导读:本文分析的是源码,所以至少读者要熟悉他们的接口使用,同时,对于并发,读者至少要知道 CAS、ReentrantLock、UNSAFE操作这几个基本知识,文中不会对这些知识进行介绍。Java8 用到了红黑树,不过本文不会进行展开,感兴趣的读者请自行查找相关资料。
Hash 表
在讲HashMap之前,我们先来了解下他们底层实现的一种数据结构——Hash 表。
Hash表,是根据关键码值(Key value)而直接进行访问的数据结构。也就是说,它通过把关键码值映射到表中一个位置来访问记录,以加快查找的速度。存放记录的数组叫做哈希表。
在HashMap中,就是将所给的“键”通过哈希函数得到“索引”,然后把内容存在数组中,这样就形成了“键”和内容的映射关系。

上图可以发现,“键”转换为“索引”的过程就是哈希函数,为了尽可能保证每一个“键”通过哈希函数的转换对应不同的“索引”,就需要对哈希函数进行选择了,使其得到的“索引”分布越均匀越好。
哈希函数的均匀性:

通过前辈的研究加上实践表明,当把哈希函数得到hashcode值对素数取模时,这样得到的索引是最为均匀的。但是,在HashMap源码中,并不是取模素数的,而是一种等效取模2的n次方的位运算,hash&(length-1)。hash%length==hash&(length-1)的前提是length是2的n次方;之所以使用位运算替代取模,是因为位运算的效率更高,所以也就要求数组的长度必须是2的n次方(索引的分布也是很均匀的)。
哈希函数的一致性:

哈希函数的一致性原则是:当两个对象的equals相等,那么他们的hashcode一定相等。
这就要求我们在重写了equals方法时,必须重写hashcode方法。如果不重写hashcode,则会使用Object的hashcode方法,该方法是以我们创建的对象的地址作为参数求hash的。所以,如果不重写hashcode,两个equals相等的对象会导致hashcode不同(因为不同的对象),这个是不允许的,因为违背了hash函数的一致性原则。
哈希冲突:
当两个不同的元素,通过哈希函数得到了同一个hashcode,则会产生哈希冲突。HashMap的处理方式是,JDK8之前,每一个位置对应一个链表,链式的存放哈希冲突的元素;JDK8开始,当哈希冲突达到一定程度(8个),每一个位置从链表转换成红黑树。因为红黑树的时间复杂度是O(log n)的,效率优于链表。

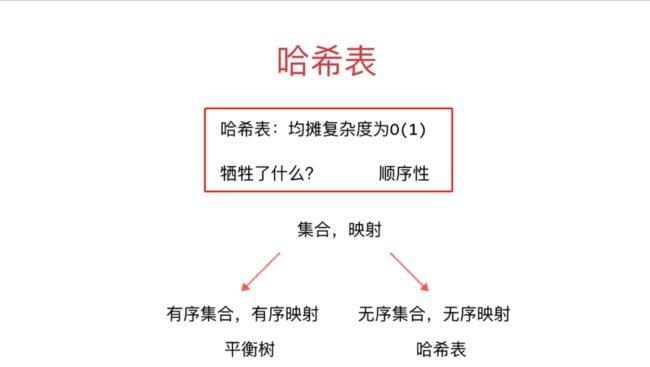
哈希表小结:
哈希表,均摊复杂度是O(1),因为第一步通过数组索引找到数组位置是O(1),然后到链表中查找元素的均摊复杂度是O(size/length),size为元素个数,length为数组长度。由于Hash表的容量是动态扩容的,也就是说随着size和length成正比的,即size/length是一个常数,于是也是O(1)的复杂度,即总的来说,均摊复杂度是O(1)。但是哈希表是没有顺序性的,即无法对元素进行排序。
Java7 HashMap
HashMap 是最简单的,一来我们非常熟悉,二来就是它不支持并发操作,所以源码也非常简单。
首先,我们用下面的这张图来介绍下HashMap的结构。

大方向上,HashMap里面是一个数组,然后每个数组中的每个元素是一个单向链表。
上图中,每个绿色的实体是嵌套类Entry的实例,Entry包含四个属性:key,value,hash值和用于单向链表的next。
capacity:当前数组容量,始终保持2^n,可以扩容,扩容后的大小为当前的2倍,默认为16。
loadFactor:负载因子,默认为 0.75。
threshold:扩容的阈值,等于 capatity * loadFactor。
put 过程分析

