果在 iOS 里创建过多的 serial queue,那么后面提交的任务可能就会一直处于等待状态。这也是为什么我们需要严格控制 queue 的数量和层级关系,最好是 App 当中每个子系统只能分配固定数量和优先级的 queue,从而避免 thread explosion 导致的代码无法及时执行问题。
iOS 系统本身是一个资源调度和分配系统,CPU,disk IO,VM 等都是稀缺资源,各个资源之间会互相影响,主线程的卡顿看似 CPU 资源出现瓶颈,但也有可能内核忙于调度其他资源,比如当前正在发生大量的磁盘读写,或者大量的内存申请和清理,都会导致一这简单的创建线程的内核调用出现卡顿,所以解决办法只能是自己分析各 thread 的 call stack,根据用户场景分析当前正在消耗的系统资源。后面也确实通过最近提交的代码分析,发现是由于增加了一些非常耗时的磁盘 io 任务(虽然也是放在在子线程),才出现这个看着不怎么沾边的 call stack。revert 之后卡顿警报就消失了。
在使用 GCD 创建 queue,或者说一个 App 内部使用 GCD 执行子线程任务时,最好有一套 App 所有团队都能遵循的队列使用机制,避免创建过多的 thread,而出现意料之外的线程资源紧缺,代码无法及时执行的情况。
3.其他
还有一些就是网上经常看到的解决卡顿方案:
1、尽量用轻量级的对象,比如用不到事件处理的地方,可以考虑使用CALayer取代UIView
2、不要频繁地调用 UIView的相关属性,比如frame、bounds、transform等属性,尽量减少不必要的修改
3、尽量提前计算好布局,在有需要时一次性调整对应的属性,不要多次修改属性
4、Autolayout会比真设置frame消耗更多的CPU资源
5、图片的size最好刚好好UIImageView的size保持一致
6、控制一下线程的最大并发数量
7、尽量把耗时的操作放到子线程
8、文本处理(尺寸计算、绘制)
9、图片处理(解码、绘制)
参考文章:
质量监控-卡顿检测
圆角卡顿刨根问底
iOS App 使用 GCD 导致的卡顿问题