1、数组初始化:在第一个元素插入 HashMap 的时候做一次数组的初始化,就是先确定初始的数组大小,并计算数组的扩容阈值。这里将数组保持在 2 的 n 次方的做法,java7 和 java8 的HashMap 和 ConcurrentHashMap 都有相应的要求。
注意:new HashMap时,并未做数组初始化操作,而是简单为loadFactor ,threshold赋值;同时为了保证将数组保持在 2 的 n 次方,会对 capacity的值进行处理,取大于capacity且最近的2 的 n 次方值作为数组大小。
2、计算具体数组的下标:使用 key的 hash值对数组长度进行取模(源码中是 hash & (length -1),当length是2^n 时,此时(length - 1) 的二进制全是1, hash & (length -1) 相当于取 hash值的低 n位, 结果和 hash mod length一样的)。
3、找到数组下标后,先进行 key 判重(== || equals),如果没有重复,则将新值放入链表的表头,如果有重复,直接用新值覆盖旧值。
4、数组扩容:如果当前size >= threshold,那么就会触发扩容;扩容就是用一个新的大数组替换原来的小数组,并将原来数组中的值迁移到新的数组中。
既然对 key的判重依据是hash值和equals方法,故必须对key进行重写hashcode和equals方法,因为如果不重写,将直接用Object的hashcode和equals方法,而其必须是同一个对象才能满足key相同。
hashcode方法的一般规定:如果两个对象能够equals相等,那么他们的hashcode必须相等。
所以,重写了equals必须重写hashcode。
get 过程分析
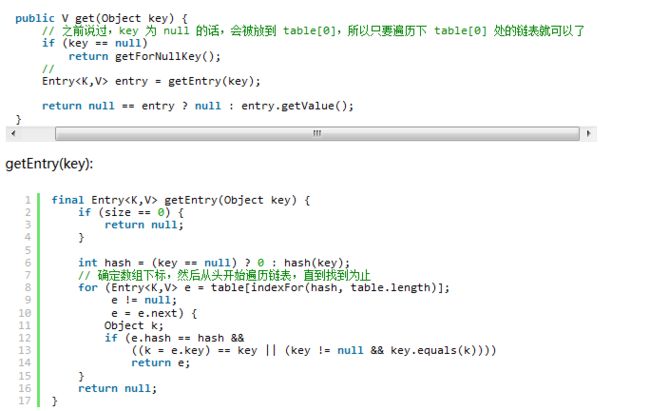
相对于put 过程,get 过程是非常简单的。
1、根据key 计算 hash 值。
2、找到相应的数组下标:hash & (length - 1)。
3、遍历该数组位置处的链表,直到找到相等(== || equals)的 key。
java7 ConcurrentHashMap
ConcurrentHashMap和 HashMap 思路是差不多的,但是因为它支持并发操作,所以要复杂一些。
整个ConcurrentHashMap 由一个个 Segment 组成,Segment 代表“部分” 或 “一段”的意思,所以很多地方都会将其描述为分段锁。
简单的理解,ConcurrentHashMap 是一个 Segment数组,Segment 通过继承 ReentrantLock来进行加锁,所以每次需要加锁的操作锁住的是一个 Segment,这样只要保证每个 Segment是线程安全的,也就实现了全局的线程安全性。

concurrencyLevel:并行级别、并发数、Segment 数。默认是16,也就是说 ConcurrentHashMap 有16个 Segment,所以理论上,最多同时支持16个线程并发写。这个值可以在初始化的时候设置为其他值,但是一旦初始化以后,它就不可以扩容了。
再具体到每个 Segment内部,其实每个 Segment 很像之前介绍的 HashMap,不过它要保证线程安全,所以处理起来要麻烦些。
初始化
initialCapacity:初始容量,这个值指的是整个 ConcurrentHashMap的初始容量,实际操作的时候需要平均分给每个 Segment。
loadFactor:负载因子,之前我们说了,Segment 数组不可以扩容,所以这个负载因子是给每个 Segment 内部使用的。
new ConcurrentHashMap()无参进行初始化以后:
1、Segment 数组长度为16,不可以扩容。
2、Sement[i]的默认大小为2,负载因子为0.75,得出初始阈值为1.5,也就插入第一个元素不会触发扩容,插入第二个进行一次扩容。
3、初始化了 Segment[0],其他位置还是null。
put 过程分析
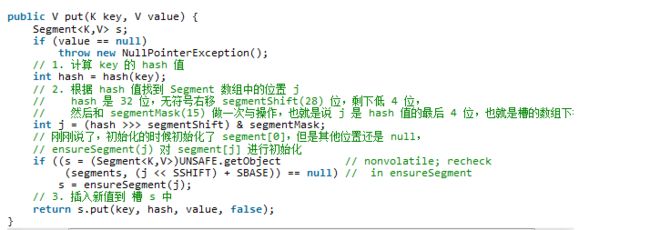
第一层皮很简单,根据 hash值找到 Segment,之后就是 Segment 内部的 put 操作了。
Segment 内部是由 数组+链表 组成的。
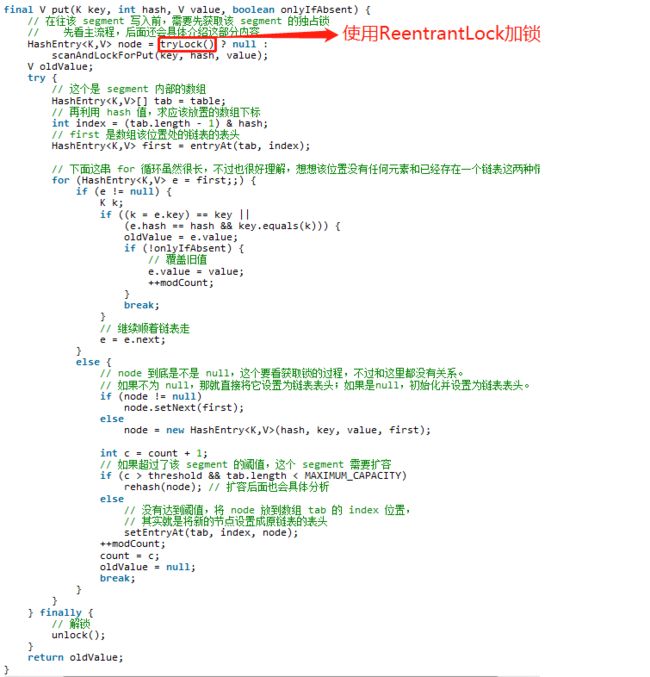
初始化 Segment:ensureSement
ConcurrentHashMap 初始化的时候初始化了第一个分段 Segment[0],对于其他分段来说,在插入第一个值的时候进行初始化。并且初始化其他的 Segment[k]时,需要当前 Segment[0]处的数组长度和负载因子,故 Segment[0]需要在ConcurrentHashMap初始化的时候进行初始化。
扩容:rehash
重复一下,Segment 数组不能扩容,扩容的是 单个Segment内部数组 HashEntry[],扩容后,容量为原来的2倍。
触发扩容的时机:put 的时候,如果判断该值的插入会导致该 Segment内部的元素个数超过阈值,那么先进行扩容,再插值。该方法不需要考虑并发,因为 put 操作,是持有独占锁的。
get 过程分析
相对于 put 来说,get 真的不要太简单。

1、计算 hash值,找到 Segment数组中的下标。
2、再次根据 hash 找到每个 Segment内部的 HashEntry[]数组的下标。
3、遍历该数组位置处的链表,直到找到相等(== || equals)的 key。
get 是不需要加锁的:原因是get方法是将共享变量(table)定义为volatile,让被修饰的变量对多个线程可见(即其中一个线程对变量进行了修改,会同步到主内存,其他线程也能获取到最新值),允许一写多读的操作。
Java8 HashMap
Java8 对 HashMap 进行了一些修改,最大的是不同就是利用了红黑树,所以其由 数组+链表+红黑树 组成。
根据 Java7 HashMap 的介绍,我们知道,查找的时候,根据 hash 值我们能够快速定位到数组的具体下标,但是之后的话,需要顺着链表一个个比较下去才能找到我们需要的,时间复杂度取决于链表的长度,为O(N)。
为了降低这部分的开销,在Java8 中,当链表中的元素超过8个以后,会将链表转换为红黑树,在这些位置进行查找的时候可以降低时间复杂度为O(logN)。

Java7 中使用 Entry来代表每个 HashMap 中的数据节点,Java8 中使用 Node,基本没有区别,都是 key,value,hash和 next 这四个属性,不过, Node 只能用于链表的情况,红黑树需要使用 TreeNode。
put 过程分析

和Java7 稍微有点不一样的是,Java7 是先扩容后插入新值的,Java8 先插入值再扩容的;Java7 (HashMap/ConcurrentHashMap) 是将数据插入到链表的表头,而 Java8 是将数据插入到链表的最后面。
get 过程分析

1、计算 key 的 hash 值,根据 hash 值找到对应数组下标:hash & (length - 1)。
2、判断数组该位置第一个节点是否刚好是我们要找的(判key),如果不是,走第三步。
3、判断该元素类型是否是 TreeNode,如果是,用红黑树的方法取数据,如果不是,走第四步。
4、遍历链表,直到找到相等(== || equals)的 key。
Java8 ConcurrentHashMap
对于 ConcurrentHashMap,Java8 也引入了红黑树。
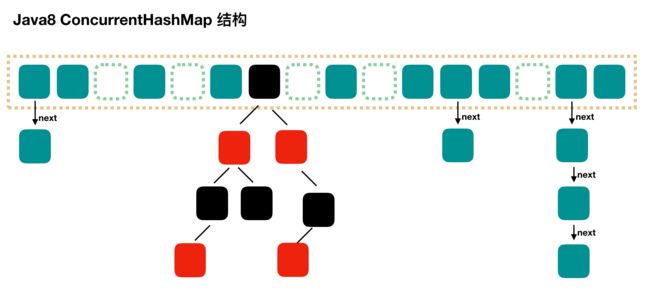
结构上和 Java8 的 HashMap 基本上一样,不过它要保证安全性,所以源码上确实要复杂一些。注意:Java8 的 ConcurrentHashMap不再使用 Segment 分段锁来保证并发写,而是使用 CAS 操作来保证线程安全的。
初始化

这个初始化方法,通过提供初始容量,计算 sizeCtl,sizeCtl = [(1.5 * initialCapacity + 1,然后向上取最近的2的 n 次方)]。
put 过程分析
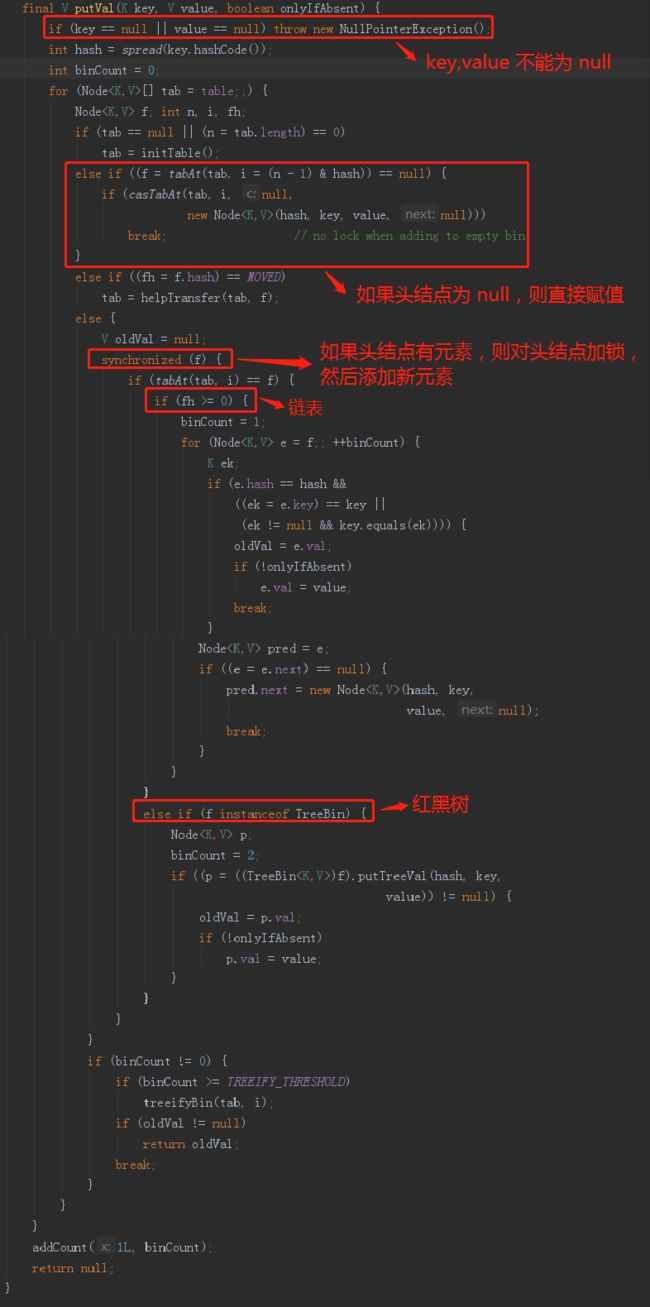
1、获取 key 的 hash值,找到数组下标。
2、如果数组为空,进行数组初始化。
3、判断该数组第一个节点是否有数据,如果没有数据,则使用CAS操作将这个新值插入,如果有数据,则进入第四步。
4、对头结点进行加锁(synchronized),如果头结点的 hash 值>=0,说明是链表,遍历链表,如果找到相等的key,则进行覆盖,如果没有找到相等的key,则将新值放到链表的最后面;如果 hash 值 <0,说明是红黑树,调用红黑树的插值方法插入新节点。
5、插值完成之后,判断链表元素是否达到临界值(8),那么就会进行红黑树转换。注意:当数组长度小于64时,即使达到临界值也不会进行红黑树转换,而是进行数组扩容(Java8 HashMap没有此限制,直接判断临界值即可)。
初始化数组:initTable
初始化方法中的并发问题是通过对 sizeCtl 进行一个CAS 操作来控制的。

get 过程分析

1、计算 hash值
2、根据 hash 值找到数组对应的位置:hash & (n- 1)
3.根据该位置处头节点的性质进行查找:
1)如果该位置为 null,那么直接返回 null 就可以了
2)如果该位置处的节点刚好就是我们需要的,返回该节点的值即可
3)如果该位置节点的 hash 值小于 0,说明正在扩容,或者是红黑树,后面调用 find 接口,程序会根据上下文执行具体的方法。
4)如果以上 3 条都不满足,那就是链表,进行遍历比对即可
总结
HashMap 是允许 key为null值的,并且将其保存在数组第一个元素 table[0]上;而 ConcurrentHashMap 是不允许 key 为 null的。
LinkedHashMap 是默认根据元素增加的先后顺序进行排序,而 TreeMap(底层二叉树) 则默认根据元素的 Key 进行自然排序(即从小到大),也可以指定排序的比较器。
LinkedHashMap 的构造方法也支持 accessOrder 参数,如果为 true,则表示采用最近最少使用算法(LRU)进行排序。大致原理为:
put(key, value),首先在 HashMap 找到 Key 对应的节点,如果节点存在,更新节点的值,并把这个节点移动队尾。如果不存在,需要构造新的节点,并且尝试把节点塞到队尾,如果 LRU 空间不足(HashMap 由于可以扩容,故不存在这种情况),则通过淘汰掉队首的节点,同时在 HashMap 中移除 Key。
get(key),通过 HashMap 找到 LRU 链表节点,因为根据LRU 原理,这个节点是最新访问的,所以要把节点插入到队尾,然后返回缓存的值。
HashTable:线程安全的,但是由于采用的是synchronized来保证线程安全,效率非常低,因为当一个线程访问HashTable的同步方法时,其他线程访问会进入阻塞或轮询的状态。
二叉树:二叉树规定了在每个节点下最多只能拥有两个子节点,一左一右。
二叉查找树:二叉查找树的左子树中任意节点的值都小于右子树中任意节点的值。
平衡二叉树:又称为AVL树,它要求左右子树的高度差的绝对值不能大于1,红黑树就是一种平衡二叉树。
彩蛋
HashSet 的工作原理:
HashSet 的底层还是 HashMap:

对于 HashSet 而言,它是基于 HashMap 实现的,HashSet 底层使用 HashMap 来保存所有元素,因此 HashSet 的实现比较简单,相关 HashSet 的操作,基本上都是直接调用底层 HashMap 的相关方法来完成,我们应该为保存到 HashSet 中的对象覆盖 hashCode() 和 equals()。
add 方法:
public boolean add(E e) {
return map.put(e, PRESENT)==null;
}
可知,HashSet 中的 value 都是 PRESENT,其是 Object 对象。当元素 e 在 map 中不存在时, map.put(e, PRESENT) 方法返回 null,即 add 返回 true;如果元素 e 在 map 中已经存在,map.put(e, PRESENT) 方法返回不为 null,即 add 返回 false。从而保证了 set 中元素的不可重复性。